Many companies start their big data cloud journey on Azure by testing Microsoft’s native offering HDInsight (HDI). With data already in Blob Storage or Azure Data Lake Store, HDI makes it easy to get started on projects.
For an experienced team in big data analytics and Machine Learning (ML), with data engineers, data scientists, and analysts on staff, configuring and tuning infrastructure on HDI can make sense. However, for most organizations, managing and tuning their big data infrastructure manually can quickly become a barrier to scaling beyond a departmental project or proof of concept.
The resources required to deliver big data analytics across and beyond the enterprise are particularly unpredictable since people demand instant access to information from multiple data sources through a self-service model. This means that you need separate configurations of various components to customize HDI to your specific use cases.
The resulting administrative overhead to maintaining the platform requires additional IT staff to keep it operational. This dependency turns IT into a bottleneck for end users’ productivity because every new project would require manual setup and maintenance of clusters and new infrastructure.
As projects mature to production or expand to different teams, and HDI platform requires constant support and revision. Software upgrades must be managed manually too. Costs can quickly accumulate because HDI does not have automated ways to scale clusters according to workload. Moreover, HDI doesn’t provide an easy way to save costs by downscaling computing capacity when idle or not required anymore, resulting in more manual work to delete clusters or keep them running 24×7.
A Different Approach to Activating Big Data on Azure
Qubole provides a cloud-native data platform for Artificial Intelligence (AI), Machine Learning (ML), and analytics that automates big data infrastructure management in the cloud. Our policy-driven workload-aware autoscaling and downscaling capabilities reduce setup, administration, and operational management overhead for big data. Qubole does not store your big data, but leverages Azure storage and compute, and automates infrastructure management on demand. The difference with the Qubole platform is that it learns from the different workloads to re-size clusters accordingly, and automates the start-up and shut-down of clusters based on usage and policy.
This type of automation enables the platform to scale in a very cost-effective way despite the bursty demands of big data analytics. By optimizing the number of compute nodes in a cluster, organizations can expand and shrink their infrastructure footprint in an agile manner and remove the need to maintain clusters 24/7, thereby reducing delays and waste. As implementations scale in time, these capabilities have a huge impact on the platform’s return on investment.
For example, an organization needs to run several data science workloads on HDI using R algorithms, but only wants to run the platform during working hours in one region for a maximum of 10 hours per day, 5 days per week. IT sets up the infrastructure consisting of a 50-node HDI cluster running on D4 v2 Azure VMs. They would also need to assign two administrators to manage the infrastructure and ensure that the cluster starts and stops at predetermined times.
In contrast, with Qubole an administrator defines a cluster policy that matches the same hardware specification but has the ability to auto-scale from a minimum number of 2 nodes to a maximum of 50 nodes. A data scientist submitting the first workload will trigger an automatic start-up of the infrastructure. Throughout the day the cluster will re-size automatically based on activity. By optimizing over the course of days, weeks, and months, Qubole ensures lower infrastructure costs, proving a return on investment that would otherwise be impossible without self-learning and automation.
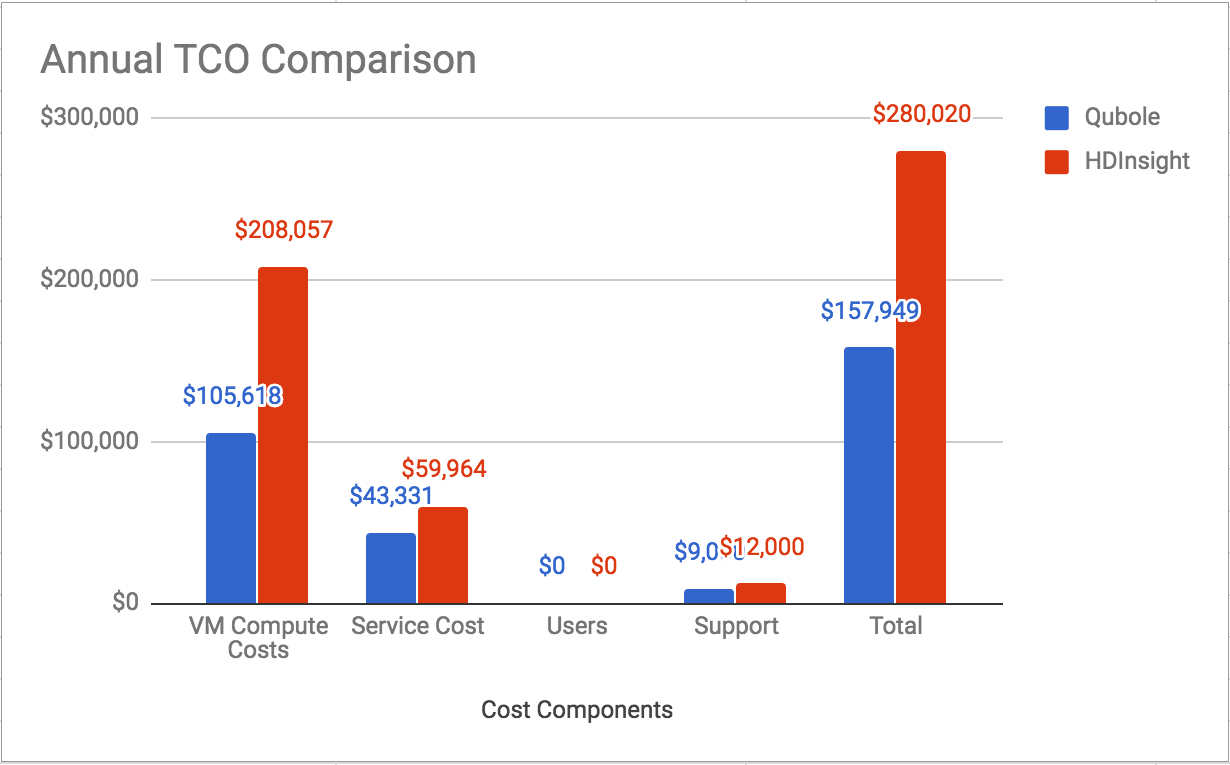
TCO Comparison
The chart below compares annual TCO for a 50-node cluster on Qubole versus HDInsight using D4 v2 Azure instances. By using sophisticated workload-aware autoscaling and cluster lifecycle management, Qubole delivers 52% lower TCO compared to HDInsight.
Performance Comparison
Performance is often another important factor to consider when choosing a big data activation platform. We used the industry-standard TPC-DS benchmark to compare the query performance of Qubole vs. HDInsight.
A summary of the results shows:
- Apache Spark on Qubole outperforms Apache Spark on HDInsight by over 40%
- Apache Hive on Qubole outperforms Apache Hive on HDInsight by about 17%
For the comparison, we ran a subset of TPC-DS queries as-is without any modifications. We measured end-to-end times for all queries, and not just query execution or run times. Below is the setup we used for the comparison.
Hardware configuration:
Machine type: 5 nodes of D14 v2
Number of CPU cores: 80 virtual cores
Memory (GB): 560 GB
Local Disk (TB): 4 TB
Dataset:
TPC-DS 1,000 scale factor on Azure blob storage for the Spark 2.1.1 comparison.
TPC-DS 1,000 scale factor on Azure Data Lake Store for the Hive 1.2 comparison.
Results:
As shown in the results below, Qubole delivers better performance due to sophisticated auto-scaling capabilities and advanced optimizations we have built on top of open-source engines like Apache Spark and Hive.
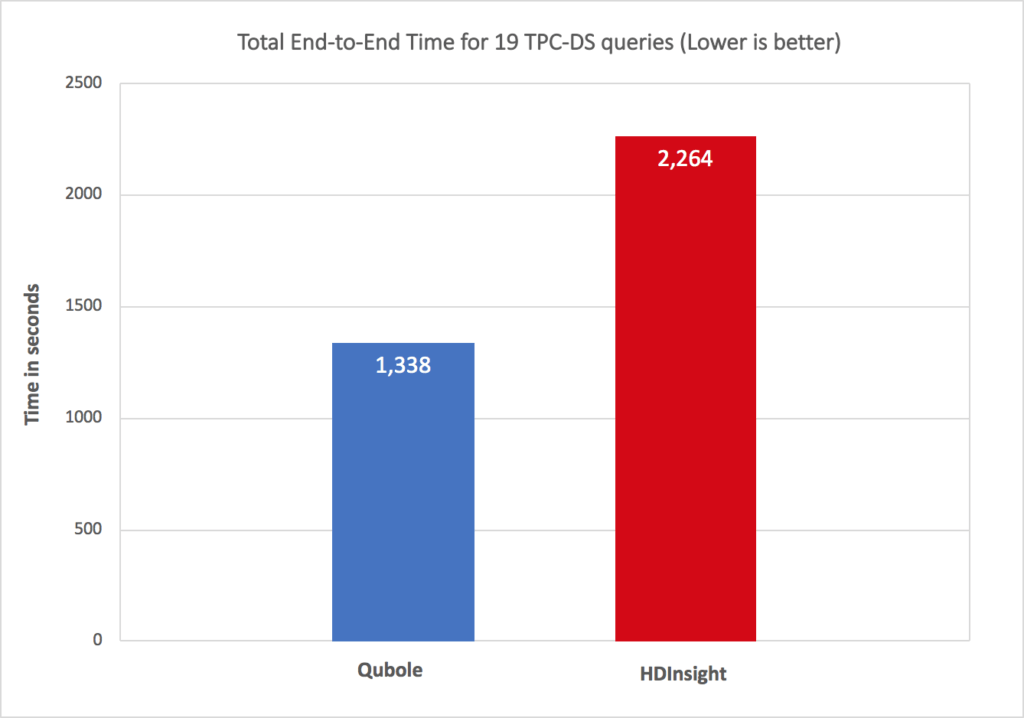
- Apache Spark 2.1.1 comparison:
The chart below compares total query times for 19 queries on Apache Spark 2.1.1 on Qubole vs. HDInsights. Qubole delivers 40% better performance on total query times and up to 60% better performance for a few queries.

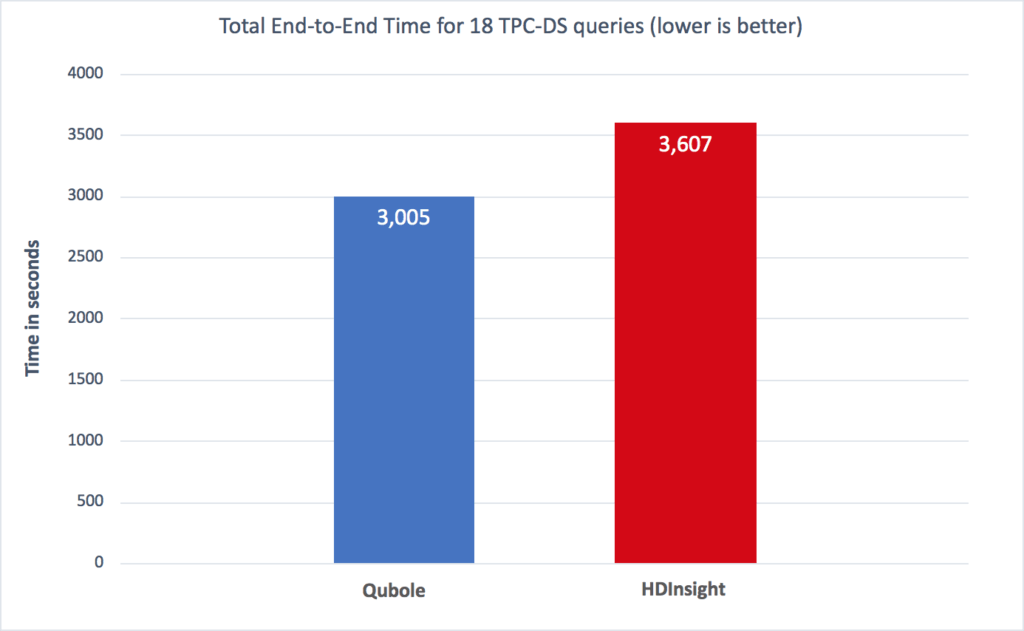
- Apache Hive 1.2 comparison:
The chart below compares total query times for 18 queries on Apache Hive 1.2 on Qubole vs. HDInsights. Qubole delivers 17% better performance on total query times across 18 queries and up to 40% better performance for a few queries.
Collaboration and Productivity
An organization investing in big data will have multiple user types running diverse big data workloads. For example, data engineers create data pipelines for data analysts running business intelligence queries or data scientists running machine learning algorithms. Qubole provides a single environment for each of these user types to access the same data and work together through a common interface. The ability to share queries, troubleshoot issues, and use common BI tools such as Power BI or Tableau accelerates team productivity. Qubole offers multiple productivity interfaces within the platform:
- Notebooks: Unlike HDInsight, which uses a Livy server integration for notebooks, Qubole notebooks are natively integrated with Apache Spark. This delivers better multi-tenancy for notebooks. Additionally, we have built sophisticated capabilities such as offline viewing, auto-saving to cloud storage, scheduling of notebooks as jobs, dashboards, collaboration, and Access Control Lists (ACLs) for Qubole notebooks.
- Analyst workbench: Qubole offers a native analyst workbench within the platform with query history and searches that allow multiple users to easily collaborate.
- Workflow: Qubole offers built-in scheduling and workflow, in addition, to supporting Apache Airflow.
- Qubole Presto and Power BI: This powerful combination enables businesses to run self-service federated ANSI SQL queries from unstructured, semi-structured, and structured data sources for reports, visualizations, mashups, and powerful dashboards published in the Power BI Service. Qubole Presto is the only Presto distribution on the market that delivers advanced optimizations, caching, auditing, a query cost model, and workload-aware autoscaling, in a single platform, offering the best cloud-native performance and lowest operational costs. With Qubole Presto users are no longer constrained by a single big data source or by the latency of local query processing against vast amounts of big data, dramatically improving workload efficiency and reducing cost.
Conclusion
Most enterprises lack the deep experience to manage big data at scale on Azure. Qubole provides the automation, scale, cost reduction, performance, and self-service data access that allows enterprises to activate their big data. Qubole takes care of upgrading open source technology seamlessly, so your IT team can focus on other more productive tasks and ensure the right ROI for your big data platform implementations.
Test drive Qubole for free today to get started from one of our seasoned experts.


