This is a guest post, written by Sumit Arora, Lead Big Data Architect at Pearson, and Asgar Ali, Senior Architect at Happiest Minds Technologies Pvt., Ltd.
About Pearson
Pearson is the world’s leading learning company, with 40,000 employees in more than 80 countries working to help people of all ages to make measurable progress in their lives through learning. Visit www.pearson.com for more information.
Data Lake at Pearson
An initiative to build a data lake at Pearson for housing a wide range of data is currently underway. This data lake will contain different varieties of data ranging from product activity to operational data, including sales/registrations, survey results, etc. It will act as a research environment for Data Scientists and Analysts to query, investigate and mine the information in one location. Apart from this, it will also enable organizational reporting for business intelligence, product efficacy analytics, and content analytics.
What was the Ask?
In order to fulfill the research needs of data scientists and analysts, it is necessary that the system provides the ability to run ad hoc interactive queries and supports ODBC/JDBC interfaces to integrate with products like R and Tableau (or other visualization tools). It was, therefore, important to evaluate various interactive query solutions and select a framework that fulfilled our requirements. This not only required us to evaluate the SQL execution engine but also the underlying file format which is optimal for our needs.
Evaluation Approach
There are many interactive query solutions available in the big data ecosystem. Some of these are proprietary solutions (like Amazon Redshift) while others are open source (Spark SQL, Presto, Impala, etc). Similarly, there are a number of file formats to choose from – Parquet, Avro, ORC, etc. We “theoretically” evaluated five of these products (Redshift, Spark SQL, Impala, Presto, and H20) based on the documentation/feedback available on the web and decided to shortlist two of them (Presto and Spark SQL) for further evaluation. Some of the reasons behind this decision of ours were:
- Redshift requires data to be moved out of S3 into its own format and we didn’t want to have this extra step in our processing pipeline. Apart from this, it is a proprietary technology and we wanted to keep open source technologies in our stack.
- Impala doesn’t support complex data types and querying data on S3
We also decided to test Spark SQL and Presto on four different file formats – Plain Text without compression, Avro with Snappy compression, Parquet with Snappy compression, and ORC with Snappy compression. In order to fairly evaluate the two candidates, we decided to deploy both of them on the same Yarn cluster and use the same data set and queries for evaluation purposes.
Spark SQL and Presto can both connect to Hive metastore and query tables defined in Hive, so we decided to create and load tables in Hive and then query them from Spark SQL and Presto. It is also a best practice to partition tables in Hive for limiting the data set used by a query, so we partitioned the Hive tables by year, month, and day.
Data Set and Queries
It was very important to select the correct data set and queries for evaluation to ensure that we are testing real-world use cases of Pearson. We used six domain entities for our tests and created Hive tables for each one of them. Our queries ranged from a single table, needle in a haystack queries with ‘like’, ‘order by’, and ‘where’ clauses to complex table joins with ‘order by’ and ‘where’ clauses. We also ran aggregation queries using ‘count’, ‘sum’, and ‘average’ functions.
The total dataset was 6.05 terabytes split between Plain Text, Avro, Parquet, and ORC formats and we partitioned the data using date-based partitions.
Environment details
We used Amazon EMR as our Hadoop distribution and installed Spark and Presto on a Yarn cluster.
Following are the environment details:
Instance type r3.xlarge (30.5 GB Memory, 4 cores, 80 GB SSD storage, 500 Mbps I/O performance) Num of Master nodes 1 Num of Core nodes 10 Java version Java 7 (except for Presto) AMI version 3.3.2 Hadoop distribution Amazon 2.4.0 Hive version 0.13.1 Presto version 0.89 (This required Java 8) Spark SQL version 1.2.1
We also tuned some memory/configuration settings to ensure that Spark SQL and Presto are allocated the same amount of memory. Spark SQL’s thrift server was started with 10 Spark executors with 10 GB memory allocated to each executor. We installed 10 Presto worker nodes and set task.max-memory to 10 GB for each one of them. We also made sure that both Spark SQL and Presto use the same PermSize, MaxPermSize, and ReservedCodeCacheSize JVM settings.
Results
Scalability
We tried our queries with a smaller data set and on a smaller cluster first and then scaled the environment out by creating a bigger cluster and increasing the size of the data set. We found that both Presto and Spark SQL scaled pretty well except for a few minor hiccups:
- Some of the join and aggregation queries on very large tables failed in Presto with a “Java heap space” error. This also killed multiple nodes in the Presto cluster. It is interesting to note that these queries didn’t fail on Spark SQL, however, they took a very long time to return results.
- Some join queries failed on Spark SQL with a “buffer overflow” error.
Availability
Both Presto and Spark SQL remained highly available during our tests. There were instances when some of the nodes in the cluster either died (a join query on Presto killed multiple nodes) or weren’t added to the cluster (in one instance, only 9 out of 10 Spark SQL nodes were active in the cluster due to memory limitations). However, the queries were getting executed even if there is one worker node active in the cluster.
Performance
This was one of the most important criteria for our evaluation. The performance of a SQL engine also depends on the underlying file format in which the data is stored, so we tested our queries on Text, Avro, Parquet, and ORC formats. This required creation of Hive tables which store data in the desired file format.
On EMR we found that the ORC format has serious performance issues if the files reside on S3, so we did not execute all the queries on ORC tables and also excluded ORC format from further evaluation. These issues were reported to AWS and they are investigating. It is interesting to note that the same queries work fine (in fact, they run much faster than other file formats) when tables are backed by ORC files on HDFS.
Since completing our evaluation on EMR, we were delighted to learn that Qubole had already fixed the problems with using ORC on S3. In fact, Qubole suggests using ORC as a Presto best practice. We also learned that Qubole has committed their fixes back to the open-source Presto project. Qubole has further extended Presto to include the ability to cache data and metadata.
The following graphs provide more insights into the results:
The X-Axis represents the Query-Type and Y-Axis shows the time taken in seconds
Simple Query comparative results:
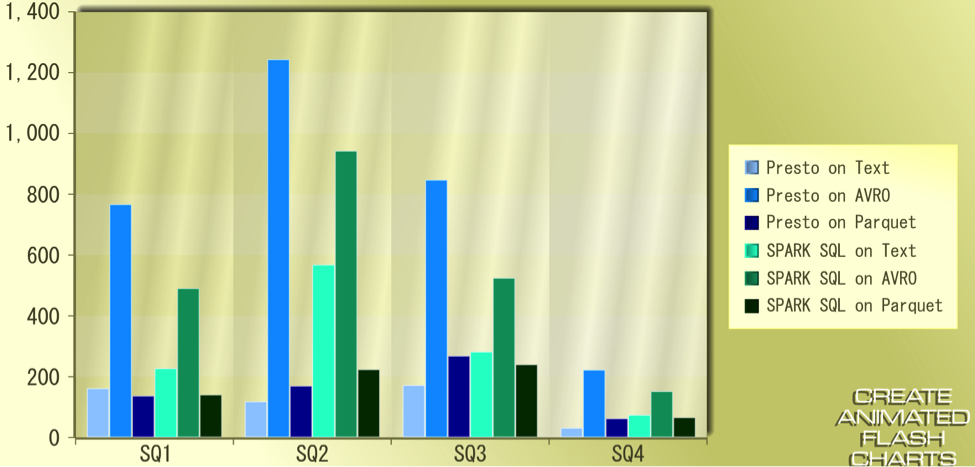
Join Query comparative results:
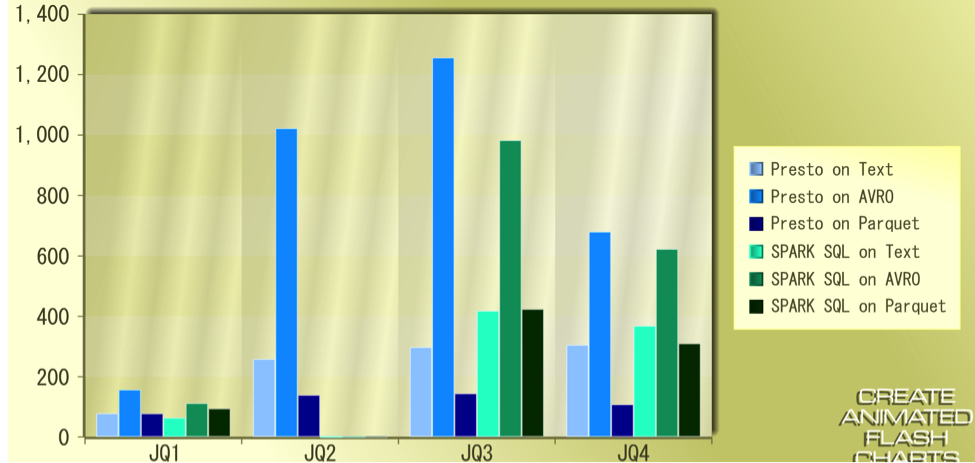
Aggregate Query comparative results:
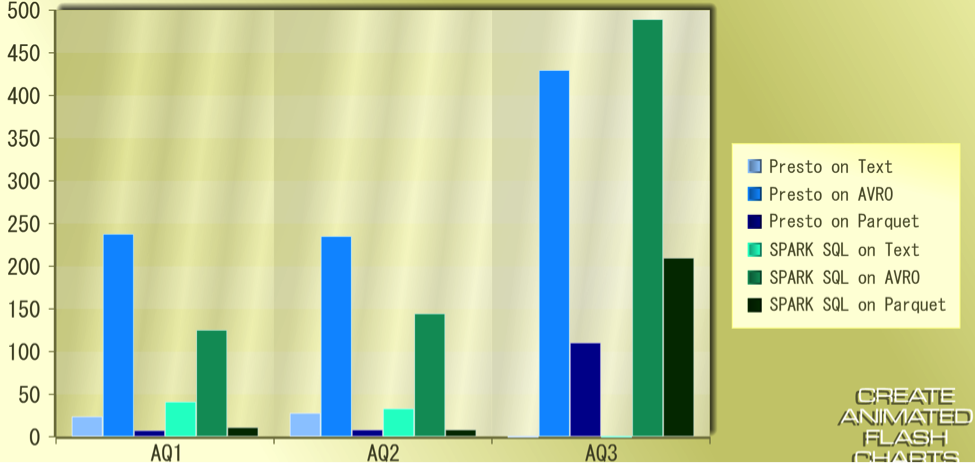
Compression
Compression is a very important feature for saving storage costs on S3, so we compared how well different file formats compress on S3:
The X-Axis represents different entities and Y-Axis shows percentage compression
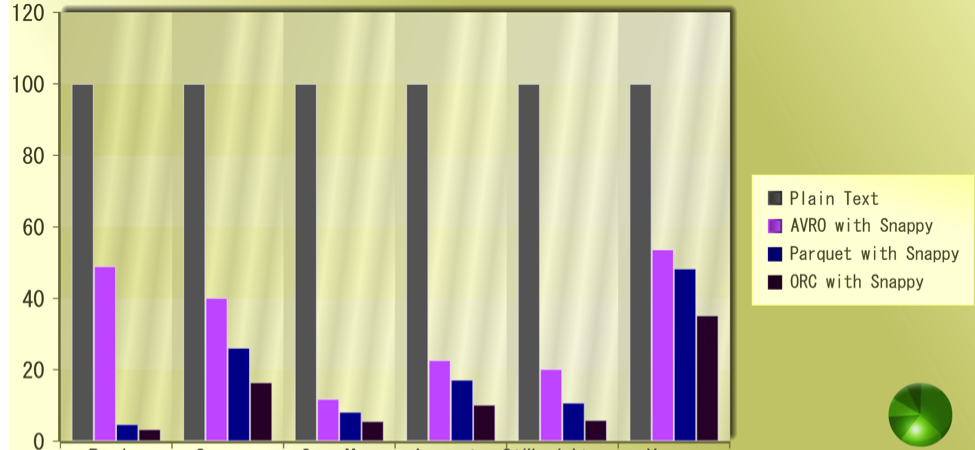
Schema Evolution Capabilities (Using Hive Metastore)
Our data lake entities will evolve as we add more data sources and identify more use cases in the future. Therefore, we should be able to change the schema definition with minimal impact on components involved in the system. This can be accomplished in several ways; however, we decided to use Hive metastore for schema evolution. Following are the results:
| File Format | Type of evolution | HIVE | PRESTO | SPARK SQL |
| TSV | Add column | PARTIALLY PASSED* | PARTIALLY PASSED* | PARTIALLY PASSED* |
| TSV | Drop column | PARTIALLY PASSED* | PARTIALLY PASSED* | PARTIALLY PASSED* |
| TSV | Rename column | PASSED | PASSED | FAILED |
| TSV | Change datatype | PASSED | PASSED | PASSED |
| Avro | Add column | PASSED | PASSED | PASSED |
| Avro | Drop column | PASSED | PASSED | PASSED |
| Avro | Rename column | PARTIALLY PASSED* | PARTIALLY PASSED* | PARTIALLY PASSED* |
| Avro | Change datatype | PARTIALLY PASSED* | PARTIALLY PASSED* | PARTIALLY PASSED* |
| Parquet | Add column | PASSED | FAILED | PASSED |
| Parquet | Drop column | PASSED | PASSED | PASSED |
| Parquet | Rename column | PARTIALLY PASSED* | FAILED | PARTIALLY PASSED* |
| Parquet | Change datatype | FAILED | PASSED | FAILED |
| ORC | Add column | PARTIALLY PASSED* | PARTIALLY PASSED* | PARTIALLY PASSED* |
| ORC | Drop column | PARTIALLY PASSED* | PARTIALLY PASSED* | PARTIALLY PASSED* |
| ORC | Rename column | PASSED | PASSED | PASSED |
| ORC | Change datatype | FAILED | PARTIALLY PASSED*** | FAILED |
* Newly added or deleted column should be the last one
** Can’t read column values written with old column name but works fine for new files
*** Works only if the new data type is compatible with the old type e.g. INT to LONG
Support for Complex Data Types
Spark SQL
Avro (records) Parquet (Row) STRUCT Queryable Queryable ARRAY Queryable Queryable* MAP Queryable Queryable ARRAY OF STRUCT Queryable Queryable*
This requires the following settings in Spark SQL
set spark.sql.parquet.useDataSourceApi=false
set spark.sql.hive.convertMetastoreParquet=false
It is being tracked at https://issues.apache.org/jira/browse/SPARK-5508
Presto
Avro (records) Parquet (Row) STRUCT Queryable Queryable ARRAY Queryable Queryable* MAP Queryable Queryable ARRAY OF STRUCT Queryable Queryable*
Other considerations
We also evaluated these two tools on several other criteria like JDBC/ODBC support, vendor lock-in, ANSI SQL support, maturity, Amazon S3 support, and future direction.
Summary of results
Based on our tests, it is clear that the Parquet file format is the optimal choice for storing data. It doesn’t compress as well as ORC but is still better than Avro or Plain Text. ORC doesn’t fulfill our requirements for schema evolution and S3 support. Similarly, although Avro scores better than Parquet on schema evolution, the performance of queries on Avro is dismal.
The following table summarizes the results for Spark SQL and Presto:
1: Poor, 2: Fair, 3: Average, 4: Very Good, 5: Excellent
Weight Spark SQL Presto Scalability 4 4 4 Availability 4 4 4 Latency 5 3.5 4 Total Cost of Ownership 4 4 4 Maturity 3 3.5 2.5 3rd Party Support 3 5 3 S3 Support 3 4 4 Support for Complex Data Types 5 4 2 ANSI SQL Support 3 3 3.5 Additional Interfaces Support 3 4 4 Vendor Lock-in 3 5 4 Future Direction 4 5 4 Schema Evolution 4 4 1 Weighted Average 4.06 3.35
Based on this evaluation, we selected Spark SQL as the execution engine with Parquet as the underlying file format for our data lake.
Pearson has decided to use Qubole as the platform to move forward and build our production applications on. The rationale behind this decision was because Qubole was able to meet other key requirements of this project, including the following:
Customized VPC Support. We specify a custom domain name in the DHCP options. By default, this was making the hostnames unresolvable, which is a requirement for Hadoop 2 daemons. Fortunately, Qubole was able to solve this problem by dynamically updating the resolver configuration file.
Auto-scaling Spark Clusters. Qubole’s Spark clusters automatically scale up and down based on volume. Given our usage pattern, this feature will help drive efficient EC2 utilization.
Built-in Spark SQL Query UI. Out of the box, Qubole offers multiple ways to interact with Spark and Spark SQL: you can use the Analyze UI as well as the built-in interactive notebook. These are key for our users. The built-in UI gives users the ability to save queries and easy access to query results. Users can access results and logs from past query instances even if the cluster is down. Further, users can easily download the results locally. The integrated Zeppelin-based notebook is also great for various data science use cases.
Tuning Per Query. Qubole runs Spark on Yarn with the ability to create new contexts (or use the same) per query. That has allowed us to tune job settings based on the query itself. This level of flexibility has proven to be beneficial.
Security. Security is very important for the use cases at Pearson. We deal with a lot of sensitive data. Out of the box, Qubole provides multiple layers of encryption as well as user authentication and authorization.
Monitoring and Auditing. Along with the built-in Query UI and Notebook, Qubole also has various interfaces for monitoring and auditing. There’s a per query history and an audit trail that can be searched, support for naming and tagging query instances, and useful metrics around usage and ability to break down per cluster, command, and user.
Familiarity: The standard Spark UI is built-in, along with built-in Ganglia and DFS UI for cluster-level metrics.



