With the advent of the cloud, data lakes built on the cloud-primarily use object storage like Amazon S3, Google Cloud Storage, Azure Blob Storage, etc. to store the data for analytical purposes. SQL-on-Hadoop engines like Apache Spark, Apache Hive, and Presto are all processing huge amounts of data stored in the cloud object stores. Cloud object stores are popular mainly because they are infinitely scalable, cheaper, and more fault-tolerant, though they add latencies to various traditional file system operations.
Amazon S3 Select is a service from Amazon S3 that supports the retrieval of a subset of data from the whole object based on the filters and columns used for file formats like CSV, JSON, etc. With this format, we would read only the necessary data, which can drastically cut down on the amount of network I/O required.
At Qubole, we are looking at various ways to improve the overall query time. We are happy to announce that Apache Spark on Qubole can now automatically use the S3 Select service whenever applicable to speed up queries (meaning there’s no need for an application code change).
Spark on Qubole – S3 Select integration
Apache Spark supports plugging in a new data source to the engine using an abstraction called Datasource. Using the Datasource abstraction, we built a new data source to integrate S3 Select with Spark on Qubole.
Spark on Qubole supports using S3 Select to read S3-backed tables created on top of CSV or JSON files. It can automatically convert existing CSV or JSON-based S3-backed tables to use S3 Select by pushing filters and columns used in the user’s query.
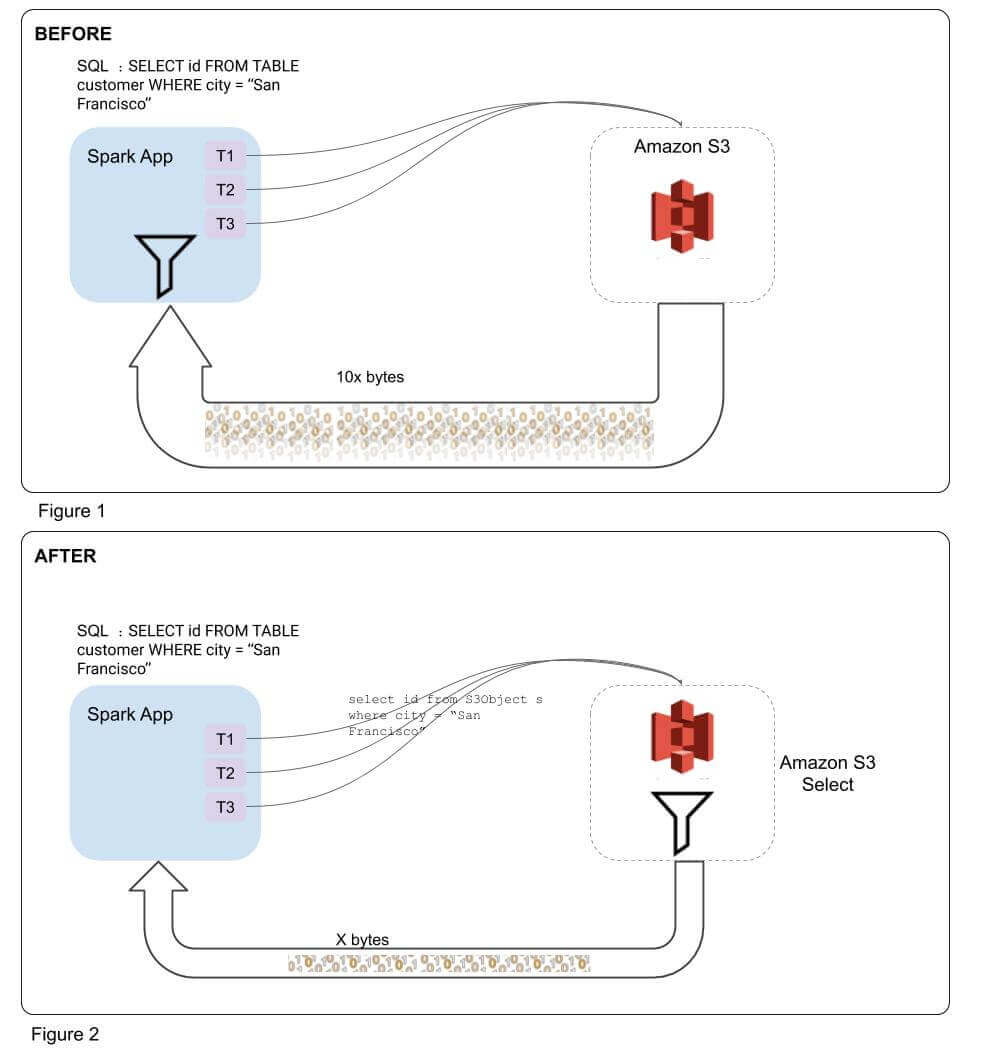
Spark S3 Select integration
The above diagrams illustrate how Spark interacts with the S3 Select service at a logical level. In Figure 1, without S3 Select optimization, Spark reads file after file and filters the data based on the predicate. Whereas in Figure 2 with S3 Select optimization turned on, Spark sends the S3 Select SQL based on the application code and gets back only the filtered portion of data from S3 Select. This drastically reduces the network I/O happening for needle-in-the-haystack kinds of queries, thereby speeding up the query.
Implementation
Typically, it would be hard to change the existing code or recreate new tables with S3 Select. We went one step further by automatically optimizing existing CSV/JSON tables or data frames using S3 Select without any change in the application code. We call it AutoConversion, and we will go into the details in the next section.
S3 Select AutoConversion
SQL optimizers in general look at the user’s queries and try to optimize the queries for the best performance. In order to achieve AutoConversion with S3 Select, we added rules to Spark SQL’s optimizer (Catalyst).
How Does AutoConversion Work?
In the optimization phase, the newly added rules try to optimize the user’s queries with S3 Select if possible. Below are the few requirements that the query should satisfy to get converted to S3 Select:
- Input data must be read from S3.
- Data types used for the columns must be supported by Amazon S3 Select.
- The data format must be either CSV or JSON.
- Compressed data is currently not supported.
- If S3-backed tables in a query do not require any column projections or row filtering, then they are not optimized as they are already better off with a normal S3 read. For instance in query “SELECT * FROM foo”, the foo table would not need S3 Select.
But sometimes users need more control over how they access the data, so we also provide ways to create a data source on top of S3 Select manually. The following section explains how to create data frames or create tables manually using S3 Select on top of CSV or JSON data sources.
Manual Conversion
Qubole added a new data source for S3 Select in Spark with the recent Qubole Data Platform release. With this new data source, S3 Select can be used out of the box both with data frames as well as SQL.
For example:
- Dataframe API –
spark.read.format("org.apache.spark.sql.execution.datasources.s3select").option(“fileFormat”, “csv”).load() - SQL –
CREATE TABLE foo USING "org.apache.spark.sql.execution.datasources.s3select" LOCATION s3://bucket/filename OPTIONS()
We have documented the usages of other options extensively in the S3 Select documentation section.
With this support, users can now choose which tables or files need to be optimized through S3 Select, and accordingly, they can create S3 Select tables or data frames on top of the underlying data.
Performance Gains
We ran the TPC-DS scale 1,000 performance benchmark with S3 Select on the underlying CSV data. With our benchmarks, we saw a geo-mean improvement of 2.9x with max speedups up to 5x.
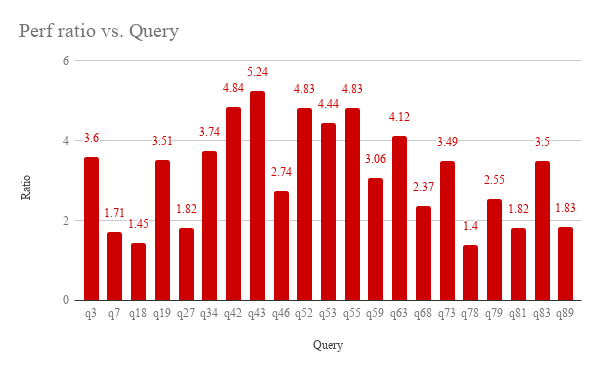
Spark S3 Select TPC-DS Scale 1000 Benchmark
Future Work
- Currently, the S3 Select support is only added for text data sources, but eventually, it can be extended to Parquet.
- Although AWS S3 Select has support for Parquet, Spark integration with S3 Select for Parquet didn’t give speedups similar to the CSV/JSON sources. This is because the output stream is returned in a CSV/JSON structure, which then has to be read and deserialized, ultimately reducing the performance gains.
- Spark’s current Parquet readers are already vectorized and are performant enough, so in order to get similar speedups with S3 Select, the output stream format should have very little cost in deserialization.
- In the future, we will also add support for compressed tables with the AutoConversion feature.



