We are happy to announce the availability of sparklens.qubole.com, a reporting service built on top of Sparklens. This service was built to lower the pain of sharing and discussing Sparklens output. Users can upload the Sparklens JSON file to this service and retrieve a global sharable link. The link delivers the Sparklens report in an easy-to-consume HTML format with intuitive charts and animations. It is also useful to have a link for easy reference for yourself, in case some code changes result in lower utilization or make the application slower.
Why Should I Use This Reporting Service?
Typically, users use Sparklens by adding the following parameters to their spark application:
--packages qubole:sparklens:0.2.0-s_2.11 --conf spark.extraListeners=com.qubole.sparklens.QuboleJobListener
The problem with this approach is that the Sparklens output is written to stdout, and if not redirected to a file, the output is lost forever. With Sparklens 0.2.0 we have added support for Sparklens JSON, a new file format. When enabled, instead of writing output to stdout, Sparklens will write raw data in JSON format to Sparklens json file. Moreover, Sparklens will skip performing any simulations while the application is running. Note that this is a very compact file that consists of just the information required for Sparklens reporting, which typically does not exceed a few megabytes — in contrast to event log files, which can run up to hundreds of megabytes.
--packages qubole:sparklens:0.2.0-s_2.11 --conf spark.extraListeners=com.qubole.sparklens.QuboleJobListener --conf spark.sparklens.reporting.disabled=true --conf spark.sparklens.data.dir=/dir/for/saving/sparklens.json
Utilities are provided to convert the Sparklens JSON file to a standard Sparklens report. With this approach, users can re-create a Sparklens output report at any time as long as they have saved the Sparklens JSON file. Given a Sparklens JSON file is thus saved, it is possible to get the Sparklens report at anytime in the future using the following command:
./bin/spark-submit --packages qubole:sparklens:0.2.0-s_2.11 --class com.qubole.sparklens.app.ReporterApp qubole-dummy-arg <filename>
Note that we are using Spark to run the Sparklens reporting app. Since Spark can easily download packages, this approach works without requiring users to download or build Sparklens. Alternatively, it is possible to run the ReporterApp by building Sparklens jars and adding Spark and Hadoop jars to Classpath.
Take a Peek at the Sparklens UI
Below are some screenshots of the new UI, which includes five key components: efficiency statistics, simulation, per stage metrics, ideal executors, and aggregate metrics.

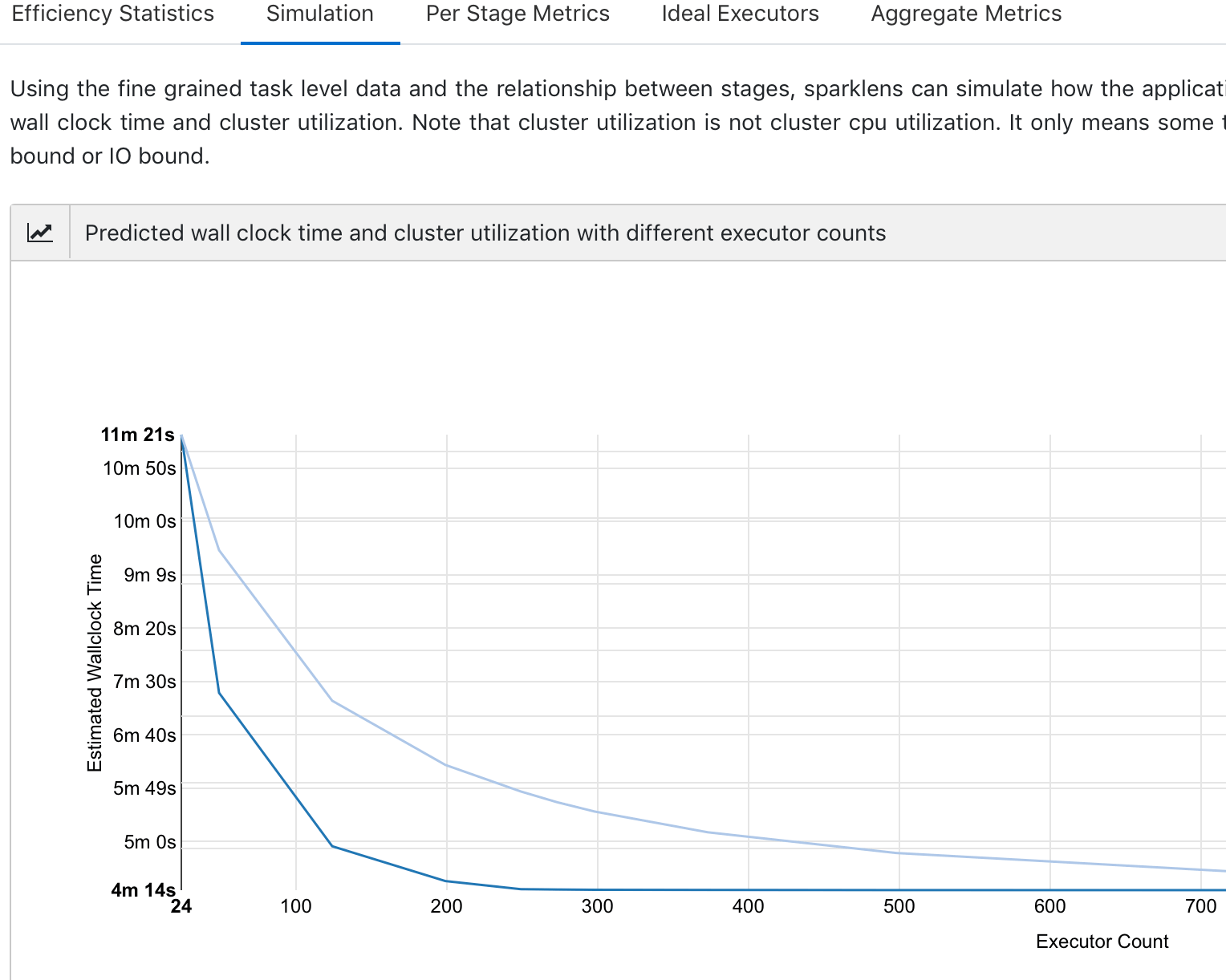

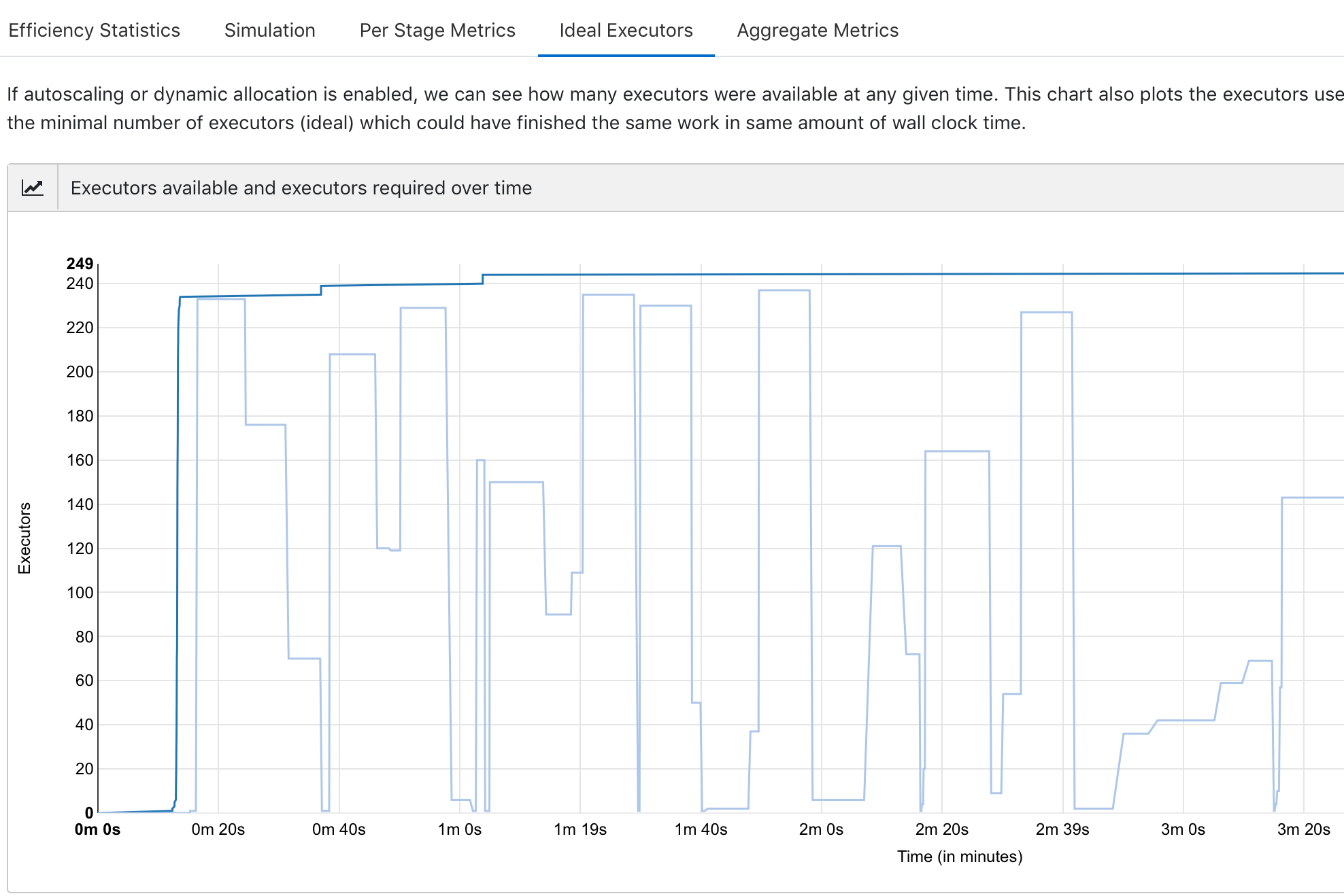
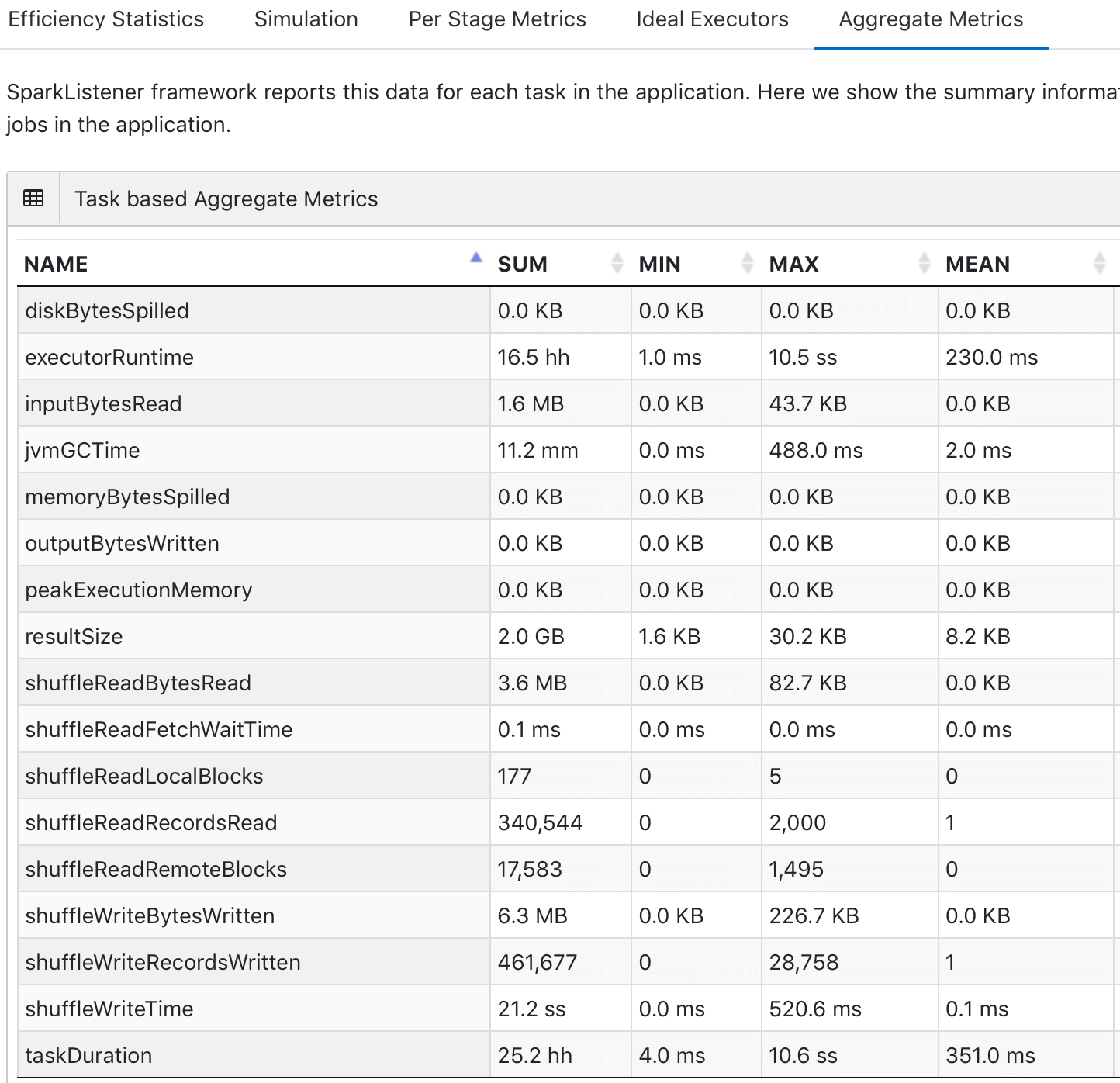
To use this service, first configure your Spark applications to save Sparklens JSON to some known location (including S3) and then upload it to sparklens.qubole.com. We hope this article helps to simplify the retrieval and analysis of Sparklens reports.
Try Sparklens for yourself — Start Free Trial



