While implementing a big data infrastructure in the cloud, companies are facing a wide range of technical and non-technical challenges. To help our customers to overcome some of these challenges and apply the latest best practices, Qubole offers professional services. The objective of our Professional Services organization is to assist Qubole customers with removing various barriers and enable successful implementation of their big data projects. The scope of professional services ranges from small engagements such as Spark job optimization to workshops, complete project implementations, and staff augmentation.
This article will focus on multi-region big data environment implementation, uncover some key challenges, and share best practices.
High-Level View of Big Data Environments
The diagram below represents a simple case of big data implementation. All data and compute resources such as S3 and EC2 are located in a single cloud region, and most likely in a single cloud account. It’s natural to expect that geographically the cloud region is close to the actual users as well as to the systems consuming the big data services. With such a simple scenario, implementation of the Qubole environment can take as little as a single day.
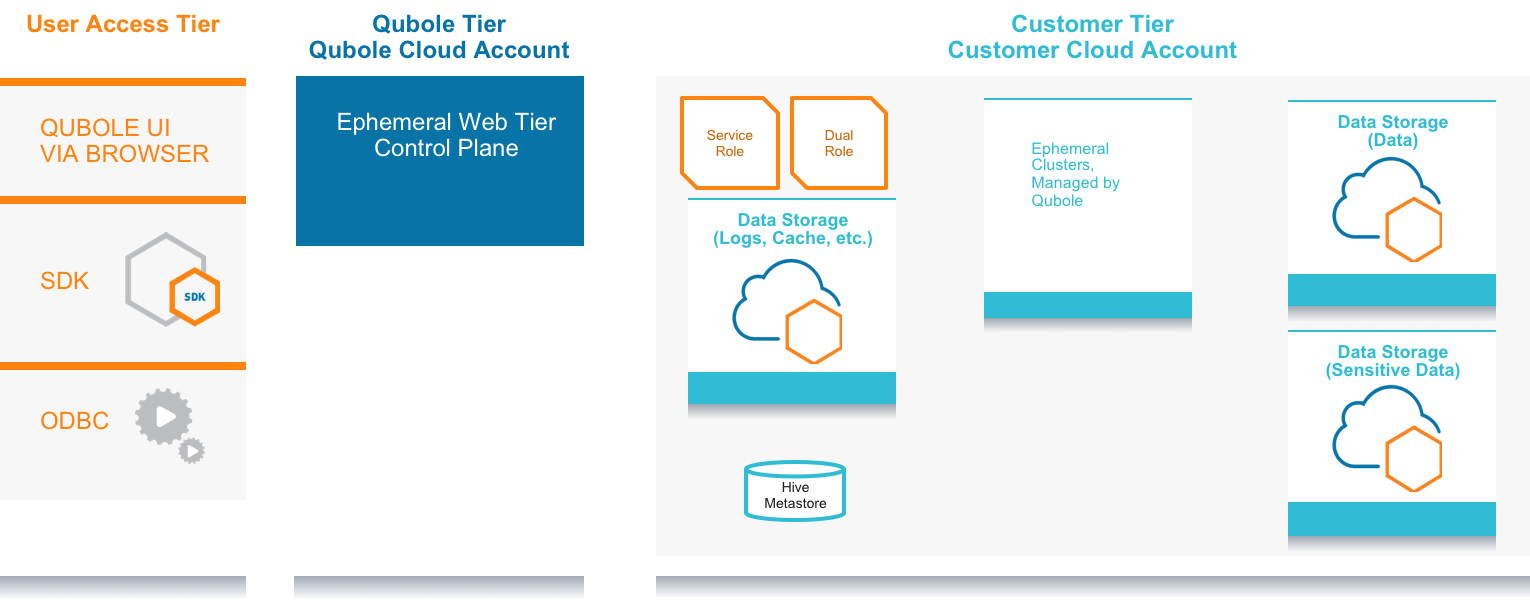
In today’s modern global economy, a vast majority of organizations — from large enterprises to startups — have their data on the cloud in more than one region. In many cases, these regions cross legislative boundaries and, in some cases, the users of the data are located in different countries. As a result, the big data environment becomes more complex and it becomes important to stay focused on the objectives, use cases, and expectations. Below, you’ll find a high-level view representing big data multi-region implementation with Qubole.
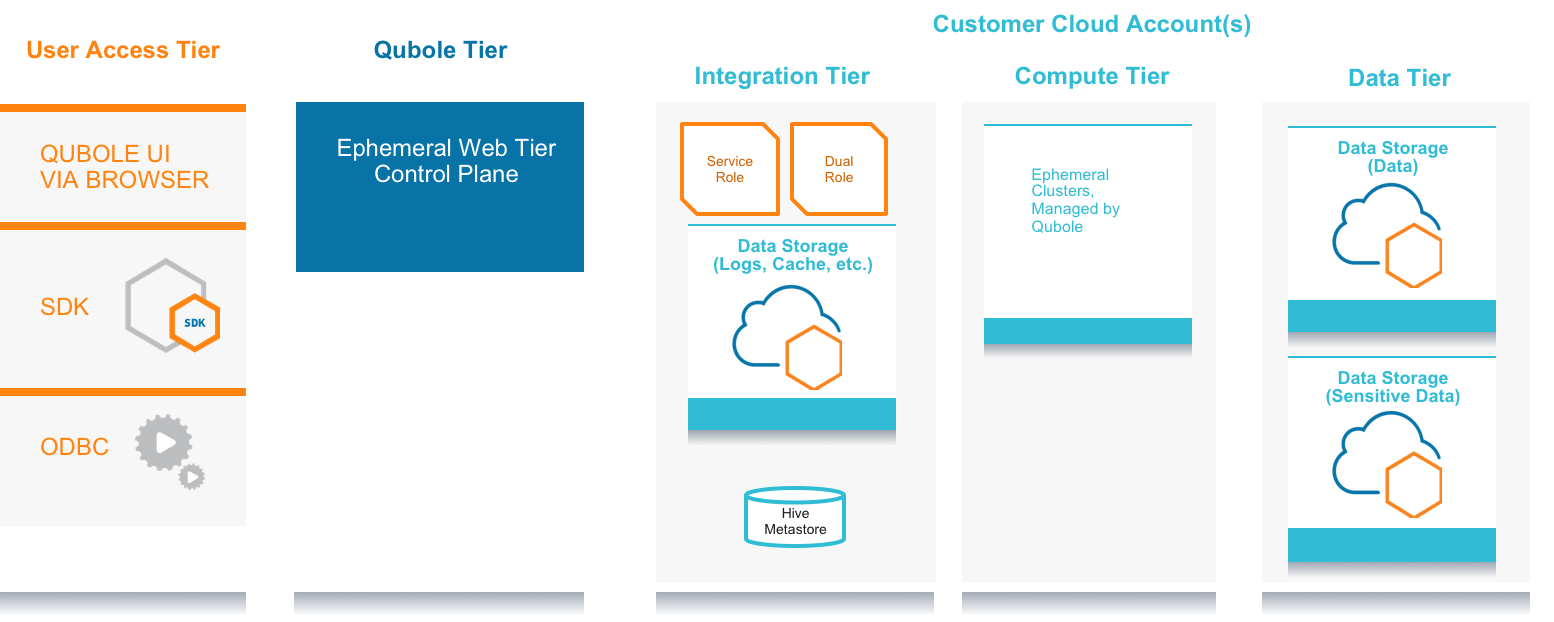
In a complex big data environment, the environment consists of multiple tiers:
User Access Tier – End users such as administrators, data analysts, data engineers, and data scientists who need to utilize Qubole to access and process data using Qubole UI, SDK, JDBC, and ODBC. The end users can be located in different geographical locations and countries.
Qubole Tier – The Qubole Tier does authentication and authorization, manages and operates clusters, and provides a collaborative development environment through the web UI, API, JDBC, and ODBC. It’s the tier that enables a self-managed big data environment.
Integration Tier – Customer’s cloud account that has a configured partnership with their Qubole cloud account. In addition to a Service Role, the account usually hosts Dual Roles that allow users to limit access to sensitive data, set a default location for log files, and provide access to the Hive metastore.
Compute Tier – This is the tier that provides compute capabilities. It can be implemented with one or more cloud accounts and contains compute instances such as EC2 for running clusters nodes. This tier can also contain Virtual Private Clouds (VPCs) and other related objects.
It’s important to note that, due to the decoupling of data and compute, a best practice is to treat clusters in Qubole as ephemeral resources.
Data Tier – This is the tier that contains data. The data persists in cloud storage such as S3 buckets. A best practice here is to keep data of various levels of sensitivity in different S3 buckets.
The Challenges of Multi-Region Implementation
Cloud providers design their infrastructure with the idea of concentrating it in different geographical locations. This approach allows companies to build a powerful and relatively inexpensive infrastructure in a single region. However, networking pipes between the regions is a more expensive and a limited resource with this approach. As a result, dispersing your big data environment across cloud regions creates latency and generates additional costs. Latency between different tiers will have different impacts on the overall experience within the ecosystem.
Latency between Data Tier and Compute Tier. The Compute Tier processes big data that it reads from the Data Tier and then writes back to the Data Tier. Due to this nature, a single big data processing job can easily exchange terabytes of data. These two tiers exchange the most data in this environment. Placing a Qubole cluster in a different region from the Data Tier will create a bottleneck, drastically impact the job execution time, and generate additional costs for exchanging data between regions.
Latency between Compute Tier and Integration Tier. As a part of operations, clusters write various log files to the data storage that is called the “default location.” The default location is also used as an intermediary storage for result sets intended to be available through the UI and API. Managed Hive tables are also located on the default location. Using managed tables to store large data sets when the Compute Tier and Integration Tier are located in different regions will create the same challenges as the latency between the Data Tier and Compute Tier we discussed above. A best practice is to avoid using managed tables when these tiers are located in different regions.
It’s important to note that Qubole does not delete the log files nor the result sets from the default location, making these available for auditing and other purposes.
Latency between Qubole Tier and Integration Tier. The Integration Tier is used to establish partnership between the customer cloud account and the Qubole cloud account. This partnership is required for the Qubole Tier to create a self-managed big data ecosystem and provide users with access to big data functionality. The latency between these two tiers will manifest as delays in displaying result sets and log files in the UI, and delays with cluster startup.
Latency between Qubole Tier and Compute Tier. The Qubole Tier will communicate to the clusters running on the Compute Tier to run and manage workloads. The latency between these tiers will create latency in submitting commands. However, the impact is not as significant as from the latency between other tiers.
Latency between Qubole Tier and Data Tier. The Qubole Tier will access the Data Tier to allow users to browse data storages. The latency between these tiers will moderately impact the user experience in this area of the UI.
Latency between User Access Tier and Qubole Tier. The Qubole Tier supports all UI and API functionality along with authentication and authorization. Latency between the Qubole Tier and the User Access Tier will drastically impact the overall user experience.
Metastore Latency. The Hive Metastore is used by clusters running on the Compute Tier to read and write Hive metadata. It’s also used by the Qubole Tier to show Hive Databases and Tables. However, the metadata can be cached on the clusters and on the UI, and the impact is moderate in most cases.
The table below summarizes the impact of latencies between various tiers. Please note that the table represents the majority of usages when best practices are followed. It’s important to consider specific use cases for your evaluation.
| LATENCY SCOPE | IMPACT | ||
| JOB EXECUTION | UX | COST | |
| Data – Compute | High | Low | High |
| Compute – Integration | Low to High | Low | Low to High |
| Qubole – Integration | Low | Moderate | Moderate |
| Qubole – Compute | Low | Moderate | Low |
| Qubole – Data | Low | Moderate | Low |
| User – Qubole | Low | High | Low |
| Metastore | Moderate | Moderate | Low |
Qubole Tier Environments
Qubole provides environments certified for various use cases such as HIPAA and SOC 2 Type 2 in the US, APAC, and Europe.
Options, Considerations, and Best Practices
It’s pretty obvious that it makes sense to have the Data Tier and the Compute Tier in the same region. However, the decision on locating other tiers is less obvious. Let’s consider a use case, when users located in the US need to access data in a region in the US and a region in the EU.
In the first implementation option depicted below, users in the US access a single end point (us.qubole.com). The integration tier is also located in the US region. This decision is made to optimize user experience and provide a responsive development environment. Qubole lets you use a single Qubole account to create and manage clusters in multiple regions, and that allows for Compute Tiers to be located in the same regions as their respective Data Tiers.
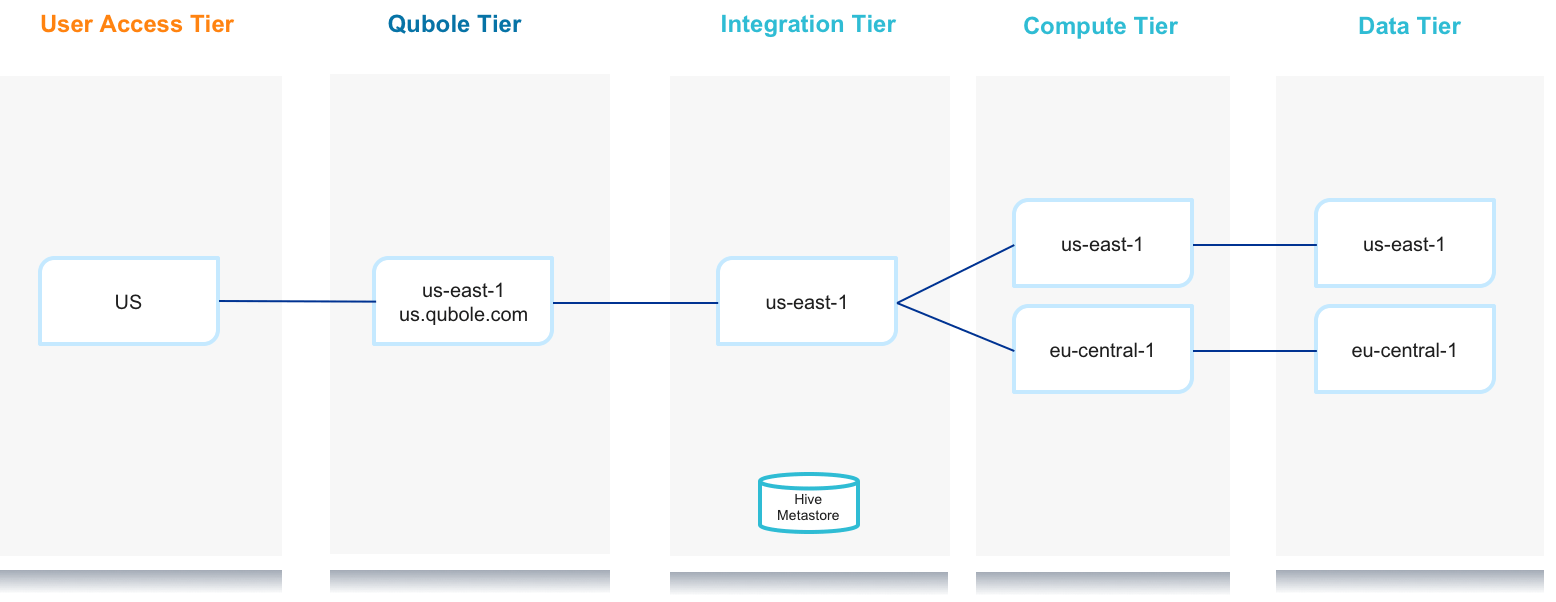
These are some disadvantages to this implementation option:
- The data that originates in the EU region will travel through the Qubole Tier located in the US, which can create legal challenges.
- The log files and some result sets will persist in the Integration Tier located in the customer’s cloud account in the US, and can also create legal challenges.
- Using managed Hive tables will be challenging, as they will be located in the Integration Tier in the US and clusters may need to write large data sets to the default location.
- The clusters in the EU region will have to access the metastore located in the US region. This may somewhat slow down job processing.
An alternative implementation option is depicted in the following diagram:
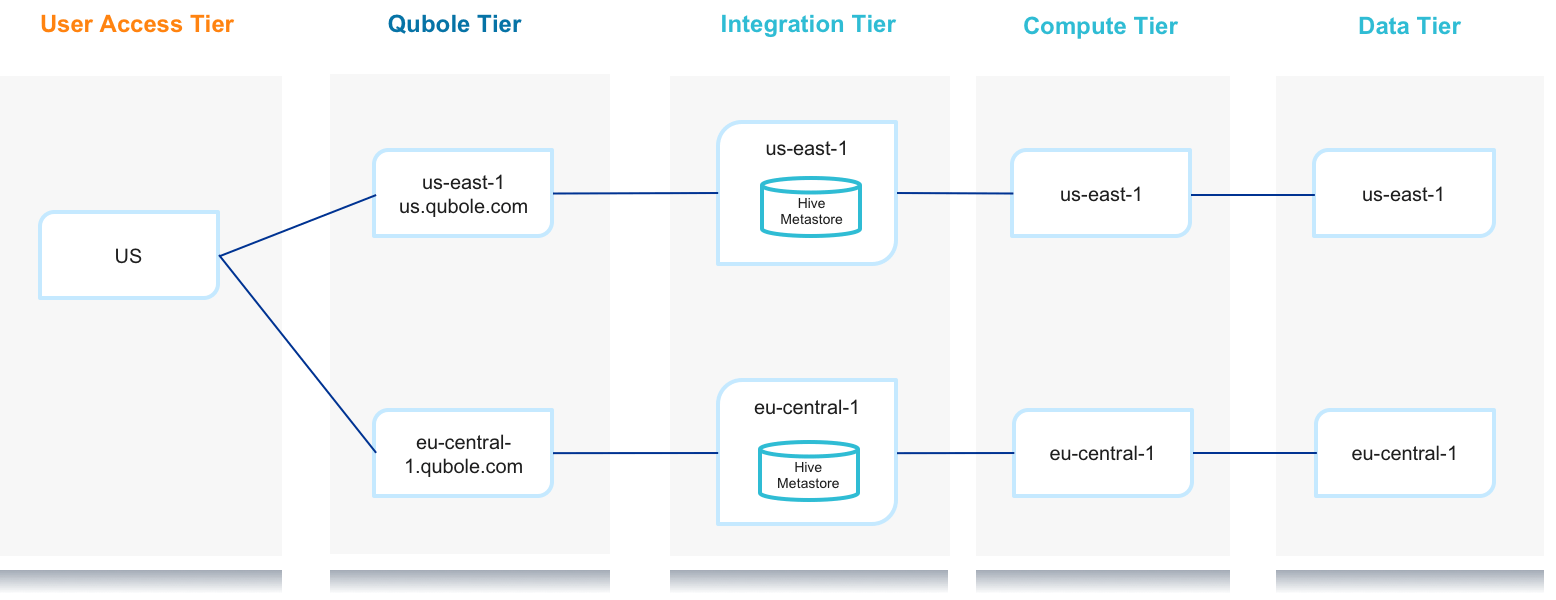
With this option, there are two Qubole accounts in the Qubole Tier, located in the same regions as their respective Data Tier. This implementation option helps solve the challenges we experienced with the first implementation option. It will also allow the customer to have a dedicated Hive Metastore for each region, which will increase data security and improve job performance. However, this implementation option will significantly degrade the responsiveness of the UI and the overall user experience when working with the Qubole Tier in the EU region.
In Conclusion
Implementing a multi-region big data environment is a complex undertaking that poses many challenges. A clear understanding of objectives and business requirements will help to clarify legal, technical, and other challenges and make the best design options.
Qubole is a pioneer of big data in the cloud, and our Professional Services team has experience implementing environments to accommodate various use cases. Whether you are considering migrating from on-premises to the cloud, implementing a brand-new big data environment, or have been a Qubole customer for some time, contact us to set up a free one-hour assessment meeting.
For more information about Qubole’s PS team, please view our full list of professional support services.



