
The scalability of cloud databases and the potential of big data cloud computing is the most challenging aspect when designing an elastic data architecture. It is technically complex to scale data storage and computing. At the same time, premature optimization for potentially superfluous scalability carries a sizeable economic risk and opportunity cost.
Today, technology firms and departments contemplating scalable database architectures have numerous database management systems and options for running them. Specifically, NoSQL systems with flexible, de-normalized data schema have gained increasing market share with the rise of big data. Cloud and virtual computing resources and particularly Hadoop as a service are a paradigm shift. They introduced flexible architectures with managed technology and they transformed capital expenditure to operational one. Together NoSQL and cloud computing promise to bridge the gap between cheap and scalable data architectures.
This two-part series introduces a case study leveraging cloud databases and cloud computing. It illustrates typical requirements leading to their adoption and compares costs and benefits. The first part introduces the scenario with a cloud database scalability challenge and two popular NoSQL key-value database systems to address it. The second part of the series introduces how the computing demand can be met in an elastic, simple, and economic fashion.
Case study
CGA (Crazy Galactic Auctions) is a fictitious company, which crawls auction websites for product information and prices. It collects the data in a MongoDB NoSQL document-oriented database at the moment. Customers can sign up to get daily analytic reports on prices, new items, and market trends. They can also access the CGA website to browse and compare products and prices.
Currently, CGA is mining 500 application pages a second to guarantee its customers discover new auctions and hourly updates of up to 1.8 million products. The collected data is exported nightly for reporting and analytics to a small in-house Hadoop cluster. The business is growing and CGA anticipates the growing application market and its expansion to support more mobile platforms to require a growth by at least a magnitude and have the option to grow two magnitudes if needed.
Scalability should be implicit
CGA uses an un-sharded MongoDB replica set to manage the data. CGA does not want to manage a more complex, sharded MongoDB setup. Their expectation of a new architecture is that scalability should be achieved implicitly by the data store design and require no additional work in the future. The strategic plan is to focus internal resources on customer-facing features and reduce operational burden.
Consider data access patterns and schema
CGA also realized that the MongoDB document style data format is superfluous for the simpler than anticipated use-case of auction data. Their data access pattern reveals mostly access by product id and filtering by time ranges, e.g. retrieving prices of the last week for a product. After reviewing the market CGA decides that a battle-proven managed NoSQL key-value store with a flexible schema and simple primary index is sufficient and would reduce the operational complexity. The two choices that fit CGA’s requirements best are a managed Cassandra cluster and Amazon Web Services DynamoDB.
The challenge
The future load to accommodate is predicted to be 5,000 write operations per second. The read side of things is more complicated since the nightly export is a burst operation and requires a maximum of reads in a short period. The rest of the day’s reads are coming from the website only and are comparatively low. CGA estimates that for reporting it will need to support a burst read rate of 5,000 items per second for 2-3 hours and no more than 100 per second for the rest of the day.
DynamoDB
The first option CGA looks at is DynamoDB. It takes away all administrative requirements and reduces the choice of how many read and write operations per second are required. The pricing subsequently is linked to the provisioned capacity costing (US East region) of $0.0065 per hour for 10 writes per second for items 1KB or less in size. The same price applies to 50 strongly consistent or 100 eventually consistent reads per second for items up to 4KB. Larger items require provisioning a multiple of reads or writes according to their size, e.g. a 9KB item costs 3 provisioned read operations.
The base load of 100 reads and 5,000 writes would cost $2,739.67 per month. GCA has the option to provision the maximum required capacity at 5,000 reads and 5,000 writes for $3,007.62 per month or $3,281.04 per month for eventual or strong consistency. Eventual consistency usually lags milliseconds or single-digit seconds behind writes which is good enough for GCA. Additionally, DynamoDB charges $0.25 per GB per month stored. The 5,000 writes per second enables GCA to write up to 13 TB of data per month to DynamoDB. However, most of the mining of the auctions includes only small price updates and GCA expects to store no more than 1 TB at a time in DynamoDB which is an additional $250 a month for a total of $3,250 monthly costs.
DynamoDB allows adjustments up and down in read and write capacity within minutes to hours. Consequently, underestimating or overestimating the required capacity needs can be corrected within hours and is a simple function of the operational expenditure for required capacity. In a scenario where there is a quick expansion needed, e.g. because the product went viral, Amazon can easily support scaling another magnitude simply by spending $32,500 a month. This might sound expensive but this kind of scaling up and down can be done in hours and without the need and cost of system and database administrators, or the capital expenditure of hardware. Of course, once you established a base load of that magnitude alternative deployments may become attractive. It moreover pays to regularly reevaluate, which data genuinely requires an expensive, fast random read-and-write store.
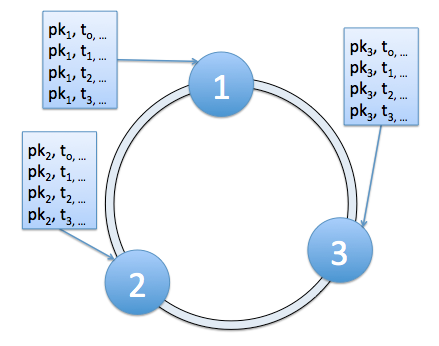
A balanced primary key is essential to scale DynamoDB and Cassandra horizontally
Cassandra
Cassandra is a widely used NoSQL store used in large global deployments by companies like Netflix. Cassandra has strong similarities in features and structure with DynamoDB. Both use simple primary keys, both allow range or cluster keys to select ranges, e.g. a time series of a product with its id being the primary key and the timestamp of the data mining the cluster/range key. The primary index’s hash is used to distribute the data in the database cluster and the range key is a sorting to make retrieving ranges fast. Both DynamoDB and Cassandra also allow additional secondary indices on columns to support the fast retrieval of single items by a combination of primary and secondary keys. In Cassandra, the secondary index is local to the partition, and thus a query requires a primary key to select a partition first. Practically the cardinality of the secondary indexed column should be low or the size of the index may incur a performance penalty making it ineffective.
CGA is considering a managed Cassandra cluster as a DynamoDB alternative and selects the ‘Basic’ cluster from Instacluster. The cluster supports 8,000 read and 9,500 write operations per second with 6.7 TB storage. It is based on eight m1.large EC2 instances for $2.96 an hour, which is $2,160.8 per month. This solution is a third cheaper than DynamoDB and offers more capacity and read-write performance. Furthermore, a smaller custom-designed Cassandra cluster could potentially lower the cost further to up to half of the DynamoDB on-demand price. A Cassandra cluster too can easily be scaled at runtime by adding or removing nodes.
Not an easy choice
Both NoSQL cloud services can deliver the desired output and the cost does not vary as much as one may have expected. The DynamoDB price, for example, can be halved or reduced to a quarter in ideal cases by buying reserved capacity for one or three-year terms. Its precise scalability and simplicity lend themselves to fast-growing or unpredictable loads. The managed Cassandra deployment offers more value without long-term commitments, cheaper storage for bigger data, and is fairly scalable and flexible. In the end, small subtleties in the use case may make the difference, e.g. how the data connects to your cloud computing environment.
The second part of this series will highlight the cloud computing side of the scenario. CGA can reduce its expenditure and enhance processing speed by using a tremendously elastic computing environment based on Hadoop and avoid the operational complexities of managing a cluster themselves. The use case will compare two very popular options in this space, Amazon Web Services Elastic MapReduce and Qubole’s managed big data service.



