
Background
One of our goals at Qubole is to make an analysis of large data sets simple and optimal – especially in cloud environments. In our experience working with data analysts and engineers, we observed a common pattern. During the query authoring phase, analysts end up writing a number of ad-hoc queries as part of an iterative process. In many cases – the iteration stops when the desired analysis has been completed. In others – the next step is to create a periodic job that pre-materializes these results for faster access (typically via data visualization tools). The ability to iterate rapidly while authoring queries is critical for effective data analysis.
Issues
Unfortunately – complex queries on large data sets can often take a long time to run. We have also seen that in the initial phases of an analysis or project, analysts are often looking for quick and dirty results to make sure the queries are formulated correctly. In many cases, approximate results suffice – an analyst may be quickly trying to verify a trend or a distribution rather than produce a formal report for example. Unfortunately, it is hard to express this intent in languages such as HQL (Hive’s extension of SQL). Hive is not designed to inform an analyst upfront about the potential cost of a query.
The massive parallelism in Big Data systems often hides the true cost of a query from the author – but can simultaneously degrade the experience of other users using the same shared hardware resources. In the Cloud – this cost directly translates to dollars spent. Qubole’s Data Platform seamlessly scales clusters up and down – but expensive queries will cost more – and often transparently so. As part of the Qubole Data Platform – we have tried to address these issues holistically in the context of HQL. Our browser-based query authoring interface – QPAL – offers analysts simple checkboxes and form elements by which they can express their desire to perform approximate or test queries (instead of complex SQL extensions). A few key features in this area are discussed below in the rest of this blog post.
Expression Evaluator
When working with unstructured and semi-structured data users often have to write complex expressions to extract data – Examples include string manipulation functions (regular expressions, substr, instr, etc.) and JSON expressions. Getting these right can be tricky and a wrong expression may end up returning unexpected results. As part of our system, we maintain a sample of the data in a fast store and allow users to evaluate many common Hive expressions on this sample. The feedback in this case is instantaneously allowing users to refine their expressions very quickly. This allows users to converge on the right expressions much more quickly.
Test Mode Query Run
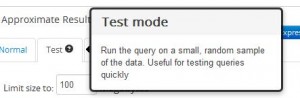
Test mode allows an analyst to run a query on a sample set of data. This use case is meant for the scenario where the analyst may be iterating while trying to author the desired query. The user can specify the size of data to run the query on. In the current default setting of a sample size of 100MB – these queries are complete in a few seconds. While this mode is similar in intention and design to the TABLESAMPLE clause in Hive – there are a few important differences:
- Table Sample allows users to only specify percentages of the total dataset to sample, rather than the absolute value. This can be problematic when the size of the dataset is not known.
- There is currently no way in the hive to specify sampling for all the tables in a query. The table Sample clause has to be specified separately for each table used in the query.
- The TableSample clause is fairly complex – especially when it needs to be applied over multiple tables. For analysts unfamiliar with the syntax – thinking about it and getting it right is a distraction from the original goal to come up with the best query. By contrast in QPal – the analyst can just click on a checkbox to run a query in test mode.
Constrained Mode Query Run
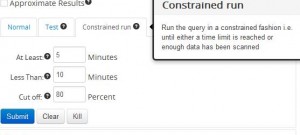
While the sample size is an important and interesting metric for limiting query execution, what users really care about is the time it takes to complete a query. When iterating over queries, it is sometimes acceptable to have partial results as long as the query returns within certain time bounds. Our system allows you to run Hive queries in such a mode – The end-user can specify:
- The minimum time period for which a query should run
- The maximum time for which a query should run
- An upper limit for the percentage of scanned data
Using these constraints the system will run the query for at least the minimum time period, and once that time period has finished it will terminate the query when either the maximum time limit has been hit or enough data has been scanned. The query will then return any results available. Currently, we apply these heuristics to only the map tasks – assuming that constraining the mappers limits the amount of work required to be done in the reducers as well.
Approximate Mode Query Run

Certain aggregate functions – namely count(distinct) in HQL – are very expensive.
If the number of distinct keys is large (as is often the case when counting distinct users of a website for example) – each mapper ends up emitting at least one row per distinct value. To make these queries go much faster we have implemented an approximate count distinct implementation (see reference [1]).
Under the hood, we convert all count(distinct) expressions in the query to count_approx if the end-user selects the “Approximate Results” checkbox on the QPAL query authoring wizard. count_approx implements the adaptive counting algorithm and is faster because it aggregates all the distinct values for a group on the map side in a data structure that can be merged efficiently with the output of other mappers during the reduce phase.
By implementation, the run time of count distinct is in the order of (cardinality of group-by x cardinality of distinct values to count on), but by using count_approx the run time of counting becomes almost independent of the cardinality of distinct values in each group-by.
To prove our assertions we created datasets with all distinct integer values and ran “select count(distinct)” and “select count_approx” queries on these datasets. The following figures show the difference in run times of count approx and count distinct and the % error introduced by using count approx.
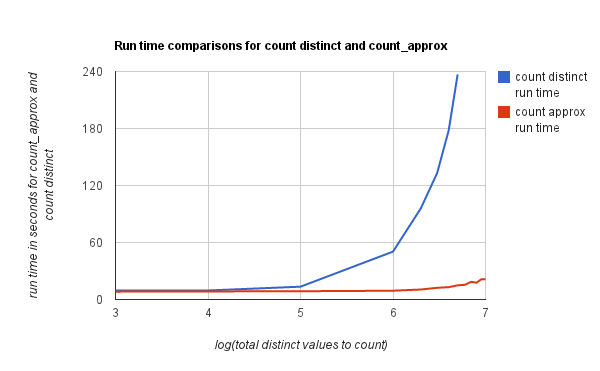
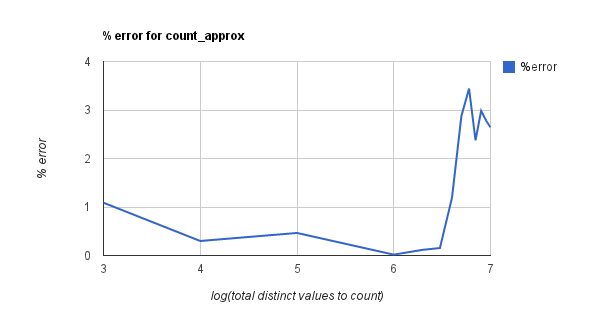
Note that in the above experiments, there was no group-by-clause. Similar experiments with a group-by clause on another column with a cardinality of about 150 yielded similar results in terms of run time. All the experiments were done in the local mode using hive cli.
Conclusions
One of the visions behind Qubole is to bring Map-Reduce and the power of the Cloud to the desk of a data analyst. While much more work remains, we have attempted to address some of the fundamental problems in authoring queries rapidly in this realm – and this post has detailed our work in implementing approximate run modes to Hive and making them easily accessible to an analyst. Qubole Data Service is now generally available – users can signup for a free account and get access to these and other cool and usable technologies. In the future – we look to extend our work with the sampled data to allow full-fledged and fast hive queries against small data sets. Much more work also remains in modifying Hadoop to remove extraneous overheads in the current constrained mode implementation.
References
[1] Fast and Accurate Traffic Matrix Measurement Using Adaptive Cardinality Counting Min Cai, Jianping Pan, YuKwong Kwok, Kai Hwang, SIGCOMM ’05
[2] StreamLib
P.S. – We are also hiring and looking for great programmers to help us build stuff like this and more. Drop us a line at [email protected] or head to our Careers page for more details.



