With the increased usage of public cloud storage, intelligent management of frequently accessed data has become more important. For interactive queries, reading the same data over the network adds latency to the overall query time. RubiX, an open-source project from Qubole, was developed to eliminate this I/O latency by caching data in local compute nodes and reducing multiple round trip calls to object-store. The architecture of RubiX is a result of efforts to improve query performance in a shared autoscaling Presto, Hive, and Spark cluster that process petabytes of data stored in columnar formats.
Rubix Meets Spark
We at Qubole are excited to announce support for RubiX caching in the QDS platform. RubiX has been working as a solution in ad hoc query engines such as Presto. With the use of RubiX, we have seen a significant performance gain — up to 4x for TPC-DS workloads. Our internal customers have experienced even greater gains for their I/O heavy workloads.
In this blog, we will focus on the features of RubiX cache, how it differs from Spark’s internal cache, and its performance improvement for Spark workloads.
Spark Internal Caching
Users can use Spark internal caching to cache required data, which can reduce the latency of reading data from a remote object store by caching the result of a table scan operation. However, this feature also has a number of shortcomings.
- By default, the cache uses its main memory to store the result. If the result size is bigger, Spark application performance will suffer as the memory available to store shuffle data or hash tables decreases.
- This cache is bound to a particular Spark application. Any other application accessing the same data won’t be able to take advantage of the cached data. The application code must be changed to cache the required data explicitly as well. Not all users are comfortable making the necessary changes, and going through multiple iterations of fine-tuning what to cache also increases development effort.
How RubiX Helps
Where Spark’s internal cache has its drawbacks, RubiX comes to the rescue. RubiX is a file system—level cache that enables users to store data in the cluster nodes, reducing the time to read the data from the remote object store for subsequent queries.
RubiX Cache and Its Features
Decentralized Architecture: As a distributed cache, RubiX decides the ownership of files among the cluster nodes by using consistent hashing. With help of consistent hashing, each node in the cluster is aware of which data belongs to which node, thus removing the necessity of a centralized system.
File format-agnostic cache: Although RubiX is specially built for columnar file formats such as Parquet and ORC, the same features of the cache can be availed by any big data file formats such as JSON, Avro, Text, etc.
Zero overhead cache: Cache reduces the latency of the workloads when the required data has already been accessed and present in the cluster. Typically, caches have a warmup penalty during the first access. RubiX ensures that accessing data for the first time does not receive any penalty during cache warmup. If the data is not in the cache, RubiX serves the query by directly reading from the remote object store while populating the cache in parallel.
Cache what you access: Instead of downloading the whole file, RubiX caches only the part of the file that has been accessed. This lazy nature of cache reduces the cache warmup time as well as limits cache pollution.
Cache invalidation: RubiX also figures out if there is any update or deletion of the cached file in the remote object store and invalidates the local cache to get up-to-date data from the object-store.
Cache eviction: RubiX evicts older files based on a least recently used policy when the cache has used its allocated disk space.
Shared cache across Spark applications: The data downloaded by one Spark application can be shared by another Spark application running in the same cluster. This data sharing across multiple Spark applications helps to increase cache usage with reduced overall disk space usage.
Fault-tolerant: In the event of any corruption in the cache, RubiX can detect these kinds of scenarios prior to reading the whole required data and automatically heal the cache without failing the job.
Easily configurable: No application code change is required. No change in the DDL script for the spark tables.
Performance Analysis
The main purpose of any cache is to access the data faster. To measure the performance improvement due to RubiX, we compared the time taken to read from the cache with the time the job takes to read the same data from the remote object store (in this case, S3).
To take advantage of faster SSDs, we selected AWS i3 instance types. These instance types provide NVMe SSDs that can efficiently handle a large number of concurrent requests. They not only provide low latency random seeks, but are also known for high read and write throughput.
The improved reading performance of RubiX cache provides a substantial gain for a wide variety of TPC-DS queries.
Experimental Setup:
Cluster: 10 i3.4xlarge instances
Dataset: Parquet data on TPC-DS 1000 scale
Spark Version: 2.3
The following graph shows the performance improvement provided by RubiX:
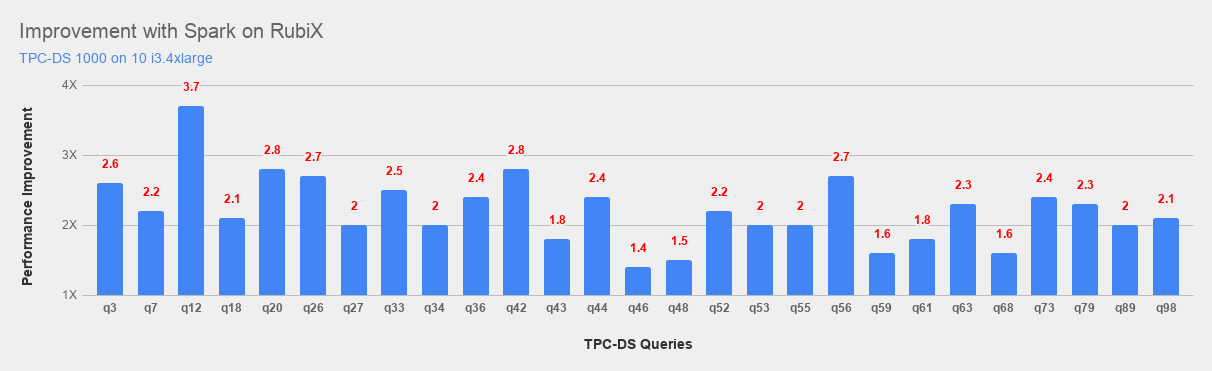
The performance of RubiX cache is measured by comparing the time the job takes when the data is stored in S3 with the time taken with the data in RubiX cache. For the purpose of this comparison, the cache was populated prior to running the queries.
Results Summary:
- Best Performance Improvement: 3.7x
- Average Performance Improvement: 2.2x
Because the RubiX cache is optimized for reading the data from a local disk, there are greater performance gains for read-intensive jobs. For CPU-intensive jobs, the gains made while reading the data are offset by the time spent on CPU cycles.
Enabling RubiX in the QDS Platform
Users of the QDS platform can enable RubiX for a particular Spark cluster by selecting a simple checkbox in the Advanced Configuration tab of the cluster configuration page.
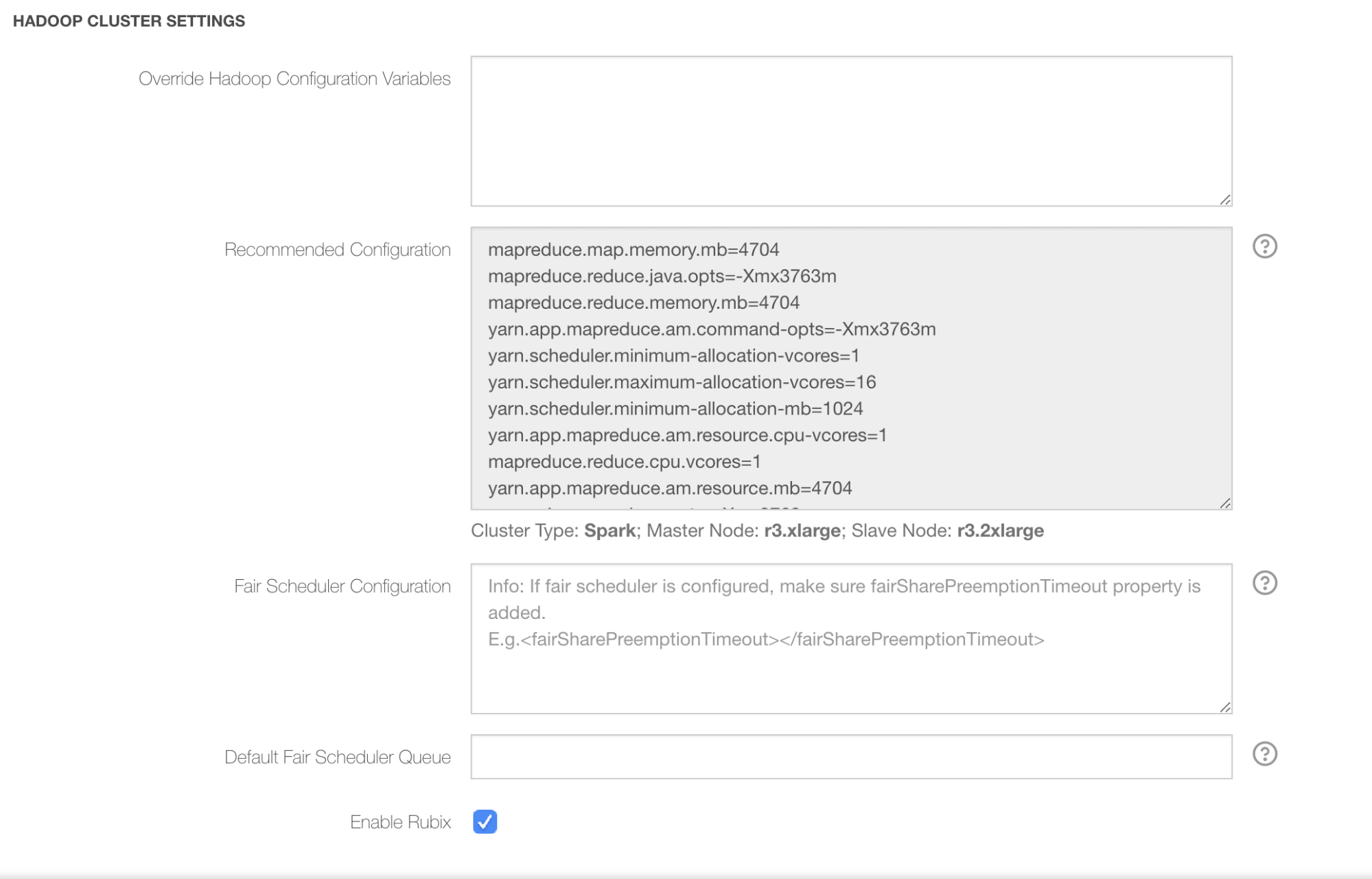
For existing clusters, the user must restart the clusters for the RubiX cache to take effect.
Conclusion
We have made RubiX available in open source to work with the big data community to solve similar issues across big data engines, Hadoop services, and distributions on-premises or in public clouds. If you are interested in using RubiX or developing on it, please join the community through the links below.
We have integrated RubiX with Spark in Qubole Data Service. To get started with RubiX and other exciting features in Spark, sign up for a free account here.



