Cloud deployments for big data, exploit the traditionally diametrical benefits of performance and cost savings, and demand elasticity of the data storage and computing part of data architecture. The first part of this two-part article introduced Crazy Galactic Auctions (CGA) a fictitious company, which crawls auction websites for product information and prices.
CGA has to scale its architecture due to a growing business and resulting increase in data processing and storage. They currently manage a small, in-house Hadoop cluster and MongoDB store. The uncertainty around the size of the expected growth put CGA’s focus on public cloud deployment. They hope to reduce the operations effort and free developers, scale as needed, and make data more accessible across the company.
Beware of vendor lock-in
The previous part explored the access patterns and data structure used by CGA and how they could reduce their operational burden by switching to a managed Cassandra or Amazon Webs Services (AWS) DynamoDB database. Both are viable solutions so CGA decided to explore their computing demands to inform if a cloud deployment is desirable and if it influences the choice of data stores.
DynamoDB is very appealing for its minimal operational effort. The administration is limited to deciding how much throughput is required. This simplicity comes with a certain degree of lock-in with the AWS platform. Bulk importing and exporting data can only be done with an AWS Elastic MapReduce (EMR) cluster. Adopting DynamoDB subsequently forces most big data deployments to adopt EMR in some form.
Alternatives, like Cassandra or MongoDB, have Hadoop connectors open and free of cost. All Hadoop platforms and Hadoop-as-a-Service are options for these database systems and can result in significant cost savings.
Hadoop challenges
CGA currently has a few small servers in-house, which they use to compute their daily analytic reports on prices and identify new items and market trends. CGA’s in-house deployment is increasingly difficult to manage, lacks scalability, and ties down development resources required for new feature development. Availability is another worry since the systems rely on machines in one location and only a few staff members are knowledgeable enough to administer the cluster and respond to problems. Furthermore, they do not have the expert knowledge to optimize the deployment, make it more robust, or add new services like Hive for business analysts to query the rapidly growing amount of data.
Computing is a utility
Small and medium enterprises, like CGA, regularly grow to the stage where they face value locked away in their data. The opportunity cost of developing and managing a professional data platform in-house is high though. Hadoop cloud deployments and Hadoop-as-a-Service are ideal solutions in these situations as they provide manageable cost and risk by converting capital expenditure to an operational one. They reduce the pressure on hiring expertise for tasks that do not provide any competitive advantage.
A misconception exists that the competitive advantage of big data and data science is linked to the ability to manage and compute big data. In fact, managing and computing big data is becoming a utility and can be acquired like email or web hosting. Competitiveness is gained by enabling business users to harness the data with tools like Hive, and by merging unique domain knowledge with advanced data science skills like machine learning.
Hadoop in the cloud
CGA considers three options for the company’s computing needs; EC2, EMR, and Qubole. Hadoop will remain at the core but the platform will move to the cloud to make it scalable, reduce operational burden and risk on availability, and keep costs manageable.
EC2
Virtual machines like AWS EC2 are the first option considered by CGA. Hadoop would still be installed and managed by CGA staff. This solution gives full flexibility in the choice of distributions, e.g. Cloudera, Hortonworks, and MapR to name a few, or even fully vanilla or customized Hadoop deployments. Another benefit is that (immediate) expenses are limited to only virtual machines.
Projecting this idea forward CGA realizes that problems arise with this solution. Larger cluster deployments incur license and consulting costs with many distributions and the operational burden with Hadoop still increases even if the hardware is virtualized. Lastly, DynamoDB as a data storage option would require another deployment of EMR for data exports.
EMR
The second alternative reviewed by CGA is embracing EMR. It has the benefit of connecting with DynamoDB and is a scalable, on-demand Hadoop deployment. It reduces the operational requirements significantly since a cluster can be configured including the choice of services and versions (as far as supported by EMR). EMR costs are a combination of the EC2 instances making up the cluster plus a premium for the managed Hadoop cluster, e.g. $0.12 per hour for a m1.xlarge in the US East region.
The currently scheduled workloads CGA is processing every day could be processed well by this solution. Scalability on a job-to-job basis would be no problem since for each a fitting cluster can be deployed. The cluster costs are linked to the processing time of the jobs and most of the day no cluster would be needed.
The business analysts and data scientists in the company, however, are opposing this solution. They explain that an EMR cluster would not give them easy access to data, i.e. through a web interface. This would hinder them from generating further insight and working in an ad-hoc manner. Latter is true especially since every EMR cluster needs to be explicitly started and stopped, which makes working with them for business users difficult. The developers argue that an alternatively permanent running EMR cluster lacks real scalability since EMR does not scale the underlying HDFS efficiently. Hadoop can scale nearly linearly but with EMR additional task nodes bring a diminishing return in processing performance due to a lack of data locality on the additional nodes.
Qubole
CGA considers the reservations against EMR and investigates Qubole’s data service solution. Qubole is different from other solutions as it transparently manages the underlying Hadoop cluster. Qubole utilizes EC2 with a custom, optimized Hadoop distribution based on Facebook’s code branch. Qubole auto-scales the cluster to optimize the balance between performance and cost. A cluster shrinks with small workloads and expands when appropriate. Their service even stops unused clusters without the need to monitor them. Equally, it starts them swiftly in the background when users try and access them, e.g. with Hive queries, or when jobs are scheduled. This straightforward and powerful cluster management means that without any effort clusters only incur cost when processing is taking place and then only as much as is needed.
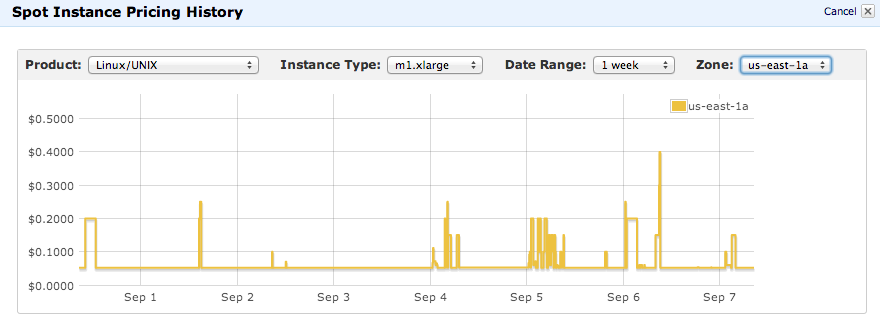
EC2 spot instance cost can be far below on-demand (source Amazon Web Services)
An excellent cost-saving feature of EC2 is spot instances. They are computing instances auctioned at a fraction of the cost of on-demand instances. Spot instances however can be shut down and removed by Amazon at any time, i.e. when Amazon requires them for on-demand jobs of other customers or the auction prices have risen beyond your maximum bid. This makes managing them by yourself with an EC2-only deployment tricky. EMR supports spot instances but merely as computing nodes without HDFS. This leads to suboptimal performance.
Qubole elegantly solves this with an option to select how many machines of a cluster should be spot instances and what price CGA, for example, is willing to pay. That is all that is needed for Qubole to transparently bid for machines and add them to the cluster as needed to reduce cost and boost performance. Qubole intelligently manages HDFS with this instance so CGA always receives excellent performance and does not lose data when spot instances are removed by Amazon.
A distinct and valuable feature Qubole offers is an intuitive web interface for business analysts, data scientists, data engineers, and software developers. The interface helps develop workflows and scheduled jobs to orchestrate Hadoop JARs, streaming, Hive, Pig, data import, and exports. Especially around Hadoop’s strong point of ETL (Extract, Transform, Load) data, Qubole provides database adapters and tools to make recurring processes easy to develop and manage.
Qubole extends the common Hadoop functionality and its interface with useful features to raise productivity for data teams. Hadoop logs, Hive queries, and table definitions, for example, are made seamlessly accessible through the web interface and independent from the service instantiating and removing clusters in the background. The service integrates so well with AWS S3 that it is even faster than EMR. At Qubole data service’s core, a focus on optimizing Hive’s performance and accessibility through the graphical user interface makes data exploration and sampling easy and with the auto-scaling of the cluster inexpensive and fast. It provides, for example, an unique data connector to mongoDB, which maps mongoDB collections to Hive tables removing the need of writing map reduce programs to import or export data.
Cost
CGA is impressed with Qubole’s offering and tested it with Qubole’s free plan. For a final decision, CGA evaluates the costs of Qubole, EC2, and EMR. They decide that from their current experience and future use cases around analytics and ad-hoc work CGA requires a cluster that is constantly available since there will be ad-hoc queries and scheduled jobs interleaving. That will result in strongly varying computing needs and utilization.
EC2 and EMR, consequently, would need to provide a permanent cluster, 24 hours a day, to avoid having to manage starting and stopping clusters constantly. Qubole, however, manages the instances and clusters transparently and is expected to only incur 50% of the peak instance and service costs, especially around holidays, weekends, and nighttimes when no ad-hoc workload is generated. Furthermore, the current spot pricing and the auto-scaling mean that the EC2 cost for Qubole is expected to be a mix of half spot and half on-demand price. This reduces the instance cost from $0.48 (on demand) to $0.29 (mixed) per hour assuming (conservatively) a spot price of $0.1 for m1.xlarge in the US East.
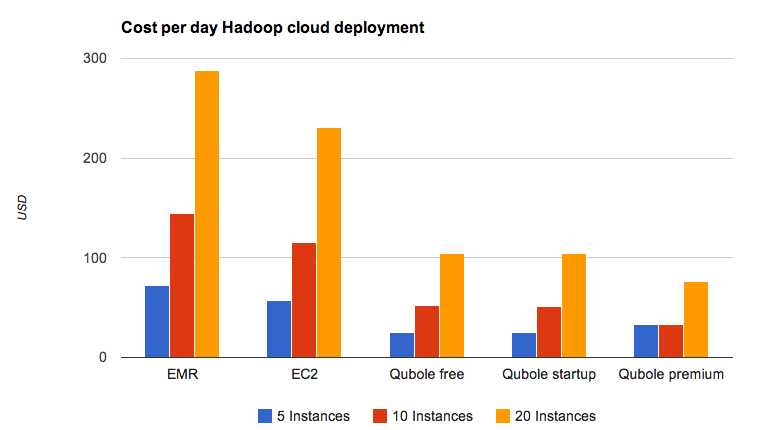
Comparison (in USD) of Hadoop cluster cost using m1.xlarge instances in the US East region
CGA estimates its mid-term Hadoop needs to be 5 to 20 m1.xlarge equivalent instances. After considering the auto-scaling, spot instance saving, and also adding the monthly costs for the startup and premium Qubole package CGA realizes that a Qubole deployment saves a very significant amount of money. Compared to EMR a 20 instances deployment with the Qubole premium package could save more than $77,000 a year or 74% of the EMR cost.
The larger Qubole packages result in a lower daily cost due to their reserved bulk service capacity and also include more users and database adaptor invocations, growing with the needs of the businesses. Only small exploratory clusters are cheaper on the free package. Even a modest 10 instances cluster is cheaper with the Qubole startup package. Larger deployments, naturally, become more cost-effective with the Qubole premium package.
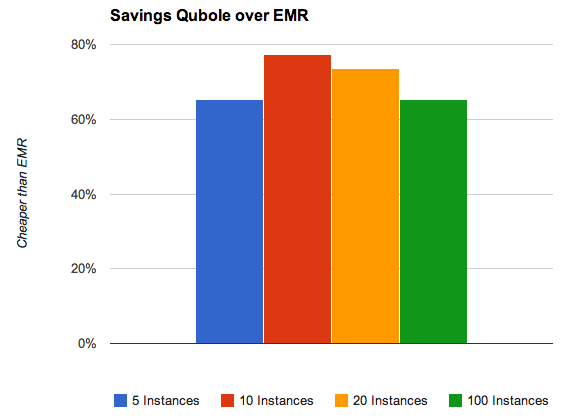
Comparison (percentage) of Hadoop cluster cost EMR vs Qubole using m1.xlarge instances in the US East region
The potential savings over EMR are likely between 60-80% across the scenario (depending on utilization, spot prices, and reserved instance usage). Overall an intelligently auto-scaling data service like Qubole promises major savings. This does not even account for the savings in opportunity costs due to virtually no operational effort with Qubole. Relatedly, EC2 appears slightly cheaper than EMR but the operational cost of managing the Hadoop installation is significantly higher which rarely makes this a viable option.
Conclusion
CGA, at the end of the evaluation, decides to choose Qubole for its cloud computing and a managed Cassandra cluster for data storage needs. CGA concluded that the combination is highly cost-effective and requires minimal capital expenditure. The risk is low since there is no cloud vendor lock-in and both Qubole and Cassandra offer built-in scalability. Importantly, besides meeting the challenges of scaling their business, Qubole makes their big data accessible to many more users in the company creating valuable insight. Hive with its SQL-like language and the Qubole graphical user interface enable anyone with basic SQL skills to query the data.
Try Qubole for free



