This is a guest post by Evan Harris, Data Scientist, Return Path
At Return Path, I work on a data science team that uses machine learning and natural language processing to produce features that augment data feeds that we sell directly to clients. Return Path’s core business is in email marketing optimization. In a nutshell, we use data and analytics to help marketers optimize how and when they’re sending emails to their customers. While this is Return Path’s core business, I work in a division of the company that focuses on consumer insight data.
Doing this work in the cloud has made our data science team more effective. The transition to the cloud included certain challenges, but the benefits of infinite scaling and self service ops has made it worth it.
Our Cloud Transition
We went through what could be termed a classic cloud transition. We had a fully co-located, in-house managed Hadoop cluster that was a fixed size and shared ad-hoc and production workflows. Our decision to transition to the cloud was a big game-changer for everyone, especially the less technical analytics and data science teams that don’t have strong computer science and data engineering backgrounds.
Through our “classic” cloud transition, we faced what I am coming to learn are quite “classic” challenges. While platform providers are continually working on making these common challenges easier to overcome, what ultimately got us through the process was pure grit. There was a certain amount of frustration and confusion, but we were able to learn fast and work hard through the transition while still supporting our product, which is a serious challenge. Bringing your entire infrastructure from one paradigm to another while preventing this process from being visible to customers is difficult. The hard work was worth it, and we’re now running efficiently in the cloud.
What We Learned
While every cloud transition is likely to have its bumps, we learned a few things in our experience that could make the process easier had we known them from the beginning. It sounds obvious, but one of the most important things we learned is to simply embrace technology. It’s tempting to avoid rocking the boat and jumping on every new technology that appears, but the future is moving fast and the only way to keep up is to not fear change and new technology but to embrace it.
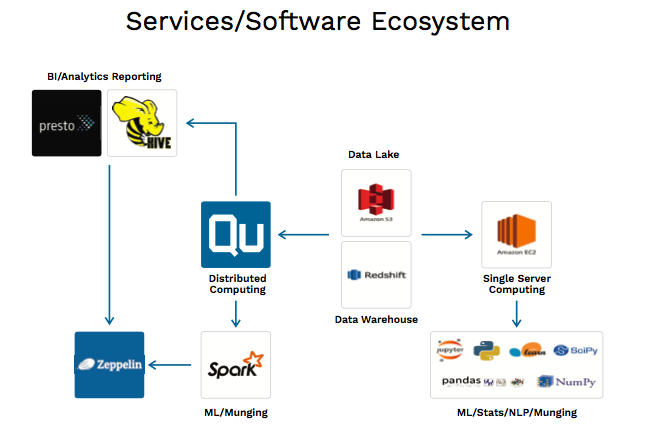
Another important lesson from our transition is to embrace the cloud’s multi-engine potential for building a “tool belt” rather than seeking out the single magic bullet tool that will perfectly address your use cases. By experimenting with and learning about all the tools that are available, teams can much more easily find the right tool—or combination of tools—for each job. Every use case is slightly different than the next, and in most cases, the best solution will not come from applying a one-size-fits-all approach, but rather a tailored one.
Sharing Lessons and Best Practices at Data Platforms 2017
We’re lucky that we work in a field where sharing knowledge and best practices is a given. In the open-source spirit of advancing technology, conferences like Data Platforms are popping up to allow us to learn from each other. I’m all in favor of this sharing, which is why I was excited to present the key lessons learned from my team’s cloud transition at Data Platforms 2017.
What I discussed in the talk is the idea that you can be much more productive, independent, and waste less time waiting for resources from data engineering and data ops when you operate a data science team using the right modern big data tools to work the entire stack. With these tools in hand, and an investment in education and training for data scientists, building end-to-end data features and products becomes within reach of a data science team.
This includes everything from storage and building out your own ETL and data pipelines, to integrating machine learning models directly into those pipelines, and ultimately doing something with the output of those models—and doing all that entirely within the cloud. It’s very empowering to get to a place where, as a data science team, you can effectively and efficiently build product.
It is true that there are many challenges for data scientists and analysts to operating efficiently in the cloud. These challenges include the need to have a good understanding of distributed computing, a good background in computer science, and an effective way of thinking about data storage, batching, and streaming data. Many data scientists come from a background dominated by working on their own laptop or a single persistent remote server, using IDEs and other local tools to build prototypes and proofs of concept with sampled data. While this kind of background serves many use cases, working on large data sets with distributed computing all in the cloud with ephemeral hardware can benefit from some additional training and accumulation of experience. By investing in a little bit of education and the right tooling, as well as simply jumping right in and experimenting with cloud tools, these challenges can be overcome.
While there are significant barriers today for analysts and data scientists without strong computer science backgrounds, emerging technologies are smoothing the path for the new users of the near future.
Here is my presentation at Data Platforms 2017:
Making Big Data in the Cloud Easier
One path-smoothing technology on the horizon that will go far in reducing barriers is serverless computing. With serverless computing, when you have a query or code you want to run, you don’t need to know anything about what’s going on on the back end in, terms of hardware, to make that code or query run. Currently, a major barrier for users is that they must have an in-depth understanding of the kinds of hardware resources they need to employ to ensure jobs finish properly in a cost effective way.
Another is the idea of intelligent data storage, where AI can be used to help teams better store and partition their data based on the kinds of jobs that they run. This could eliminate the need for individuals to spend time optimizing data partitioning, database table structure, and file compression types. Software that either makes suggestions to administrators or even takes action autonomously could lower another barrier for data science teams to fully manage their own data storage.
Emerging technologies that make running queries and code easier for non-technical users will make it much easier for analysts of all backgrounds to get answers from data. These advances will help make real not only the democratization of data, but the democratization of hardware as well, which is a critical and sometimes overlooked aspect of the whole big data democratization picture.
Serverless computing and intelligent data storage are just some of the useful technologies of the future that is fast approaching, and that we must not be afraid to embrace. While our data platform is now fully migrated to the cloud and is stable and efficient, I have no illusions that we’re “done.” In fact, our cloud transition is just the latest step in an ongoing and accelerating process of new technology adoption.



