One of the oft-discussed problems with Hadoop is that it launches new JVMs for each map or reduce task. Launching a new JVM and loading all the classes is pretty expensive and can take anywhere from 4-8 seconds. If the job is a small one, this startup overhead can be a substantial part of the overall execution time.
Hadoop does allow the reuse of JVMs between tasks within a job by setting themapred.job.reuse.jvm.numtasks parameter to -1. However, this is not very useful for the case where there is a single wave of mappers and reducers in a job as there is no opportunity to reuse JVMs within the job.
The solution was fairly obvious: Why don’t we keep warm JVMs around to eliminate this cost? This is not too different, in principle, from the Qubole Hive Server exercise. Once again, it was a matter of some code hygiene to ensure that a warm JVM doesn’t keep any state across Hadoop jobs that might cause problems. A couple of areas that required special attention were:
- The working directory of a JVM cannot be changed once it has started. Hadoop and Hive have certain semantics about adding files to the distributed cache that should appear in the current working directory of the JVM when a map or reduce task runs. We had to rework some of this logic so that these semantics were maintained.
- Some data structures had internal caches which would contain references to Configuration objects. E.g. FileSystem has an internal cache. These references did not allow garbage collection of class definitions leading to out-of-Perm Gen errors. We had to fix some of these cases.
Another detail is that the map and reduce classes and jars should be well-behaved and not have any static references. Some frameworks try to cache certain data structures e.g. Hive caching query plans to avoid repeated deserialization. We had to fix Hive to avoid such problems.
So, what’s the net effect of this exercise? We took a very small table with only 25 rows from the TPC-H dataset and executed this query.
1 | SELECT count(*) FROM nation
|
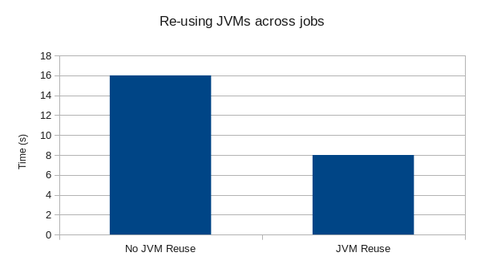
We measured the time with and without JVM reuse across jobs and found that we’d shaved off about 8 seconds from the overall execution time which made this query go 2x faster. This is not really in the interactive range but is a reasonable improvement over earlier numbers. JVM reuse across jobs is especially useful when the input data is small, but the Hive query is complex resulting in lots of tiny jobs. This is especially true during query authoring on test datasets.
We’re successfully reusing JVMs across jobs for Hive queries, Cascading jobs, and a number of custom Hadoop jobs in production workloads for over 6 months at Qubole. If working on these sorts of things interests you, please send us a note at [email protected]!



