With the rapid adoption of Apache Spark at an enterprise level, now more than ever it is imperative to secure data access through Spark, and ensure proper governance and compliance.
Spark is a popular big data cluster computing framework typically used by Data Engineers, Data Scientists, and Data Analysts for a wide variety of use cases. Depending on the case, each user type will require a range of data access privileges. Unlike other big data engines like Presto which have built-in authorization frameworks with fine-grained access control, Spark gives direct access to all tables and resources stored in the Qubole Metastore (which leverages Apache Hive). This not only presents security concerns but hinders growth and enterprise adoption. Hence, there was a strong case for us to introduce a new Spark Data Access Control Framework on the Qubole platform.
Goals
These are some of the most important design goals considered for introducing the Spark Access Control Framework:
- Fine-grained access control should be uniformly applied across various big data engines.
- Policies must be viewed or edited through any engine to provide consistent and predictable behavior.
- Support SparkSQL access methods, such as Dataframes or SQL statements.
- The framework must be easy to integrate with various Policy Managers like Hive Authorization or Apache Ranger.
Implementation Details
With these requirements in mind, we decided to implement Hive Authorization as our first Policy Manager. Hive Authorization policies are stored in the Qubole Metastore which acts as a shared central component and stores metadata related to Hive Resources like Hive Tables. We enhanced Spark to honor the policies stored in the Qubole Metastore while accessing Hive Tables or for adding and modifying those policies.
In summary, we implemented a SQL standard access control layer identical to what is present in Apache Hive or Presto today. The following sections detail the architecture and provide an example that illustrates how it works.
Architecture
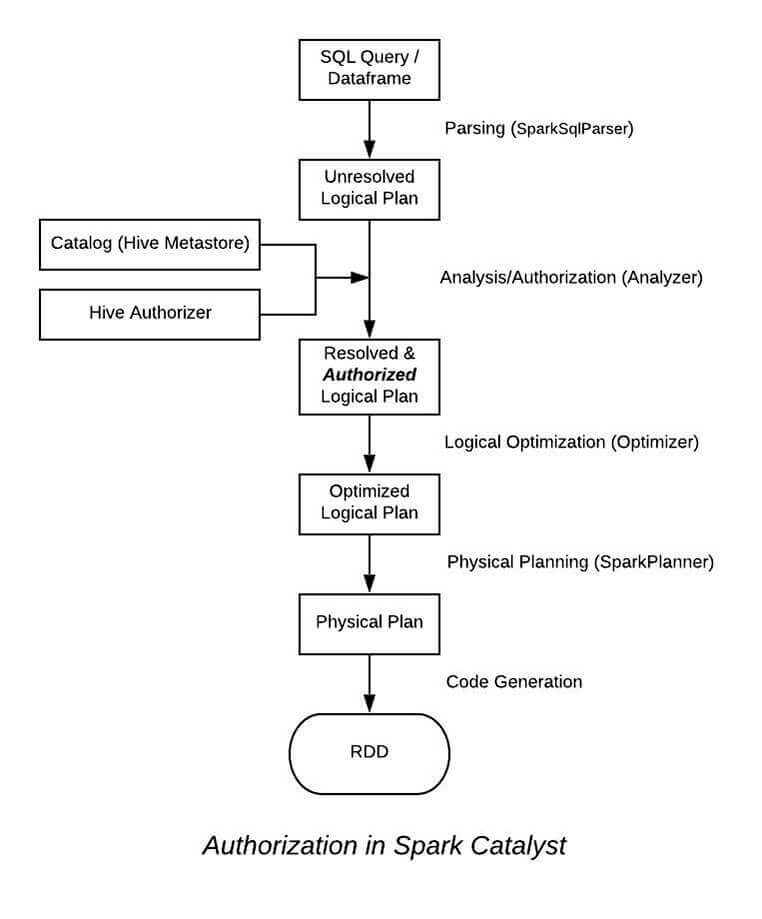
The authorization logic is embedded inside the Analyzer layer of Spark’s Catalyst Framework. Analyzer’s rules are responsible for resolving entities like “Databases”, “Tables” and “Columns.”. The information about different resolved entities is extracted from the plan and passed on to the Hive Authorizer which already has information about the user. The Hive Authorizer then performs a resource level check with the security policies present in the Qubole Metastore and halts the execution of the query if the user lacks privileges for running the query by throwing a HiveAccessControlException.
Restricting Table-Level Access
1. Assume we have a Hive table ‘payroll’ with the following definition:
sql> DESCRIBE payroll; +---------+---------+-------+ | col_name|data_type|comment| +---------+---------+-------+ | emp_id| int|null | | emp_name| string|null | | salary| int|null | |dept_name| string|null | +---------+---------+-------+
For data governance purposes, user ‘Jane’ who belongs to the finance team should be allowed to access the table, and user ‘Robin’ from IT should be restricted from accessing the table.
2. Any user belonging to the `admin` role can follow the below steps to restrict access to this table:
- Create a new role and grant this role to users that should have access to the table, in this case to the user ‘Jane’.
(User) sql> SET ROLE admin; (User/Admin) sql> CREATE ROLE finance; (User/Admin) sql> GRANT finance TO USER Jane;
- `Select` privileges are provided to the role `finance`.
(User/Admin) sql > GRANT SELECT ON payroll TO ROLE finance;
3. When ‘Jane’ accesses the table after assuming all the roles she is granted through the `SET ROLE ALL` command, the following results are displayed –
(Jane) sql> SET ROLE ALL; (Jane/Finance) sql> SELECT * FROM payroll; +------+--------+------+-----------+ |emp_id|emp_name|salary|dept_name | +------+--------+------+-----------+ | 1|Achuth | 1234|Engineering| | 2|Jane | 2345|Finance | | 3|Robin | 3456|IT | +------+--------+------+-----------+
4. When ‘Robin’ or any other user who is not granted the `finance` role tries the same flow, we can expect a HiveAccessControlException –
(Robin) sql> SET ROLE ALL; (Robin/IT) sql> SELECT * FROM payroll; org.apache.hadoop.hive.ql.security.authorization.plugin.HiveAccessControlException: Permission denied: Principal [name=Robin, type=USER] does not have following privileges for operation QUERY [[SELECT] on Object [type=TABLE_OR_VIEW, name=default.payroll]]
Restricting column and row access
Advanced use-cases like restricting column or row access can be achieved through views. For example, consider we have a new role called `finance_intern` which does not have access to the `salary` column in table ‘payroll’ and can only access rows associated with the `Finance` department.
- Like before, any user belonging to the `admin` role can create a new view with three columns (`emp_id`, `emp_name`, `dept_name`), add a filter on `dept_name` and provide the role `finance-intern` access to this new view instead of the base table.
(User) sql> SET ROLE admin; (User/Admin) sql> CREATE VIEW payroll_view AS SELECT emp_id, emp_name, dept_name FROM payroll WHERE dept_name = 'Finance'; (User/Admin) sql> GRANT SELECT ON payroll_view TO ROLE finance_intern;
- Users with the `finance_intern` role assigned can assume the role and access the view. The result would be as follows:
(User) sql> SET ROLE finance_intern; (User/finance_intern) sql> SELECT * FROM payroll_view; +------+--------+---------+ |emp_id|emp_name|dept_name| +------+--------+---------+ | 2|Jane |Finance | +------+--------+---------+
- Since access to the base table is not granted to this role, we would get a HiveAccessControlException if the user tries to access the unauthorized data.
Conclusion
With the introduction of a Spark Access Control Framework in Qubole, customers now have the same security and access control capabilities when running queries with SparkSQL, as with Presto or Hive. This unified security layer across engines provides enterprise-grade consistency and governance, as customers can centralize their access control policies in the Qubole Metastore for their Spark workloads.



