Autoscaling has become a familiar concept and a fundamental requirement with the advent of Cloud Computing. It was one of the first fundamentals introduced with utility computing and has allowed applications to exploit elasticity, dynamic growth, and compute resources on an as-needed basis. However – as the Cloud has gained popularity and more complex applications have risen that require an exponential increase in data requirements in the Cloud – first-generation autoscaling technologies have fallen behind in being able to service the needs of these applications in an efficient way.
Workload-Aware Auto-Scaling, an alternative to traditional autoscaling, is becoming the required architectural approach to Autoscaling that is better suited for new classes of data-centric applications like Hadoop, Spark, and Presto and has now become commonplace in the Cloud. In this blog, we show you how Workload-Aware Autoscaling technologies such as that offered by Qubole are vastly superior and should likely be a requirement moving forward. These technologies significantly benefit Big Data analytical applications’ reliability, cost, growth, and responsiveness, from the simple and small to the extensive and complex algorithms and learning solvers. Let’s next take a moment to understand what exactly autoscaling is.
What Is Autoscaling?
Autoscaling is a mechanism built into the Qubole Data Service (QDS) that adds and removes cluster nodes while the cluster is running. This allows the user to keep just the correct number of nodes running to handle the workload. Autoscaling automatically adds resources when computing or storage demand increases while keeping the number of nodes at the minimum needed to meet your processing needs efficiently.
When we started building Autoscaling technologies at Qubole, we evaluated and rejected existing approaches to autoscaling due to their inability to build Cloud-Native Big Data solutions truly. Instead, we built Autoscaling into Hadoop and Spark, where it has access to the details of the Big Data applications and the detailed state of the cluster nodes.
Being Workload Aware has dramatically impacted our ability to orchestrate Hadoop and Spark in the Cloud. The different ways in which we have used this awareness include:
Upscaling:
Qubole-managed clusters look at various criteria – beyond resource utilization – to come up with upscaling decisions. Here are a few examples:
- Parallelism-Aware: If applications have limited parallelism (say a Job can only use 10 cores), upscaling will not scale the cluster beyond that number (even though the cluster may exhibit high resource utilization).
- SLA-Aware: QDS monitors jobs for estimated completion time and adds compute resources if they can help meet SLA. If a Job can be predicted to be complete in its required SLA, then no upscaling is triggered on its behalf (even though resource utilization may be high). An extensive job with thousands of tasks will trigger a much stronger upscaling response than a small job.
- Workload Aware Scaling Limits: If an application is limited in the number of CPU resources it can use (say, because of limits put in by the administrator), it will not trigger upscaling if it is already using the maximum resources allowed.
- Recommissioning: Any upscaling requirements are first attempted to be fulfilled using any nodes currently in the process of Graceful Downscaling.
Furthermore, a composite cluster upscaling decision is taken depending on the requirements of each job running in the cluster.
Downscaling:
- Smart Victim Selection: Tasks running on each node and the amount of state on each node are considered in addition to the node launch time to determine which nodes are safe and optimal to remove from the cluster when down-scaling.
- Graceful Downscaling: All state from a node is copied elsewhere before removing it from the cluster. This includes HDFS (Hadoop Distributed File System) decommissioning and logs archival – and in cases of forced downscaling – also involves offloading intermediate data to Cloud Storage.
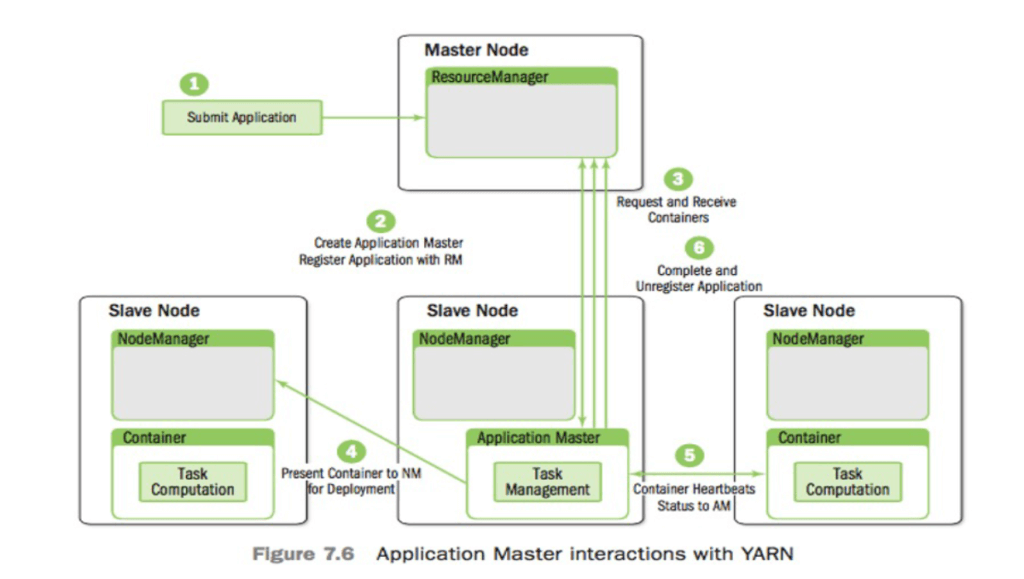
- Container Packing: Scheduling algorithms inside YARN are modified to pack tasks into a smaller set of nodes, allowing more nodes to be available for downscaling. Container packing is a new resource allocation strategy that makes more nodes available for downscaling in an elastic computing environment while at the same time preventing hot spots in the cluster and trying to honor data locality preferences.
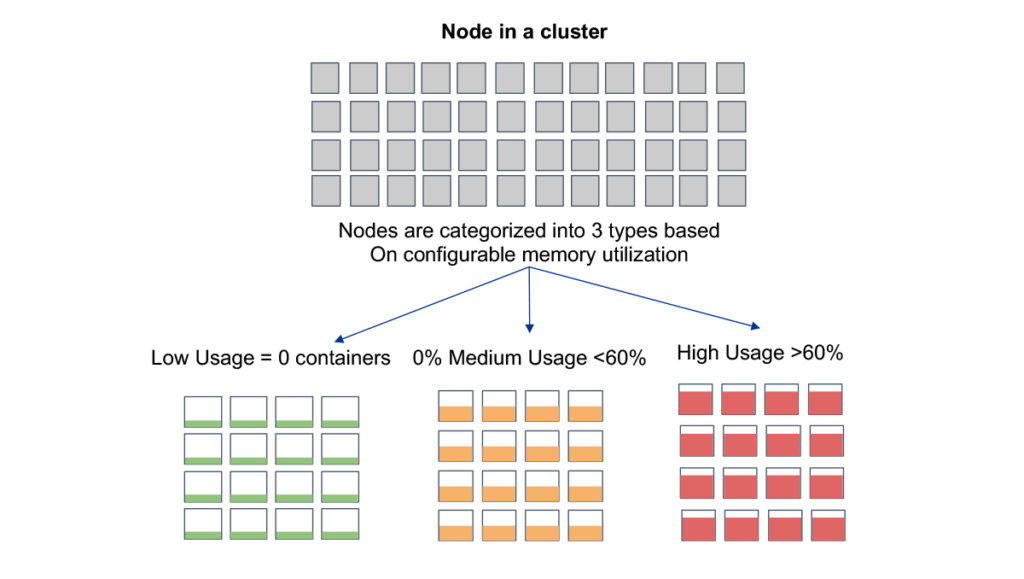
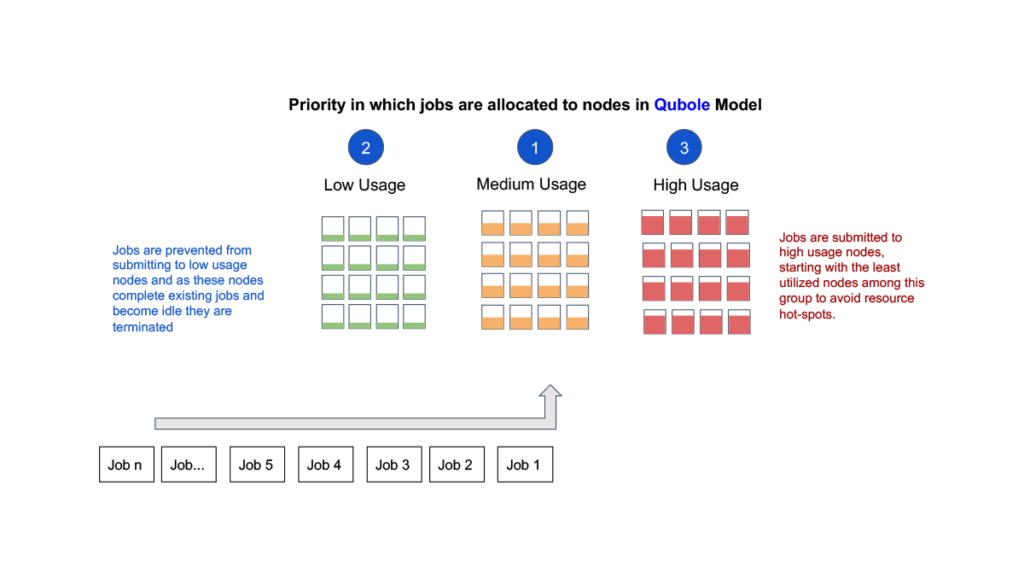
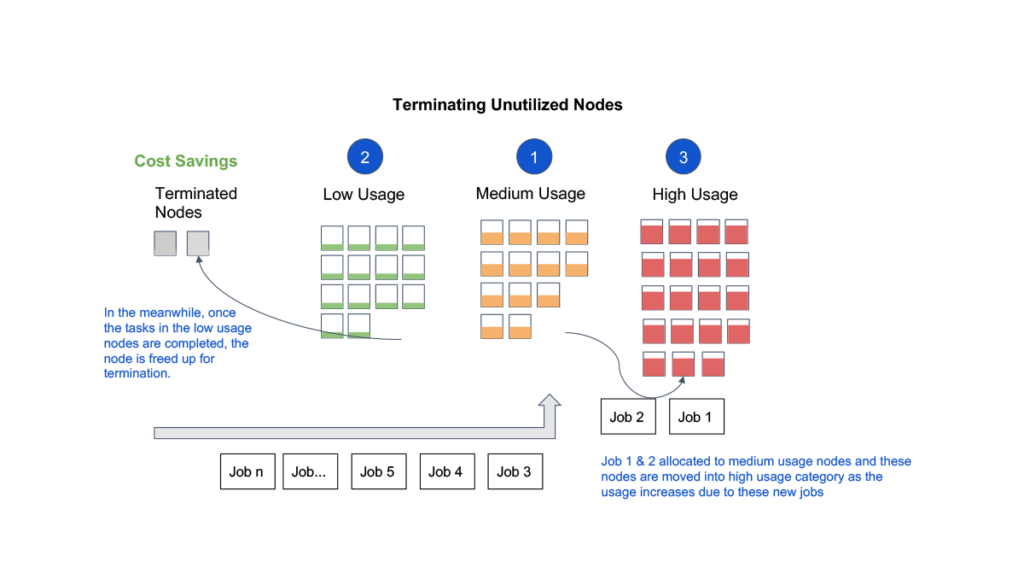
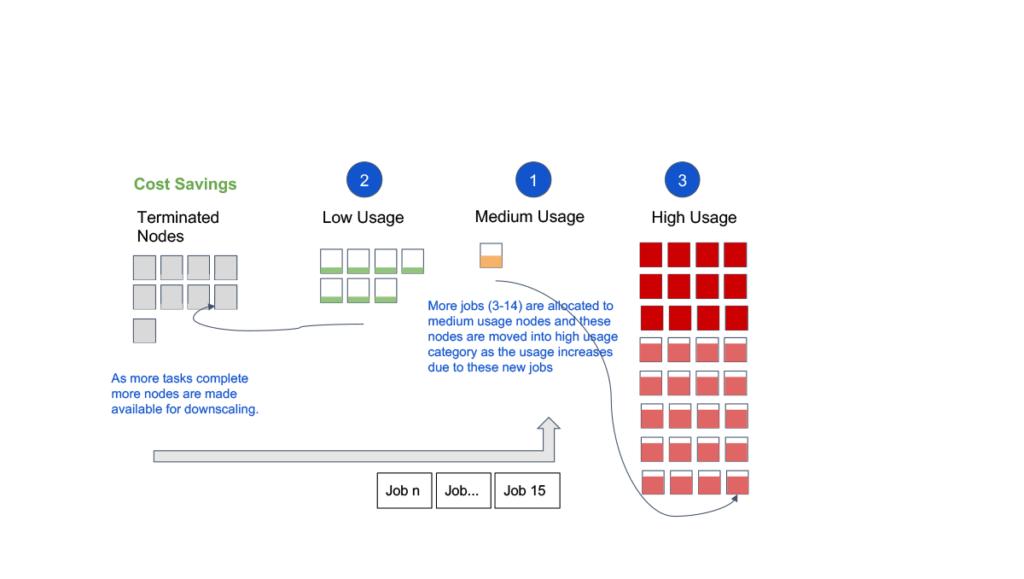
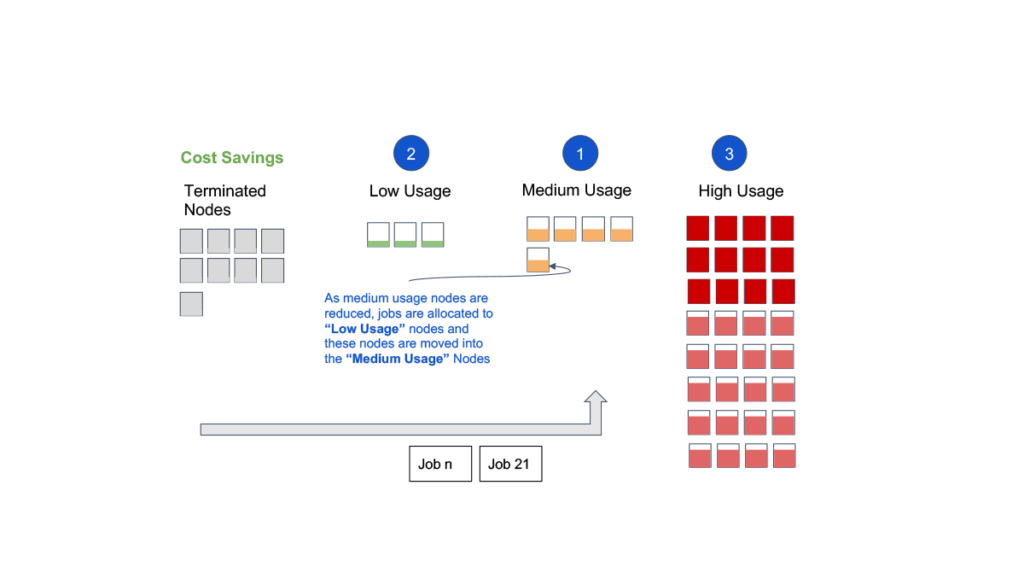
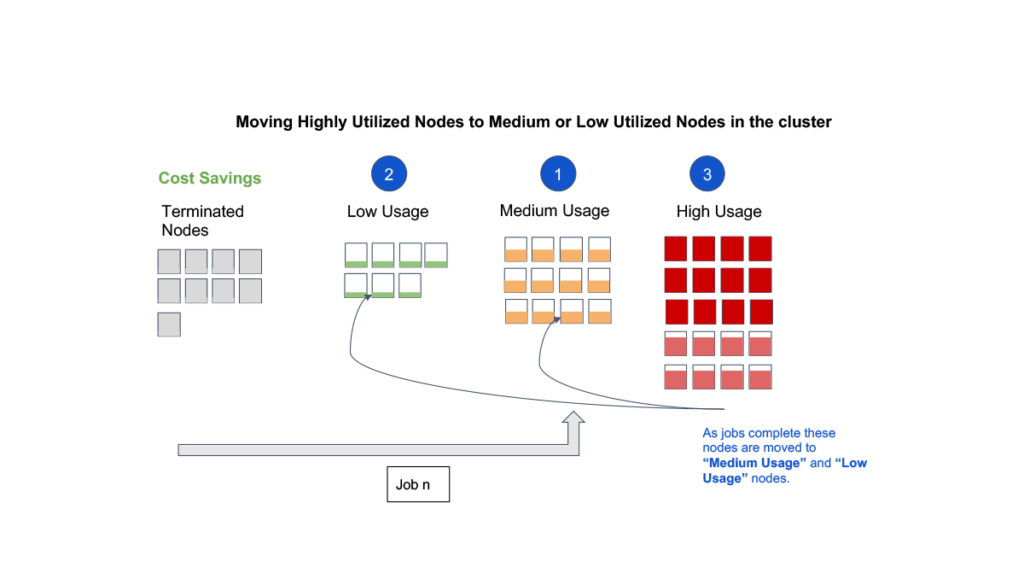
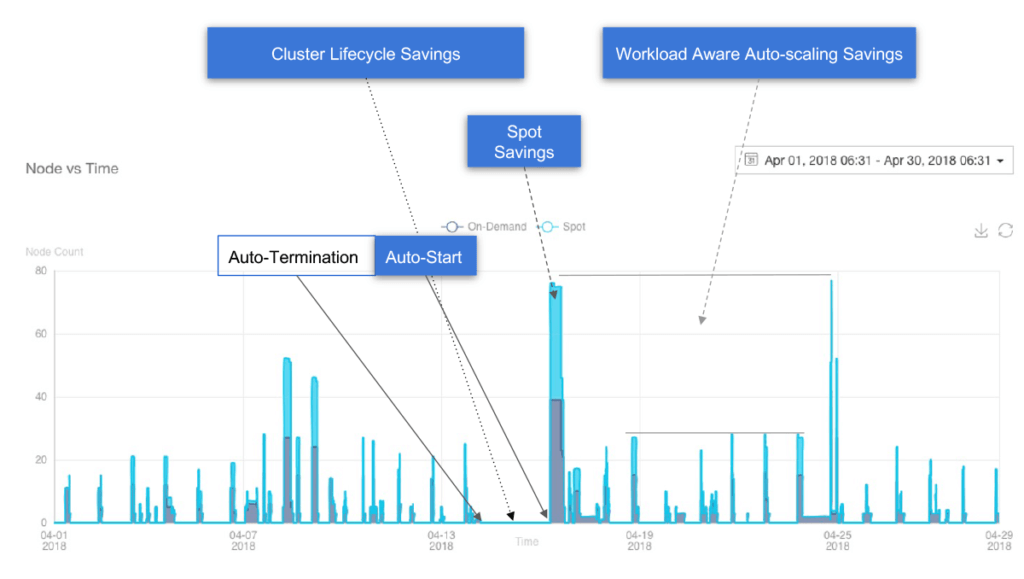
Image caption: Real-time customer clusters snapshot
Composite Health Checks
We periodically check running nodes in a cluster against their membership and health status in HDFS (distributed storage system) and YARN (distributed computing system). Nodes that don’t pass such composite health checks are automatically removed from the cluster.
Spot Loss Notification
YARN-based Hadoop and Spark clusters in Qubole can deal with Spot Loss Notifications provided by AWS. The cluster management software immediately shuts off Task scheduling on such nodes, stops further HDFS writes to such nodes, backs-up container logs on these nodes, and tries its best to replicate any state left on such nodes to other surviving nodes in the system.
Spot Rebalancing
Using Spot instances significantly reduces your computing cost, but fluctuations in the market may mean that Qubole cannot always obtain as many Spot instances as your cluster specification calls for. (QDS tries to obtain Spot instances for a configurable number of minutes before giving up.) For example, suppose your cluster needs to scale up by four additional nodes, but only two Spot instances that meet your requirements (out of the maximum of four you specified) are available. In this case, QDS will launch the two Spot instances and (by default) make up the shortfall by also launching two on-demand instances, meaning that you will be paying more than you had hoped in the case of those two instances. (You can change this default behavior in the QDS Cluster UI on the Add Cluster and Cluster Settings screens by un-checking Fallback to On-demand Nodes in the Cluster Composition section, but Qubole recommends you leave it checked.)
Conclusion
To truly take advantage of the Cloud – one has to integrate Autoscaling deep into the Big Data stack so that it is Workload-Aware. A true Cloud Native implementation also makes the Big Data stack aware of the Cloud resources and helps it adapt workload and data management in response to it.



