Cloud Computing Costs
In the current market condition, organizations require more advanced financial controls to reduce the financial risks associated with unpredictable data processing costs. Based on policy, preference, and autonomous self-learning, data teams can continue to cut costs.
Enterprises doing multiple projects with big data use public cloud services for computing and storage. The public cloud provides agility and scale to execute these projects within a few clicks and broadly match supply with demand. In addition, the cloud enables enterprises to build and run the best-breed big data processing systems. The services offered are all on-demand, pay-as-you-go services, therefore, allowing ad-hoc analysis and POCs driven by big data to start easily and without any huge upfront bills. Over time as projects mature or ad hoc queries become longer, the seemingly endless supply of underlying resources leads to wasteful expenditure on computing and resources and very little accountability, and guesstimates show back. The usage comes with cost unpredictability and lacks financial governance.
Cloud-native data platforms are working to change this mindset. They remove the need to understand the underlying infrastructure by providing an interface that is focused on understanding the data needs and then efficiently creating and destroying the amount of infrastructure needed to provide a shared environment that can deliver the required functionality.
Data Lake Platforms like Qubole’s built-in financial governance capabilities provide instant visibility into the platform usage costs using advanced tools for budget allocation, show back, and monitoring and controlling cloud compute spend.
Data Lake Financial Governance
Organizations need cost optimization for various reasons. Some of the major aspects are:
- Minimize Risks: To avoid any unnecessary expenses and mishaps, organizations need to create a risk-free environment by creating a cost-optimization strategy.
- Minimize Costs: Cost minimization helps teams in reducing costs which may include the profit share affecting the workplace.
- Maximize Business Value: It helps organizations stay one step ahead of their competitors by decreasing time to market & promoting innovation.
Cost optimization is the continuous process of maximizing business value through a business-focused drive to fully utilize resources and minimize costs by reducing sources of wasteful expenditure, underutilization of resources, or low return in the company’s IT budget both in the cloud and data centers. The practice aims to invest in new technology to speed up business growth or improve profit margins by maximizing savings and meeting business requirements. It includes:
- Obtaining the best pricing and terms across business purchases to procure more resources for less
- Standardizing, simplifying, and rationalizing platforms, applications, processes, and services
- Automating and digitizing IT and business operations to reduce mismanaged or excess resources
- Align delivery of service to specific workloads and applications with the best customer experience
Spot vs Preemptible VMs
Both Spot and Preemptible instances provide an excess compute capacity due to which their availability varies with usage.
Spot nodes are fixed, and adjusted based on the trends of the demand and supply capacity. They help organizations to run ad-hoc analytics and data exploration workloads at a cheaper price. Spot instances are significantly cheaper than their on-demand counterparts by yielding up to 80 percent of cost benefits. However, one major disadvantage of the loss of spot nodes like Amazon Spot instances or Google Preemptible VMs is that it increases the risk of data loss or job slowdown for organizations that are looking to optimize big data costs. Spot nodes require careful management in instances where bursty data workloads need to be scaled instantly.
Qubole’s handling of Spot loss notifications enables users to balance performance, cost, and SLA requirements. Organizations can automate and optimize their usage of spot nodes while maintaining reliability through re-balancing, proactive autoscaling, fault tolerance, and risk mitigation. With Qubole, organizations are leveraging spot nodes without worrying about job loss while increasing their resiliency with re-balancing, intelligent planning, and quick job recovery.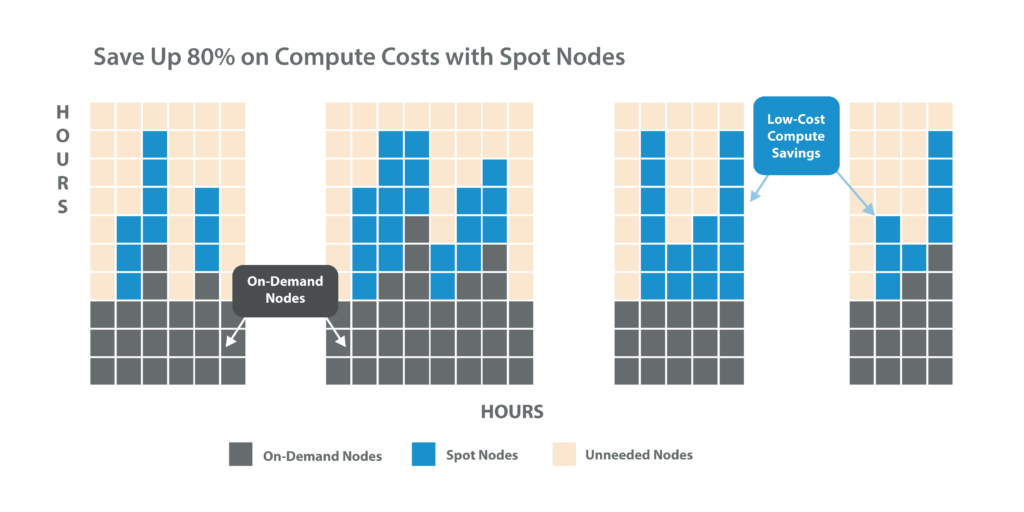
Cluster Autoscaling
As a critical component of cloud computing deployment, autoscaling is a mechanism that provides users with a dynamic approach to increase or decrease the computing, memory, or networking resources to handle the workloads as traffic spikes. The overall benefit of autoscaling is that it adds resources automatically when computing or storage demand increases while keeping the number of nodes at a minimum in real-time to process users’ needs efficiently.
Qubole’s workload-aware autoscaling defines the awareness of workload, job priority, and SLA while estimating the number of nodes required depending on the real-time workloads running in the cluster. It adapts to the bursty nature of ad-hoc analytics and data exploration workloads using machine learning (ML) algorithms. These ML models help in defining if and when to scale up or down, predicting whether or not a job will complete in its designated time or with the assigned priority. Qubole’s aggressive downscaling leverages intelligent self-learning algorithms to balance workloads across active nodes and decommission idle nodes. It prevents data loss and cluster performance degradation while drastically reducing the amount of time spent in a state of transition.
Being Workload Aware has dramatically improved Qubole’s ability to orchestrate Hadoop and Spark in the cloud. Take a look at how the platform has leveraged this awareness:
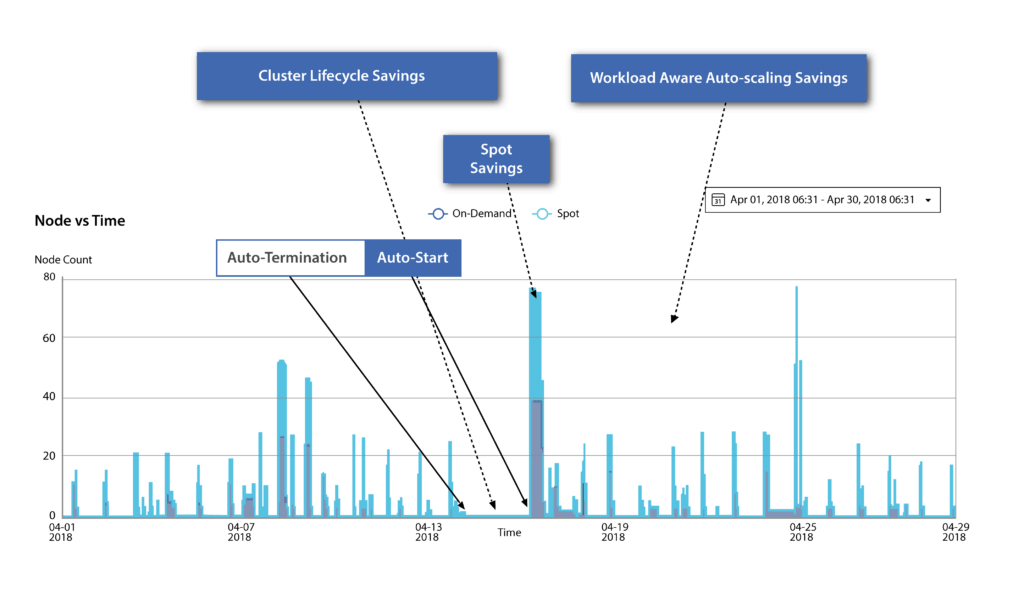
Cluster Lifecycle Management
The Cluster Lifecycle Manager (CLM) creates, updates, and deletes clusters. It interacts with a Cluster Registry and a configuration source that helps in reading information about the clusters while updating them with the latest configuration. CLM can launch clusters either directly from the development machine or as a controller running a single instance. One major benefit of CLM is that it auto-starts, auto-terminates, and rebalances clusters safely without data loss.
Qubole provides automated platform management for the entire cluster lifecycle. CLM maintains a cluster’s health by carefully configuring, provisioning, monitoring, scaling, and optimizing them. Depending upon the workload, it automatically self-adjusts and proactively monitors the cluster performance.
When there are no active jobs, Qubole automatically deprovisions a cluster and shuts it down avoiding the risk of data loss. With Qubole’s Cluster Lifecycle Management, an administrator can support 200 or more users and process 10 times the amount of data that their previous infrastructure supported.
Big Data Processing Costs
Qubole is an open data lake company that provides a simple and secure data lake platform for machine learning, streaming, and ad-hoc analytics. With the help of data lake services, the platform reduces time to value and lowers cloud data lake costs by over 50 percent. With Qubole, you can instantly start leveraging data and insights to derive business value by delivering self-service access to multiple data sets in your data lake across groups.
Qubole Cost Explorer
Qubole’s powerful automation empowers administrators to control their spending by optimizing resource consumption, deploying lower-priced resources, eliminating redundant resource consumption, and throttling queries based on monetary limits. The platform also provides governance through intelligent automation capabilities such as workload-aware autoscaling, intelligent spot management, heterogeneous cluster management, Qubole Cost Explorer, and automated cluster lifecycle management.
Qubole Cost Explorer helps organizations monitor, manage, and optimize big data costs by providing visibility of workloads at the job, cluster, and cluster instance levels. It also helps enterprises in achieving a financial governance solution to monitor their workload expenditures using pre-built and customizable reports and visualizations.
Monitor Big Data workload spend with pre-built and customizable reports and visualization
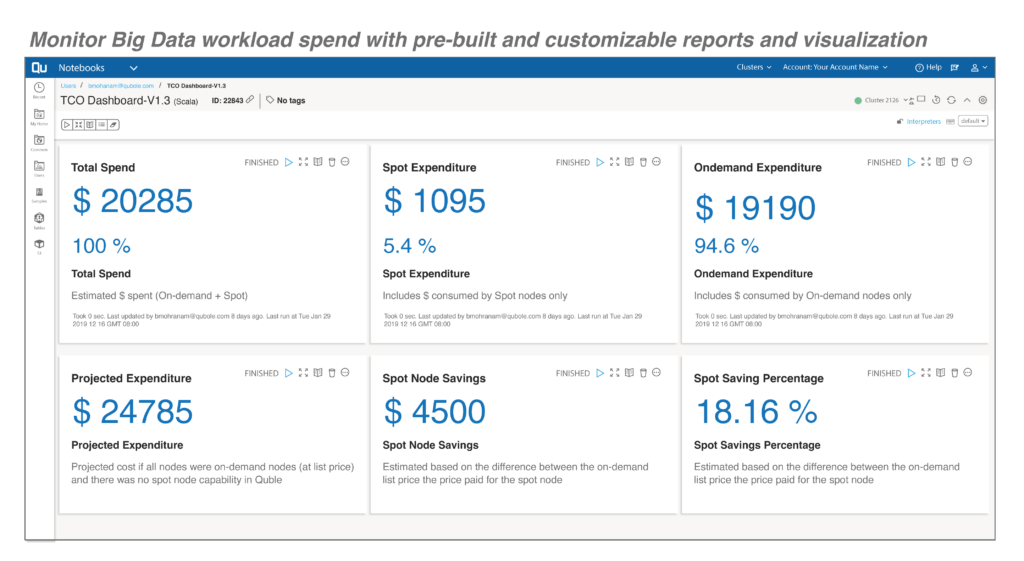
With Cost Explorer, data teams can:
- Spend Tracking: Regularly track both Qubole and cloud spend on various assets
- Build ROI Analysis: Calculate the amounts spend on use cases to calculate the return on investments
- Monitor Showback: Showback costs incurred by various teams/business units
- Optimize Opportunities: Identify top spending assets to further reduce TCO
- Plan and Budget: Estimate the future spending based on past Job/User level costs
- Justify Business Cases: Show savings on operating costs to the finance team
Irrespective of the lifecycle stage or bursty nature of typical analytics and machine learning use cases, Qubole Cost Explorer provides data that can help you build the structure of an effective Financial Governance. On average, Qubole customers are able to onboard over 350 users in months and use an average of 1.5 million compute hours across multiple use cases.
Qubole
Qubole helps organizations save huge amounts of money with built-in platform capabilities and sustainable economics that allow your infrastructure to automatically scale up or down as per one’s requirement. It increases the resiliency of your spot nodes, accelerates your time to value, and automates the management of the cluster lifecycle.
The top five ways in which organizations are leveraging Qubole’s cloud data platform facilities are:
- Isolate workloads in different environments and different clusters
- Isolate user workloads in different clusters
- Automatically stop clusters when not required
- Leverage a high percentage of Spot nodes with heterogeneous nodes in clusters
- Use auto-elasticity of cluster
To summarize, Qubole is helping organizations regain control of costs for Big data processing in the cloud and succeed at their goals and business initiatives without overpaying.



