Qubole is the leading provider of Hadoop as a service. Our mission is to provide a simple, integrated, high-performance big data stack that businesses can use to derive actionable insights from their data sources quickly. Qubole Data Service (QDS) offers self-service and auto-scaling Hadoop in the cloud (patent pending) along with an integrated suite of data connectors and an easy-to-use GUI. We want our users to focus on their data, transformations, and collaboration while we take care of the infrastructure elements in processing data at scale. QDS is already available on Amazon AWS and Google Compute Engine (GCE) and late last year (2014) we started working on integrating with Microsoft’s Azure cloud service as it had started gaining significant ground since releasing its Infrastructure as a Service (IaaS) offering.
Based on our experience and what customers loved about Qubole, we outlined a list of technical goals to make our offering exciting to Azure users. A few of our most important goals to achieve were to:
- Provision clusters on-demand within minutes
- Auto-scale clusters according to load (this is unique to QDS)
- Support Hadoop, Hive, Pig, and Presto use-cases
- Shutdown clusters when idle to save costs
- Support efficient processing of large amounts of data from Azure blob store
- Connect to Microsoft SQL Servers and other DBs for extracting data
Qubole on Azure Architecture
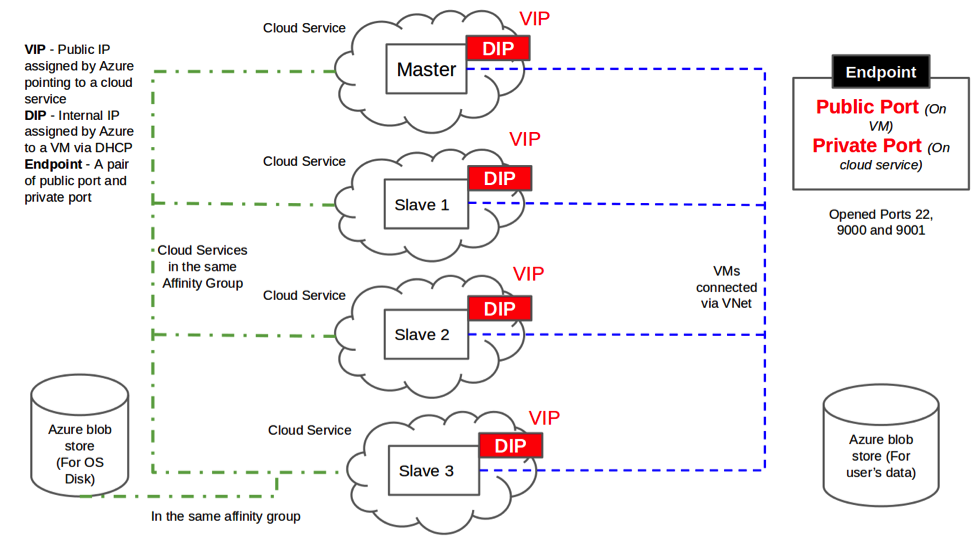 Qubole on Azure Architecture
Qubole on Azure Architecture
The above diagram depicts the high-level architecture of a Qubole Hadoop Cluster on Azure. A typical Hadoop cluster consists of one master and multiple slaves. These machines are launched in their own Azure cloud services. All the machines within the cluster are connected to a network that enables communication. The software to be installed within the clusters is pre-baked in an image and configured using a startup script. The data to be processed is read from the Azure blob store using storage credentials provided through the startup script.
This architecture enables Qubole on Azure to:
- Launch Hadoop nodes with auto-configured Qubole software
- Launch a large number of these Hadoop slaves in parallel
- Configure networking to make these nodes accessible to each other and to the outside world
Registering Images and Configuring Clusters
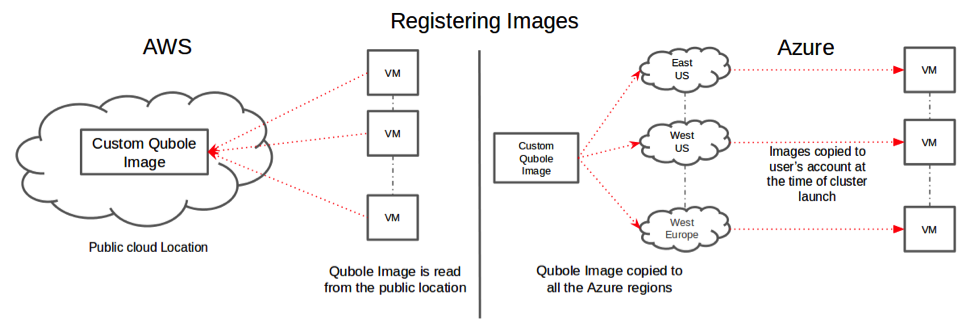
 Image registration on Azure
Image registration on Azure
All of Qubole’s software runs on Linux and we need the basic ability to create a machine image from a running VM. The above picture depicts how image registration is done in AWS vs. Azure. The ideal case is the ability to make these images public, which is what we do in AWS. In Azure, we used the custom Windows Azure agent on the VM to create the image from the VM. We then launch the VMs in the customer’s account using these images. However, in Azure, using a public image leads to conflict-related issues. 400 Bad Request errors were raised, and we brought this up with the Microsoft Support team. To get around this, we decided to copy our images to the customer’s account before launching the cluster. We also copied our images to every region that Azure supports, since the same region blob copy operation is faster than cross-region.
Once the customer’s cluster is up, Qubole needs to configure the cluster – to ensure the software is correctly set up and the Hadoop installation is up and running. Qubole passes in the parameters to the launched VM to customize the software and configure the VM. Although Azure had support for supplying custom data at the VM launch time, only Ubuntu VMs could actually make use of this file – due to cloud-init on them. For Qubole’s CentOS images, we had to figure out a way of decoding and running the startup script as the last step of VM boot-up. To achieve this, one more step was added to the /etc/rc.local script to decode and run the custom data.
Cloud Services and Azure Resource Limits
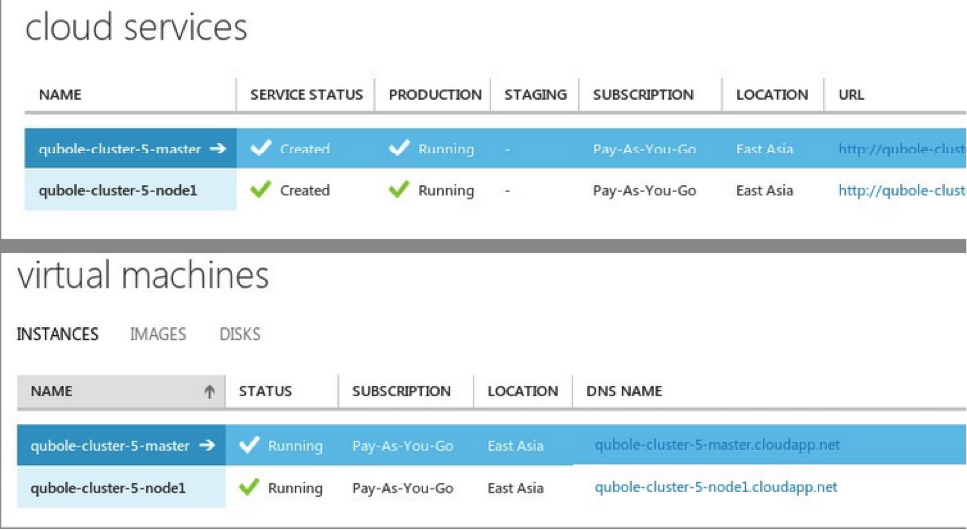
A Qubole Hadoop cluster on Azure
At Qubole, we strive to always have clusters available for customers within minutes while limiting idle time and its associated costs. For instance, on non-Azure clouds, we typically take a few minutes to bring up a 100+ node Hadoop cluster. The same SLA was desired for Azure. We figured, that if we had all nodes of a Hadoop cluster in a single cloud service they could automatically communicate using a private network channel with other VMs in the same cloud service – so there was no requirement of setting up an explicit Virtual Network. However, Azure seemed to use coarse locks when launching multiple VMs within a cloud service – thereby increasing provisioning time. Furthermore, there was a hard limit of 50 VMs per cloud service which limited the cluster size. To meet our requirement of bringing up large (100+ nodes) clusters quickly, we provision VMs in parallel across multiple cloud services connected by a VNet as shown in the architecture diagram.
Improving Cluster Launch Time
Continuing our efforts to decrease the overall time it takes to start a cluster, we wanted to parallelize numerous other operations. However, we saw global locks being acquired, and as a result, conflict errors were being raised at multiple places. Some examples of error messages were, “A concurrency error occurred while the service was attempting to acquire an exclusive lock on the blob”, and “The operation cannot be performed at this time because a conflicting operation is underway. Please retry later”. To get around these issues, we added many retries and sleep in between these retries to ensure that the operations would go through. We finally decided to launch multiple cloud services in parallel, containing one VM each, to bring down the cluster launch time.
Networking
Compute clusters launched by Qubole have a few networking requirements. For communication between the nodes in a Hadoop cluster, egress from and ingress to all the ports should be allowed using hostname/IP. In Azure, we do all the communications using the private IP between the VMs inside the same Hadoop cluster. This communication is enabled by the common Virtual Network to which all the VMs are connected. We saw a few issues here like – name resolution not working as desired, and assigning private IPs to the VMs was taking some time. We got in touch with the Microsoft Support team regarding some of these issues. A few of these were attributed to Azure DNS problems. With quick help from the MS Support team, we managed to get past most of these issues.
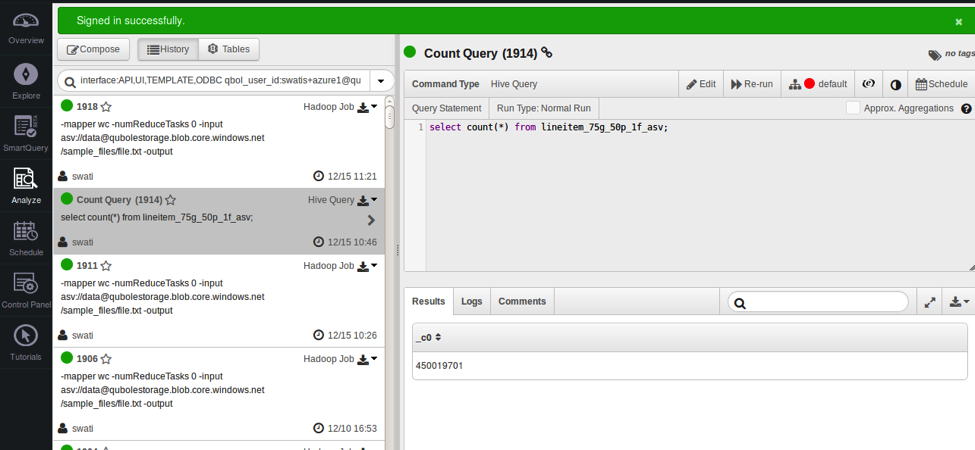

A hive query on Qubole on Azure
Eventually, with a few workarounds from our side and prompt help and support from the Microsoft team, we managed to accomplish our technical goals and circumvent the blockers. We are now generally available on Azure! Qubole typically takes around 6 mins to launch a 15 node Hadoop cluster. A few other things that we want to achieve in the near future are support for Hive13, Hadoop2, Spark, etc. Refer to the Azure quick-start guide and log on to Qubole to try out the first fully elastic Hadoop and Presto service on the Azure platform.



