What is Apache Airflow?
Apache Airflow is one of the most powerful platforms used by Data Engineers for orchestrating workflows. Airflow was already gaining momentum in 2018, and at the beginning of 2019, The Apache Software Foundation announced Apache® Airflow™ as a Top-Level Project. Since then it has gained significant popularity among the data community going beyond hard-core data engineers.
Airflow ETL
Today, Airflow is used to solve a variety of data ingestion, preparation, and consumption problems. A key problem solved by Airflow is Integrating data between disparate systems such as behavioral analytical systems, CRMs, data warehouses, data lakes, and BI tools which are used for deeper analytics and AI. Airflow can also orchestrate complex ML workflows. Airflow is designed as a configuration-as-a-code system and it can be heavily customized with plugins. That is why it is loved by Data Engineers and Data Scientists alike.
Airflow Workflows
In 2016, Qubole chose Apache Airflow to provide a complete Workflow solution to its users. Since then Qubole has made numerous improvements in Airflow and has provided tools to our users to improve usability. Qubole provides additional functionality, such as:
- DAG Explorer (Which helps with maintenance of DAGs — Directed Acyclic Graphs)
- Git Integration
- Monitoring via Prometheus and Grafana
- Log Backup and Sync to Cloud Storage
- Enterprise-level Cluster Management dashboard
- Anaconda based Python Package Management
- Seamless Authentication via Qubole
- and more…
Apart from that, Qubole’s data team also uses Airflow to manage all of their data pipelines. Qubole engineers and users have always felt the need for a single source of information on Airflow, with quality content all the way from beginner, intermediate to advanced topics. This is the first of a series of blogs in which we will cover Airflow and why someone should choose it over other orchestrating tools on the market.
Airflow DAG
From Airflow’s Website:
“Airflow is a platform created by the community to programmatically author, schedule and monitor workflows.
So Airflow provides us with a platform where we can create and orchestrate our workflow or pipelines. In Airflow, these workflows are represented as DAGs. Let’s use a pizza-making example to understand what a workflow/DAG is.

Workflows usually have an end goal like creating visualizations for sales numbers of the last day. In this case, we want to bake a Pizza.
Now, the DAG shows how each step is dependent on several other steps that need to be performed first. Like, to knead the dough you need flour, oil, yeast, and water. Similarly, for Pizza sauce, you need its ingredients. Similarly, to create your visualization from the past day’s sales, you need to move your data from relational databases to a data warehouse.
The example also shows that certain steps like kneading the dough and preparing the sauce can be performed in parallel as they are not interdependent. Similarly, to create your visualizations it may be possible that you need to load data from multiple sources. Here’s an example of a Dag that generates visualizations from previous days’ sales.

Is Airflow an ETL Tool?
Now that we know what Airflow is used for, let us focus on the why. There are a good number of other platforms that provide functionalities similar to Airflow, but there are a few reasons why Airflow wins every time.
Community
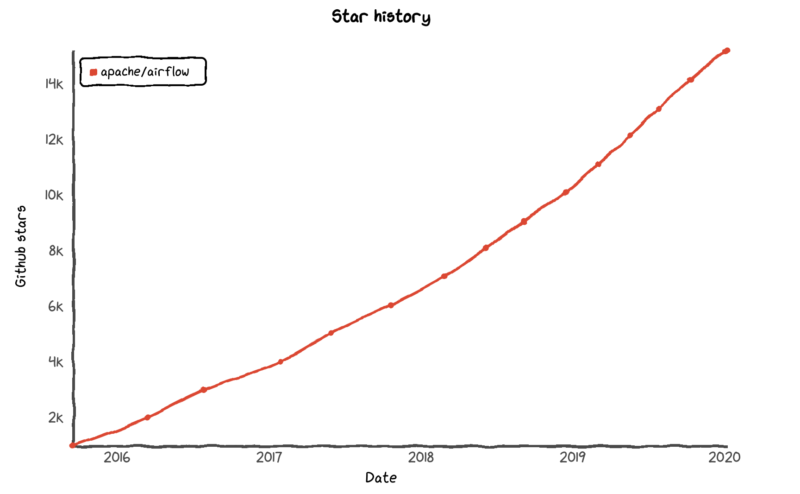
Airflow was started back in 2015 by Airbnb. The Airflow Community has been growing ever since. We have more than 1000 contributors contributing to Airflow and the number is growing at a healthy pace.
Extensibility and Functionality
Apache Airflow is highly extensible, which allows it to fit any custom use case. The ability to add custom hooks/operators and other plugins helps users implement custom use cases easily and not rely on Airflow Operators completely. Since its inception, several functionalities have already been added to Airflow. Built by numerous Data Engineers, Airflow is a complete solution and solves countless Data Engineering Use Cases. Although Airflow is not perfect, the community is working on a lot of critical features that are crucial to improving the performance and stability of the Airflow platform.
Dynamic Pipeline Generation
Airflow pipelines are configuration-as-code (Python), allowing for dynamic pipeline generation. This allows for writing code that creates pipeline instances dynamically. The data processing we do is not linear and static. Airflow models more closely with a dependency-based declaration as opposed to a step-based declaration. Steps can be defined in small units, but that breaks down quickly as the number of steps becomes larger. Airflow exists to help rationalize this modeling of work, which establishes linear flow based on declared dependencies. Another benefit of maintaining pipelines using code is that it allows versioning and accountability for change. Airflow lends itself to supporting roll-forward and roll-back much more easily than other solutions and gives more detail and accountability of changes over time. Although not everyone uses Airflow this way, as your data practice evolves, Airflow will evolve along with you.
So, that’s a quick tutorial on Apache Airflow and why you should be interested in it. For further reading, see Understanding Apache Airflow’s Modular Architecture.



