SQL join operators are ubiquitous. Users performing any ETL or interactive query like “show me all the people in Bangalore under age 30 who took taxi rides on New Year’s Eve” would translate to a query that would require joins across multiple tables.
The distributed SQL engine in Apache Spark on Qubole uses a variety of algorithms to improve Join performance. Qubole has recently added new functionality called Dynamic Filtering in Spark, which dramatically improves the performance of Join Queries. In this post, we will talk about this optimization and explain the technical challenges involved in its implementation, along with performance numbers running TPC-DS workloads.
SQL Joins in Apache Spark
Spark has a distributed execution engine that can perform operations such as join, aggregation, and ordering data in a distributed manner. To perform any distributed Join operation, which runs across multiple processes/nodes, requires the records from both the tables associated with each join key to be co-located. There are a number of strategies to perform distributed joins such as Broadcast join, Sort merge join, Shuffle Hash join, etc.
Consider two tables:
employee(id: INT, name: STRING)
department(employee_id: INT, dept: STRING).
The SQL query to find the name and department of all employees will look like this:
Query1:
SELECT e.name,
d.dept
FROM employee e
JOIN department d
ON e.id = d.employee_idNow let us modify our query to include a filter predicate dept = admin on the `department` table.
Query2:
SELECT *
FROM employee e
JOIN department d
ON e.id = d.employee_id
AND d.dept = ‘admin’In both the queries, the `employee` table has a large number of records, but in the case of Query2, there are only 5 employees who are admins, whose ids are 1001-1005. A new predicate in Query2 would avoid a full scan on the `department` table, but a full table scan on `employee` is still required to perform the join operation. But if the above correlation, i.e. only 5 employees are present in the `admins` department, was known, a full table scan on employees could have been avoided. However, in most cases, it is complex and infeasible to identify such correlations manually.
The Qubole Dynamic Filter optimization is an automated way of figuring out new predicates by correlating the existing predicates on the `department` table(dept = ‘admin’) and applying the predicates on the `employee` table at runtime. We have observed that 40% of all TPC-DS queries fall under this category and can achieve an average 1.5x improvement in runtime and with few queries showing more than 2x performance gain.
Dynamic Filtering
In the previous example, with the information that the employees in the `admin` team have ids 1001-1005, the above query can be transformed into a semantically equivalent query below:
SELECT *
FROM employee e
JOIN department d
ON e.id = d.employee_id
AND d.dept = ‘admin’
AND e.id IN ( 1001, 1002, 1003, 1004, 1005)By enumerating the employee ids in the IN clause using the available information, the transformed query scans limited the number of records in the `employee` table by pushing down the predicates to the data source. But it may not always be possible to extract such information manually considering the huge data sets our customers to possess.
The critical insight here is that we can infer new predicates on employees (in this case e.id IN (1001, 1002, 1003, 1004, 1005)) using the user-supplied predicate on the department (in this case d.dept = ‘admin’) at runtime, whilst retaining correctness. We infer new predicates during the runtime of the query, hence the name “Dynamic Filter”, which improves both IO and network utilization speeding up the query.
Design: Spark Catalyst
The core of Spark SQL is the Catalyst optimizer. Catalyst handles different parts of query execution: analysis, logical optimization, physical plan generation, and code generation. The Spark dataframe API is also powered by Catalyst. To implement Dynamic Filtering in Spark, we made changes to the following components of Catalyst Optimizer.
Logical Plan Optimizer
The core of Spark SQL catalyst is the logical plan optimizer, which is a rule-based optimizer with an extensible set of rules to optimize the plan generated by a given SQL query/dataframe code. To implement Dynamic Filtering, a new optimizer rule has been added which collects the metadata required to infer filter predicates dynamically at query runtime. This rule traverses the logical plan tree to find those INNER joins where dynamically inferred filter predicates are applicable and collect required metadata from the tables involved in Join.
Physical Planner
The planner is responsible for creating physical plans from the logical plan, to run jobs in a distributed manner. To support Dynamic Filtering, a new physical operator has been introduced to the Physical planner. The new operator is responsible for filtering records using the dynamic filter predicates.
Query Execution
Filter predicates are collected dynamically and used in table scans and in the Dynamic Filter operator. When the execution of the query begins, the following happens:
- Filter predicates are collected by executing queries using the metadata available in the physical plan.
- The Filter predicates collected in (1) are:
- Pushed down to the data source. In our current implementation, the predicates are pushed down when the file format is Parquet. This can easily be extended to all file formats/data sources that support push down.
- Used in the Filter node dynamically inserted in the physical planning phase.
Plan Comparison
To showcase the effect of Dynamic Filtering in query plan generation, we performed the following join operation on two tables and analyzed its improvements:
The following are the details of the table involved in the join
t1 (id: Int, name: String) – 1 billion rows
t2 (id: Int, department: String) – 1 million rows
The tables are created using data frame APIs in Parquet file format.
Join Query:
SELECT *
FROM t1
JOIN t2
ON t1.id = t2.id
WHERE t2.id < 100When Dynamic Filtering is enabled, we observed a 48X improvement in runtime for the above query.
A simple sort-merge join involves the following phases:
- Table scan of the tables involved in the Join operation
- The shuffle of the data using the join column as the key for shuffling
- Sorting of the data
- Join operation
The following Figures 1 and 2 show the Spark plan with metrics of a sort-merge join operation with and without Dynamic Filtering respectively. The numbers on the right edge of the image indicate the phase of the sort-merge join (as mentioned above) corresponding to the plan execution.
Spark Metrics Without Dynamic Filtering
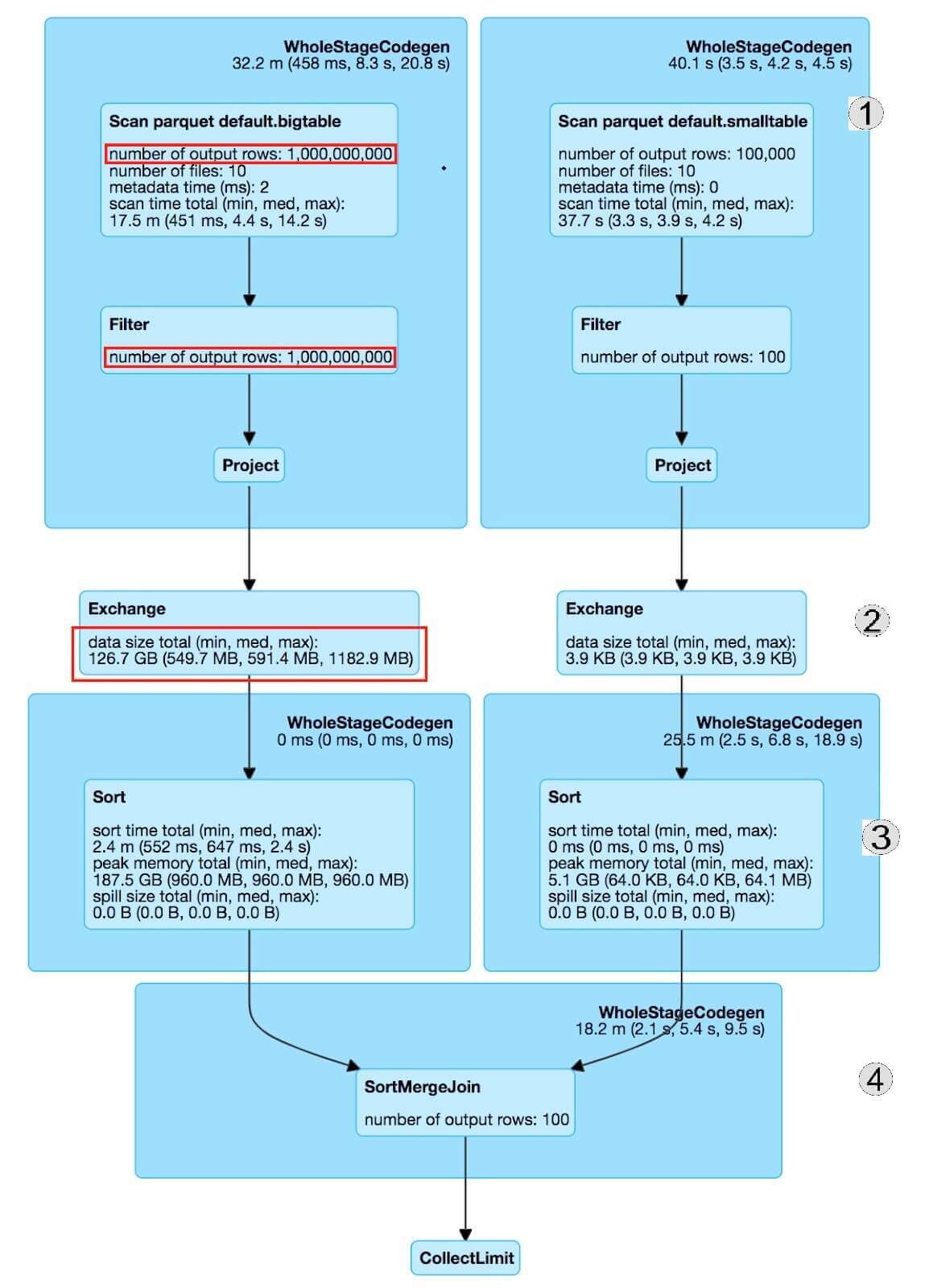
 Figure 1: Spark plan without DF
Figure 1: Spark plan without DF
Spark Metrics With Dynamic Filtering
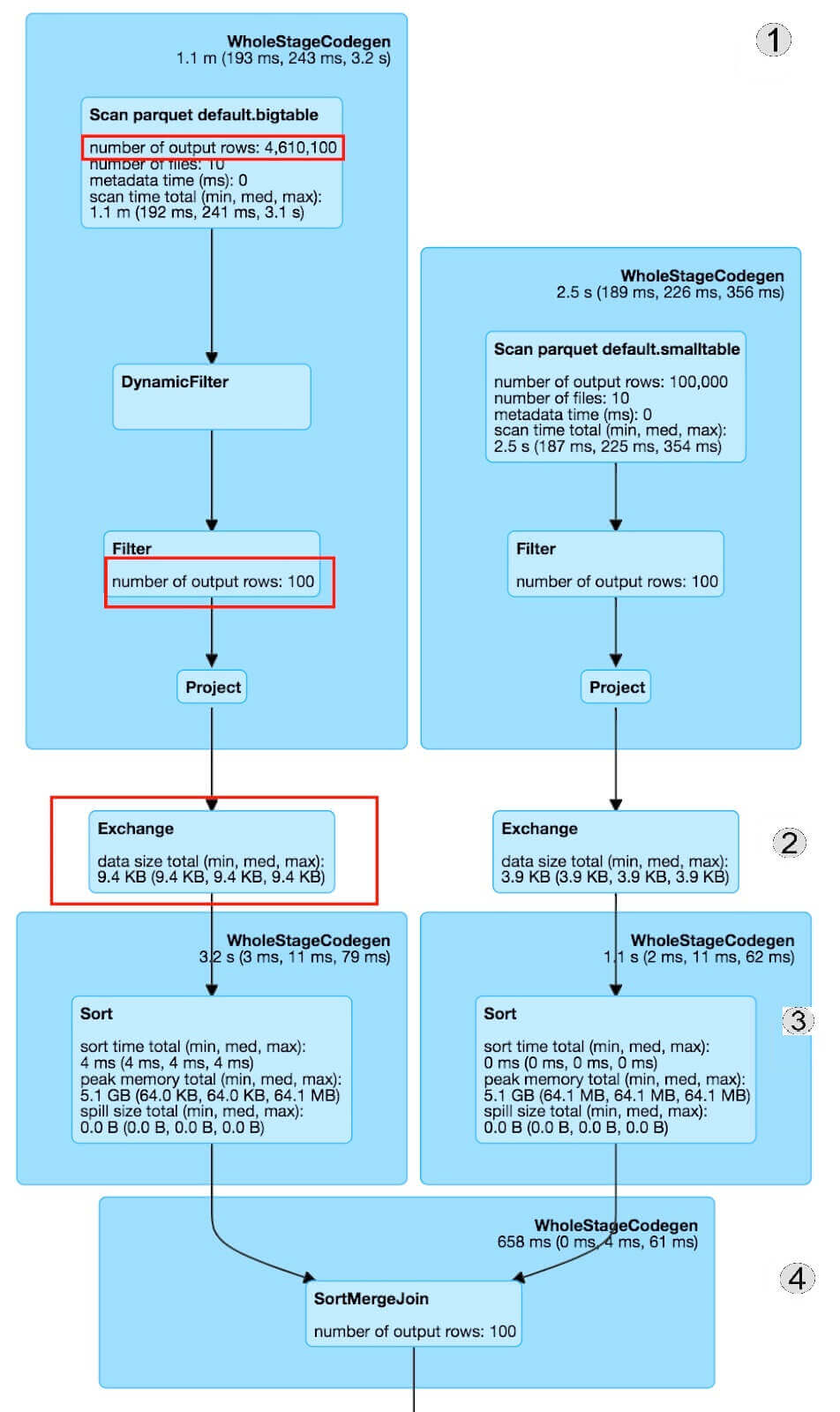 Figure 2: Spark plan with DF
Figure 2: Spark plan with DF
Inferring a filter dynamically and using such optimization requires a decision at runtime, taking into consideration various parameters like underlying storage format, query runtime, number of records returned, etc. to prevent any unforeseen performance degradation.
Broadcast Joins
Broadcast join is a join strategy used when one of the tables involved in a join can be completely held in memory. The table is broadcast to all mappers and the join is performed. Since Broadcast join does not involve shuffle, it is the fastest join strategy.
Since there is no shuffle involved in the broadcast join, it might seem like Dynamic Filtering will not provide any performance improvement. But it should be noted that we push down the dynamic filter predicates to the data source. That reduces the disk I/O required to read the data. It in turn reduces the number of rows involved in the join operation, resulting in faster join execution and lesser resource requirements.
Storage Formats
Dynamic filter predicates can be pushed down to data source formats that allow predicate pushdown (like Parquet, Orc). But it should be noted that predicate pushdown is a best-case effort and the results returned can contain rows that do not satisfy the predicate. Therefore, irrespective of the file format, an explicit filter operator with a Dynamic Filter predicate is necessary.
SQL Query Performance
In a distributed query processing environment, both disk and network I/O are important factors in query performance. The performance gains achieved by Dynamic Filtering help to reduce both of these, thereby reducing the cluster resource requirements.
Disk Utilization
By disk I/O, we refer to the amount of data read from the source (S3, HDFS). One popular technique to reduce the amount of data read in the presence of predicates is to push down the predicates to the source. In our query, the predicate is on the `department` table and the SQL optimizer will take care of pushing the predicate to that table. In the case of the `employee` table, only those records will be considered whose ids come from the subset of `department` records satisfying the predicate “dept = admin”.
Translating into SQL:
SELECT *
FROM (SELECT *
FROM employee e
WHERE employee.id IN (SELECT employee_id
FROM department
WHERE dept = ‘admin’)) e
JOIN department d
ON e.id = d.employee_id
WHERE d.dept = ‘admin’Now that we have an inferred predicate for the `employee` table on its id column, we will be able to push down the predicate to the source. By pushing down the predicate to the `employee` table, we have reduced the disk I/O.
Network Utilization
To ensure data correctness and reduce the number of records processed during the join operation, an explicit filter operation is added with the inferred Dynamic Filtering predicates. This significantly reduces the shuffle data generated and minimizes network I/O.
Cluster Resource Utilization
Dynamic Filtering reduces the system resource requirements by reducing the number of records involved in the join, thereby reducing the number of tasks spawned for the Join operation. The net effect is the completion of jobs with lower resource requirements.
Query Performance Benchmarks: TPC-DS Performance Evaluation
Our setup for running the TPC-DS benchmark was as follows:
TPC-DS Scale: 1000
Format: Parquet (Non-Partitioned)
Scheme: S3
Spark version: 2.3.1
Cluster configuration: 3 r3.2xlarge in AWS us-east region.
We observed that:
- 5 queries improved by 40%
- 15 queries improved by 20%
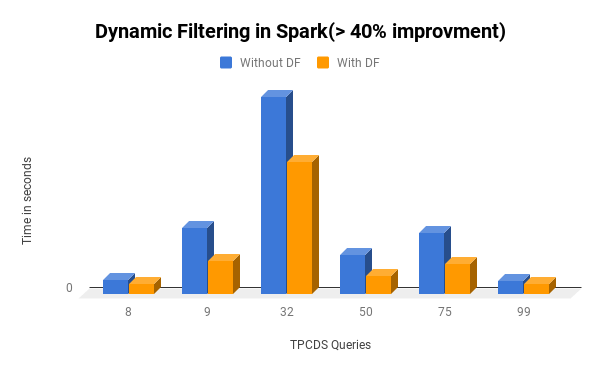 Figure 3: TPC-DS performance comparison (> 40% Improvement)
Figure 3: TPC-DS performance comparison (> 40% Improvement)
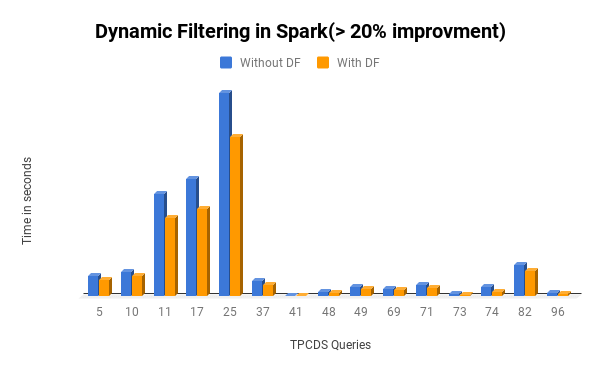 Figure 4: TPC-DS performance comparison(> 20% Improvement)
Figure 4: TPC-DS performance comparison(> 20% Improvement)
Why Qubole
This blog post explains the implementation details of Dynamic Filtering in Spark. This optimization shows up to 2X improvements on TPC-DS benchmarks. This feature is available in Qubole with Spark 2.3.1 and above versions in AWS and Azure.
Try Qubole today for free to test drive our Spark optimizations for yourself.



