Presto is a distributed ANSI SQL engine for processing big data ad hoc queries at tremendous speed and scale. The engine is used to run fast interactive analytics on federated data sources such as SQL Server, Azure SQL Database, Azure SQL Data Warehouse, MySQL, Postgres, Cassandra, MongoDB, Kafka, Hive (HDFS, Cloud Object Stores), etc. Presto is based on an MPP (massively parallel processing) design that executes queries in a highly concurrent fashion to achieve maximum throughput and speed with the available resources. Because of this design, Presto is widely used for ad hoc queries, exploratory analytics, reporting, and dashboards.
Qubole offers Presto-as-a-service on Microsoft Azure to handle petabytes of data. The Qubole Presto distribution provides self-service, improved performance, security, and cost optimization on Azure. Key capabilities include:
- Cluster Management: Autoscaling, Auto-start, and Auto-terminate
- Improved Performance: Join optimizations like dynamic filtering and join reordering, integration with Cache framework: Rubix
- Ad hoc queries: Self-service UI including SQL workbench, Notebook, Qubole JDBC, and ODBC drivers to connect to BI tools
- Security: Internode SSL, Qubole ACLs, HIPAA compliance
Qubole Presto Connector for Power BI
Microsoft Power BI is a widely used business analytics solution for data visualizations and reporting in two modes: Import mode and DirectQuery mode. Import mode requires data to be imported into Power BI and which can present latency limitations when working with big data sets greater than 1GB. In contrast, DirectQuery mode allows users to query data in place without replicating it to the Power BI client. However, it is limited to querying a single source at a time. Qubole’s Presto connector removes this limitation from Power BI in DirectQuery mode by allowing users to run queries from multiple data sources, whether stored in an Azure data lake or on compatible databases.
Qubole’s Presto connector for Power BI allows end-users to authenticate securely via an API token to a Presto cluster running in the customer’s Azure tenant. Qubole’s Presto engine provides visibility to all available data catalogs that have been configured. This can include data in a data lake, relational databases such as SQL Server, NoSQL databases such as Cosmos DB, and real-time data streaming applications such as Kafka. Using Qubole’s connector, Power BI users can now select tables across any of these catalogs and create and execute DAX queries across these different data sources for reporting, data exploration, and ad hoc analytics. Reports and dashboards can be published to the app.powerbi.com cloud service and shared with a broader audience within your organization for downstream consumption and collaboration.
Sample Use Case
Let’s look at an example where you can use Power BI with Qubole’s workload-aware autoscaling Presto cluster on Microsoft Azure to address a common business problem in retail and eCommerce. This involves understanding what products consumers are buying in order to make real-time online recommendations, or determine product marketing and buying decisions. Business and marketing teams can also find it helpful to know which products are most commonly purchased together, with use cases such as:
- Optimize marketing campaigns
- Bundle components or products together to generate a stronger engagement rate
- Understand interaction and product correlation data
- Increase sales of less viewed products.
- Recover revenue for a product that is getting a lot of engagement but not conversions
This exercise walks through various stages of a typical data exploration lifecycle with disparate data sources.
- Section 1. Data Exploration on structured and unstructured data with Presto
- Section 2. Advanced Analytics for analyzing newly enriched data from Apache Spark ML job to gain further business insights
Before we start with the analysis, first we will use Qubole’s custom connector for Presto in DirectQuery mode from Hive and MySQL into Power BI.
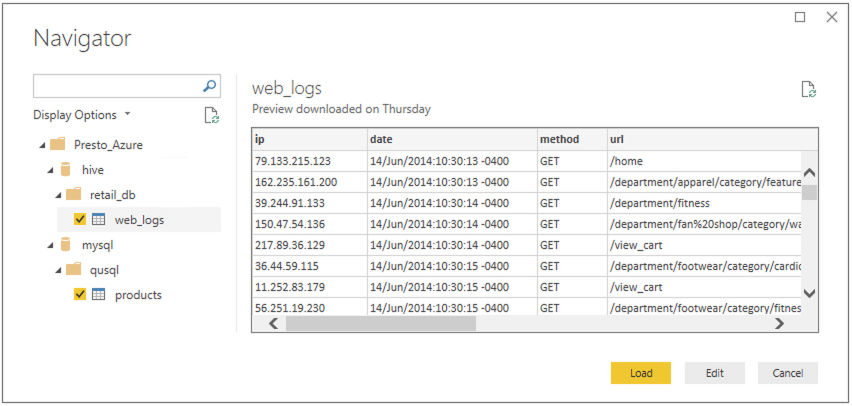
Once you have selected the DSN associated with your Qubole connection (in our case this is “Presto_Azure”), the available catalogs become visible in Power BI’s Navigator. Now, let us select the required tables for analysis. We have selected the web_logs table from Hive and the products table from MySQL:
The tables can then be loaded into Power BI and we can start analyzing the data.
Data Exploration
Step 1: Query the Weblogs from Azure Blob storage and the product dataset from MySQL.
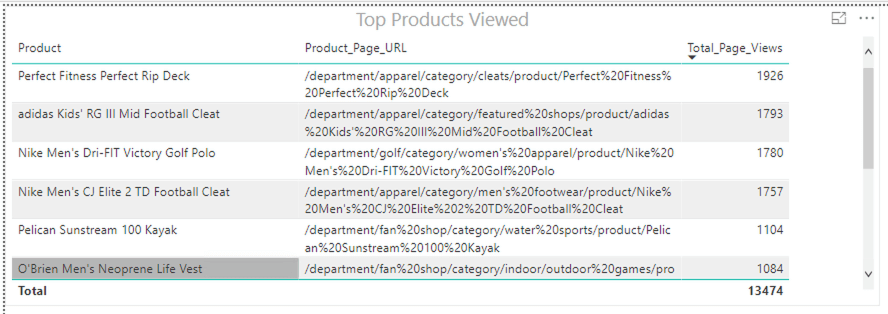
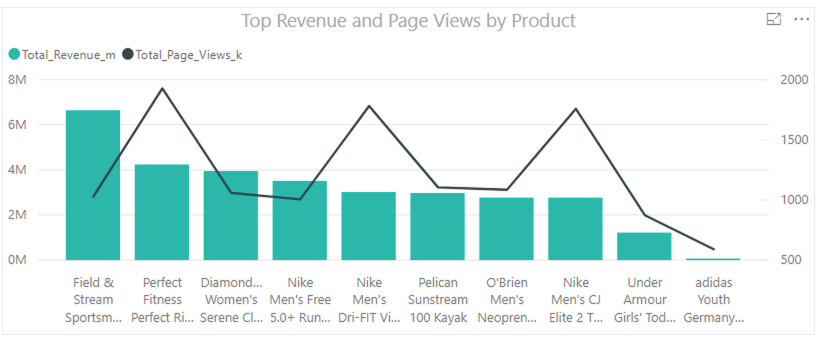
Now we can see the top products viewed on the website and the top revenue-generating products, but while there is a correlation, there is still an additional step needed to cleanly analyze this data together.
Step 2: Using Presto to join the weblogs and product data in a federated query.
This provides a correlation between top revenue-generating products and total page views. We can use this new dataset to run some other visualizations or ML modeling with other Big Data engines such as Spark.
Advanced Analytics
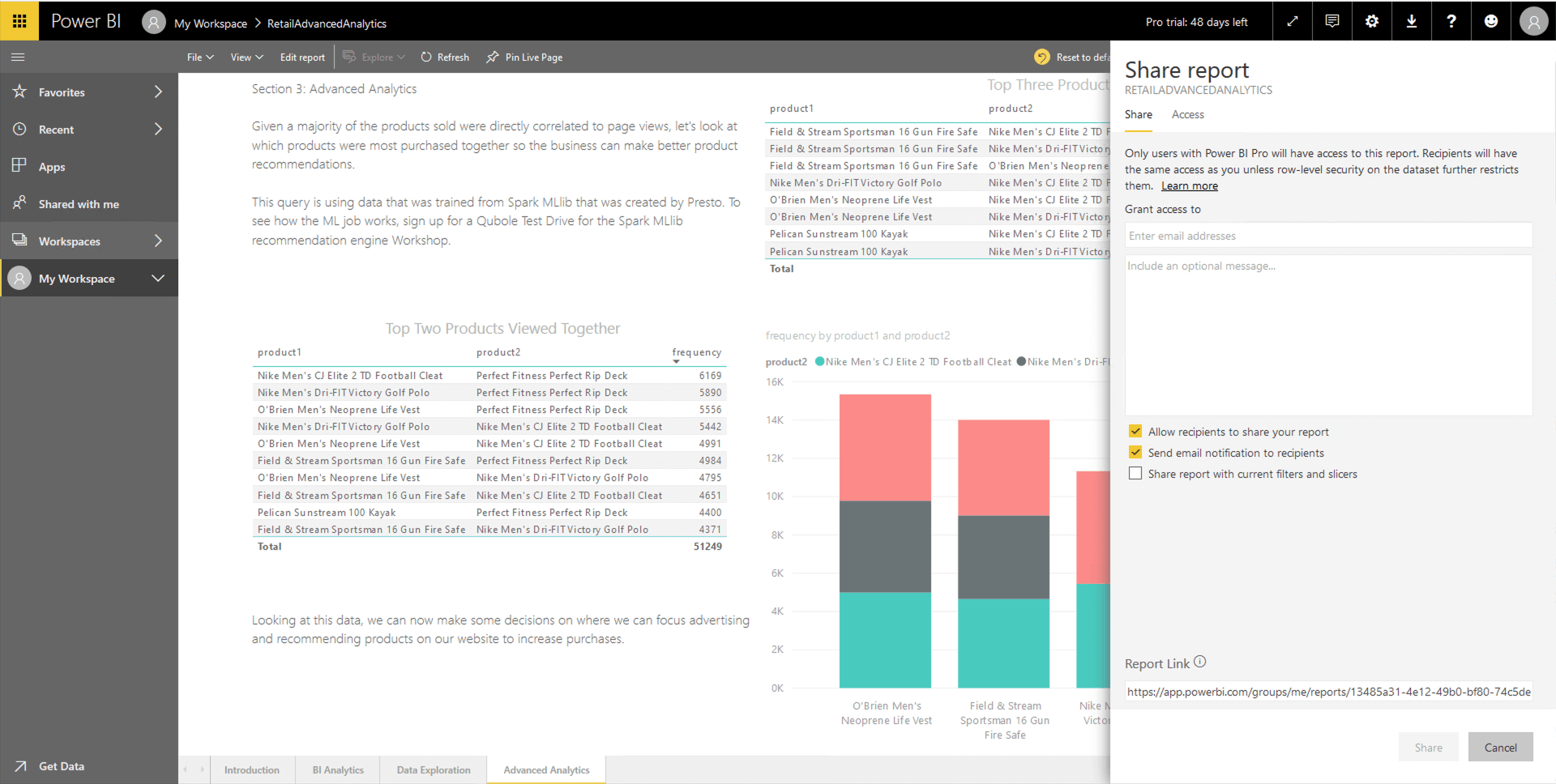
Given a majority of the products sold were directly correlated to page views, let’s look at which products were most purchased together so the business can make better product recommendations.
This query is using data that was trained by Spark MLlib in a separate process and saved back to the data lake and Hive. Presto is querying the results produced from that process.
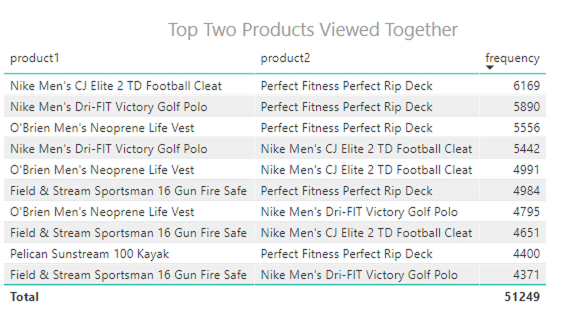
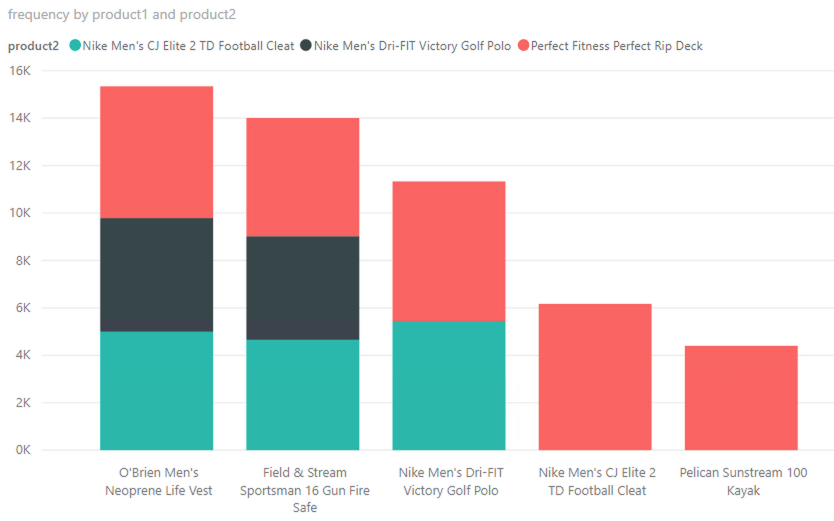
Looking at this data, we can now make some decisions on where we can focus advertising and recommending products on our website to increase purchases.
Publishing Reports to Power BI Online
On completion of our analysis and report building in Power BI Desktop, it’s now time to publish the report to Power BI online. This allows the dashboard to be shared with a wider audience within your organization and can easily be kept up-to-date since there is no data migration or manipulation needed because Presto reads the data directly from the source.