Co-authored by Jeffrey Ellin, Solutions Architect, Qubole.
The Internet of Things (IoT) is increasingly becoming an important topic in the world of application development. This is because these devices are constantly sending a high velocity of data that needs to be processed and analyzed. Amazon Kinesis and Amazon IoT are a perfect pair for receiving and analyzing this data and Spark Streaming can be used to process the data as it arrives.
In this blog post, we will look at Kinesis, Apache Spark, Amazon IoT and Qubole to build a streaming pipeline. Amazon IoT and Kinesis are services that can be provisioned easily on AWS and for Spark Streaming we will use the Qubole platform. Qubole offers a greatly enhanced, easy to use, and cloud optimized Spark as a service for running Spark applications on AWS.
Sample IoT Dataset
Amazon provides an IoT data generator called Simple Beer Simulator (SBS) that generates random JSON dataset from a simulated IoT device connected to a beer dispenser. Sample data includes temperature, humidity, and flow rate. See below.
{"deviceParameter": "Sound", "deviceValue": 109, "deviceId": "SBS03", "dateTime": "2017-08-19 23:57:26"}{"deviceParameter": "Temperature", "deviceValue": 35, "deviceId": "SBS04", "dateTime": "2017-08-19 23:57:27"}{"deviceParameter": "Temperature", "deviceValue": 23, "deviceId": "SBS03", "dateTime": "2017-08-19 23:57:28"}{"deviceParameter": "Humidity", "deviceValue": 86, "deviceId": "SBS01", "dateTime": "2017-08-19 23:57:29"}
This sample data will be streamed into Amazon IoT and passed via a rule to Kinesis.
Creating the Kinesis Stream
Log into your AWS console, navigate to Kinesis and create a stream called iot-stream.
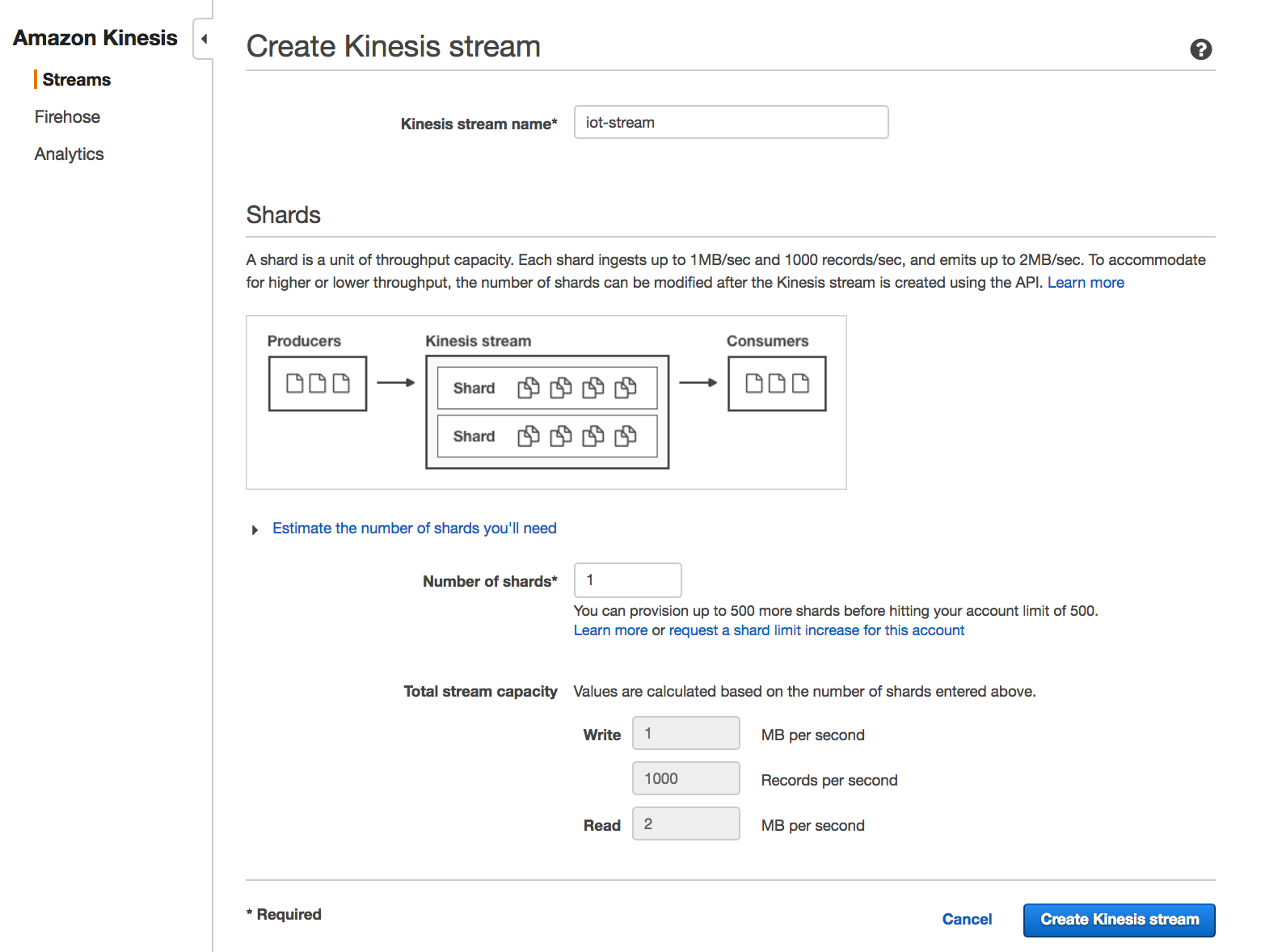
Note: One shard is good for this example because we won’t be stressing the application with a large volume of devices and data. In a real world scenario, increasing the number of shards in a Kinesis stream will improve application scalability.
Create an IoT Rule
Log into your AWS console, navigate to IoT, and create a new rule as follows.
Name: SBS_TO_KINESIS
Topic Filter: /sbs/devicedata/#
Attribute: *
Create an IoT Action
Navigate to IoT and create an new Action as follows.

Select Kinesis as a destination for your messages. On the next screen, you will need to create a rule to publish to Kinesis.
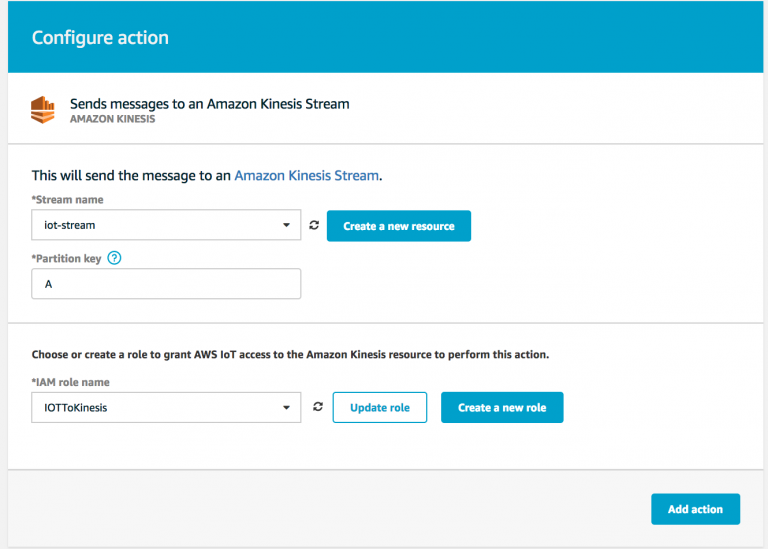
Click Create role to automatically create an IAM role with the correct policies. Click through to complete creating the rule with all the defaults. If you are using an existing role, you may want to click the update role button. This will add the correct Kinesis stream to the role policy.
Create IAM User
In order for the SBS to be able to publish messages to Amazon IoT it uses boto3 and therefore requires permission to the appropriate resources. Create a user with AWSIoTFullAccess and generate an access key and secret. In the SBS directory, there is a credentials file that should be updated with your access key and secret.
[default]aws_access_key_id = <your access key>aws_secret_access_key = <your secret access key>
Build the docker container for SBS
docker build -t sbs .Run the docker container
docker run -ti sbsAt this point, you should have data being sent to Kinesis via Amazon IoT.
Spark Streaming
The Scala app reads data from Kinesis and saves the result to a CSV file. You will need to create a user that has access to read off of the Kinesis stream. This credential would be different than the one used for the SBS. Note: For this sample application we’re using a key which has admin access to everything in the account. In a real world scenario, you should restrict this key to only being able to read the iot-stream.
val awsAccessKeyId = "your access key"val awsSecretKey = "your secret"
Define a case class to use as a holder for the JSON data we receive from Kinesis.
case class Beer(deviceParameter:String, deviceValue:Int, deviceId:String,dateTime:String);Connect to the Kinesis stream.
val kinesisStream = KinesisUtils.createStream(ssc,kinesisAppName, kinesisStreamName,
kinesisEndpointUrl, RegionUtils.getRegionMetadata.getRegionByEndpoint(kinesisEndpointUrl).getName(),
InitialPositionInStream.LATEST,
Seconds(kinesisCheckpointIntervalSeconds),
StorageLevel.MEMORY_AND_DISK_SER_2, awsAccessKeyId, awsSecretKey)
iot.foreachRDD { rdd =>
val sqlContext = new SQLContext(SparkContext.getOrCreate())
import sqlContext.implicits._
val jobs = rdd.map(jstr => {
implicit val formats = DefaultFormats
val parsedJson = parse(jstr)
val j = parsedJson.extract[Beer]
j
})
//output the rdd to csv
jobs.toDF().write.mode(SaveMode.Append).csv("s3://your-bucket/streamingsbs")
}
The complete code can be found at — https://github.com/jeffellin/spark-kinesis/tree/qubole-part-1
Build a fat jar using SBT
sbt assemblyCopy the jar to S3 using the aws cli or using the tool of your preference.
aws s3 cp target/scala-2.11/MyProject-assembly-0.1.jar s3:\\your-bucket\apps\MyProject-assembly-0.1.jarSpark On Qubole
In order to run this application we will use Spark running on Qubole. Run the following command in Analyze interface.
spark-submit --class example.SBSStreamingReader --master local[8] s3:\\your-bucket\apps\MyProject-assembly-0.1.jar
Let the job run for a while and you should see the data being written to the S3 directory specified in the streaming class. Note: Qubole will continue to run this Spark streaming job for 36hrs or until you kill it. Alternatively, what’s illustrated here can be achieved with Kinesis Firehose, but this post shows you the use of Apache Spark with Kinesis.
Why Spark on Qubole?
Qubole offers a greatly enhanced and optimized Spark as a Service, it makes for a perfect deployment platform.
Highlights of Apache Spark as a service offered on Qubole
- Auto-scaling Spark Clusters
- In the open source version of auto-scaling in Apache Spark, the required number of executors for completing a task are added in multiples of two. In Qubole, we’ve enhanced the auto-scaling feature to add the required number of executors based on configurable SLA
- With Qubole’s auto-scaling, cluster utilization is matched precisely to the workloads, so there are no wasted compute resources and it also leads to lowered TCO. Based on our benchmark on performance and cost savings, we estimate that auto-scaling saves Qubole’s customers over $300K per year for just one cluster.
- Heterogeneous Spark Clusters on AWS
- Qubole supports heterogeneous Spark clusters for both On-Demand and Spot instances on AWS. This means that the slave nodes in Spark clusters may be of any instance type.
- For On-Demand nodes, this is beneficial in scenarios when the requested number of primary instance type nodes are not granted by AWS at the time of request. For Spot nodes, it’s advantageous when either the Spot price of the primary slave type is higher than the Spot price specified in the cluster configuration or the requested number of Spot nodes are not granted by AWS at the time of request.
- For more details, click here.
- Optimized Split Computation for Spark SQL
- We’ve implemented optimization with regards to AWS S3 listings which enables split computations to run significantly faster on Spark SQL queries. As a result, we’ve recorded up to 6X and 81X improvements on query execution and AWS S3 listings respectively.
- For more details, click here.
- To learn how you can use Qubole for various workload types, click here.
Stay Tuned!
In the next post, you will learn how to visualize this data in realtime using a Spark notebook running on Qubole.



