Introduction
We previously wrote about the optimizations we made to optimize Hadoop and Hive on S3. Since then, we’ve applied those same changes across the rest of our Big Data analytics offerings, including Spark and Presto. Today, we’ll discuss some new recent optimizations we’ve made to further make querying of data performant and efficient for Qubole’s customers.
For most of our customers, an object storage service such as Amazon S3 is the source of truth for their data, rather than HDFS within the cluster. That’s because object storage services provide high scalability, durability, and storage security, all at low costs. Qubole users create external tables in a variety of formats against an S3 location. These tables can then be queried using the SQL-on-Hadoop Engines (Hive, Presto, and Spark SQL) offered by Qubole. In many cases, users can run jobs directly against objects in S3 (using file-oriented interfaces like MapReduce, Spark, and Cascading).
S3 versus conventional File Systems
One of the drawbacks of Amazon S3 is that individual calls to read/write or list the status of an object may have substantially more overhead than in conventional File Systems (including the Hadoop Distributed File System, or HDFS). This overhead is not significant when reading or writing large objects, but it can become significant if:
- The objects being read or written are very small.
- The operation being performed (for example getting the size of an object) are very fast/short.
However, Amazon S3 also has some unique features like prefix listing that conventional file systems do not offer.
Split Computation
Data in S3 is often arranged and partitioned by date or some other columns (e.g., country). This maps to a directory-like structure in S3 with sub-folders. It turns out that all the big data processing engines need information about the sizes of the objects to divide up the objects into smaller groups that can be worked on in parallel. This process is called split computation, and it is severely impacted by the high overhead of short operations in S3.
Example:
- Hourly logs for the last thousand days can result in 24000 directories.
- Listing 24000 S3 directories (each having only 1 file) sequentially takes around 1700 seconds.
- Parallelizing S3 listing has its own limitations as Amazon employs protection mechanisms against the high rate of API calls.
Therefore for certain workloads, split computation becomes a huge bottleneck.
Earlier work on Prefix Listing
We have talked about split computation and optimization done for listing S3 directories in our previous blog post. In essence, we took advantage of the prefix listing functionality of Amazon S3 to get the sizes of 1000 objects at a time. To re-summarize:
- Given an input S3 location, we would get the metadata of 1000 objects at a time under that location.
- This would present a dramatic reduction (1000x) in split computation time than the usual technique of listing all the objects and then fetching metadata for them individually.
However, our previous work did not address the case of multiple input locations well and none of the strategies worked well:
- If prefix listing was applied on each input location, then we would hit cases where there are thousands of input locations in a processing job (for example if thousands of partitions/directories are listed as inputs) and this would still result in slow split computation.
- If prefix listing was applied to the common prefix of all input locations, then there would be pathogenic cases where we would end up needlessly listing a dramatically larger number of objects.
- For example, s3:///a/b may be a common prefix of s3:///a/b/20120101 and s3:///a/b/20150101. But, listing s3:///a/b may force us to go through many years of objects, rather than just the two days in question.
Optimized Split Computation V2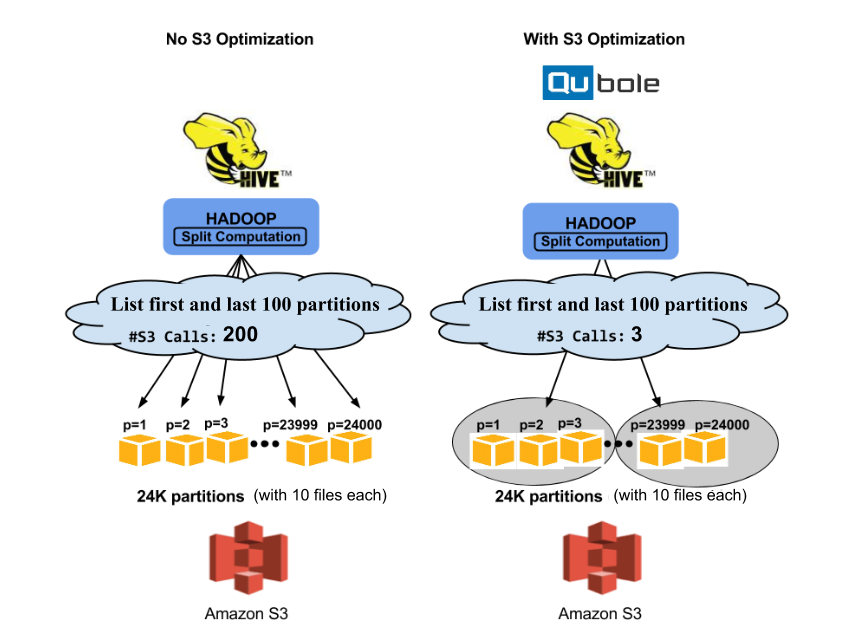 Figure 1
Figure 1
At Qubole, we decided to solve this problem as several customers were running into issues with listing multiple input locations and it was difficult for an analyst to figure out when the prefix listing optimizations were useful and when they were not.
We implemented the following algorithm to efficiently list multiple input locations:
- Given a list of S3 locations, apply prefix listing to a common prefix to get the metadata of 1000 objects at a time.
- While applying for prefix listing in the above step, skip those objects that do not fall under the input list of S3 locations to avoid ending up listing a large number of irrelevant objects in pathogenic cases.
To illustrate how we skip irrelevant objects while listing, let us consider an example in Figure 1 above. This shows a directory s3:///a/b with 24000 partitions (p in {1, 2 …24000}), each partition containing 10 objects. Let’s assume among them just the first 100 partitions and the last 100 partitions needs to be listed i.e., p <= 100, p >= 23900. Our algorithm would:
- Apply for prefix listing on the common prefix of these locations (e.g., s3:///a/b) and list 1000 objects at a time in chunks.
- The first chunk of 1000 objects would list all the objects under the first 100 partitions. As the first chunk contains relevant objects, the second chunk will be fetched listing all objects under the next 100 partitions.
- As the second chunk doesn’t list any object of our interest it will be skipped. If such a chunk is encountered then prefix listing would resume from the next yet to be listed input directory (using marker a parameter in prefix listing API). As the first 100 partitions have been listed by the first chunk, prefix listing would resume s3:///a/b/p=23900 skipping all the partitions in between p = 200 and p = 23900. Thus, the third chunk will list all objects under the last 100 partitions.
In our example, we showed how our algorithm took only three S3 API calls to list all the objects under the first 100 and last 100 partitions. It would have taken 66x more calls (200) for listing them individually and 80x more calls (240) for prefix listing on a common prefix (1000 objects at a time).
Other Applications of Optimized Listing in Hive
Apart from split computation, this optimization has been applied to 3 more utility functions in Hive which has significantly improved the performance of queries on S3:
org.apache.hadoop.hive.ql.exec.Utilities.getInputSummary()
- : It computes the summary for a list of S3 directory paths. A computed summary consists of a number of files, directories, and the total size of all the files.
org.apache.hadoop.hive.ql.exec.Utilities.getInputPaths()
- : It returns all input paths needed to compute the given MapWork. It needs to list every path to figure out if it is empty.
org.apache.hadoop.hive.ql.stats.StatUtils.getFileSizeForPartitions()
- : It finds a number of bytes on disks occupied by a list of partitions.
All the above functions are present in Apache Hive 0.13 from which Qubole’s distribution of Hive is derived (we also support Hive 1.2 in Beta).
Evaluation
For a comparative study, we benchmarked our findings for Hive queries that analyze an S3 directory with 24000 partitions, each having 1 file. We also ran a corresponding explanation Query for each one of them. We executed these queries on Qubole’s Hive which is derived from Apache Hive version 0.13. Details of the Hadoop cluster used are:
- Master Node: 1 m1.large instance (2 cores).
- Slave Node: 1 m1.xlarge instance (4 cores).
After creating table ‘multilevel_partitions’ that has 24000 partitions (20*20*60 i.e., first-level 20 partitions, second-level 20 partitions, and third-level 60 partitions) each having one file in it, we executed the following 2 queries:
- Q1: select a from multilevel_partitions limit 10
- Q2: select count(*) from multilevel_partitions
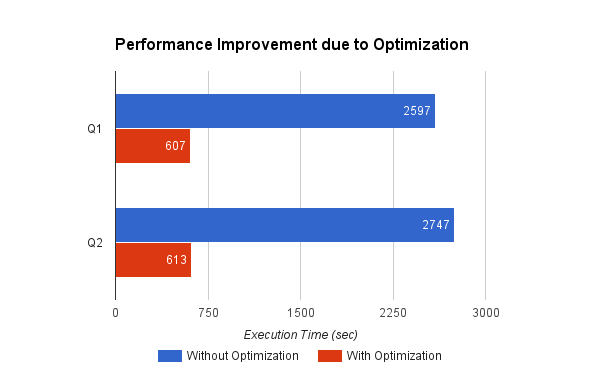
Figure 2
Figure 2 shows the performance speedup observed with our optimization. Performance speedup for queries was up to 4x. Both queries invoke Utilities.getInputPaths() directly without any cached result and end up listing S3 files sequentially one by one without using any threads.
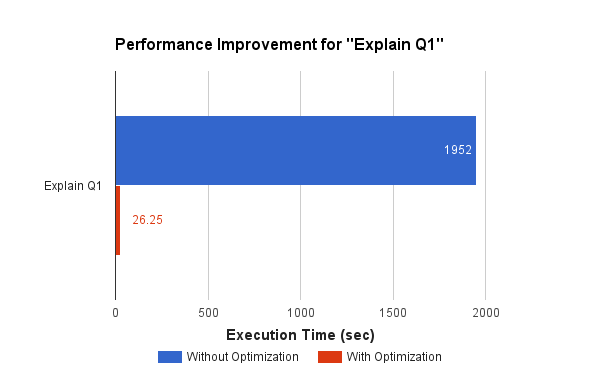
Figure 3
Figure 3 shows a performance speedup of 50X for Q1’s explain query. We saw a significant improvement in explaining queries because they invoked a utility function to find the bytes on disks occupied by a list of partitions: org.apache.hadoop.hive.ql.stats.StatUtils.getFileSizeForPartitions(). This utility function listed all the 24000 partitions sequentially without optimization. Optimization as shown in the diagram reduced it to a few seconds.
Conclusion
Qubole Data Service (QDS) comes with these S3 optimizations that have significantly improved the analysis of data stored in Amazon S3. These are just a few of the changes we have made so that data analysis is more efficient and performant for our users.
P.S. We are hiring and looking for great developers to help us build functionality like this and more. Drop us a line at [email protected] or check out our Careers page.



