Qubole’s Presto-as-a-Service is primarily targeted at Data Analysts who are tasked with translating ad-hoc business questions into SQL queries and getting results. Since the questions are often ad-hoc, there is some trial and error involved. Therefore, arriving at the final results may involve a series of SQL queries. By reducing the response time of these queries, the platform can reduce the time to insight and greatly benefit the business. In this post, we will talk about some improvements we’ve made in Presto to support this use case in a cloud setting.
The typical use-case here is a few tables, each of which is 10-100TB in size, living in cloud storage (e.g. S3). Tables are generally partitioned by date and/or by other attributes. Analyst queries pick a few partitions at a time, typically last one week or one month of data, and involve where clauses. Queries may involve a join with a smaller dimension table and contain aggregates and group-by clauses.
The main bottleneck in supporting this use case is storage bandwidth. Cloud storage (specifically, Amazon S3) has many positives – it is great for storing a large amount of data at a low cost. However, S3’s bandwidth is not high enough to support this use case very well. Furthermore, clusters are ephemeral in Qubole’s cloud platform. They are launched when required and shut down when not in use. We recently introduced the industry’s first auto-scaling Presto clusters which can add and remove nodes depending on traffic. The challenge was to support this use case while keeping all the economic advantages of the cloud and auto-scaling.
The big opportunity here was that the new generation of Amazon instance types come with SSD devices. Some machine types also come with a large amount of memory (r3 instance types) per node. If we’re able to use SSDs and memory as a caching hierarchy, this could solve the bandwidth problem for us. We started building a caching system to take advantage of this opportunity.
Architecture
The figure below shows the architecture of the caching solution. As part of query execution, Presto, like Hadoop, performs split computation. Every worker node is assigned one or more splits. For the sake of exposition, we can assume that one split is one file. Presto’s scheduler assigns splits to worker nodes randomly. We modified the scheduling mechanism to assign a split to a node based on a hash of the filename. This assures us that if the same file were to be read for another query, that split will be executed in the same node. This gave us spatial locality. Then, we modified the S3 filesystem code to cache files in local disks as part of query execution. In the example below, if another query required reading file 2, it will be read by worker node 1 from the local disk instead of S3 which will be a whole lot faster. The cache, like all others, contains logic for eviction and expiry. Some of the EC2 instances contain multiple SSD volumes and we stripe data across them.
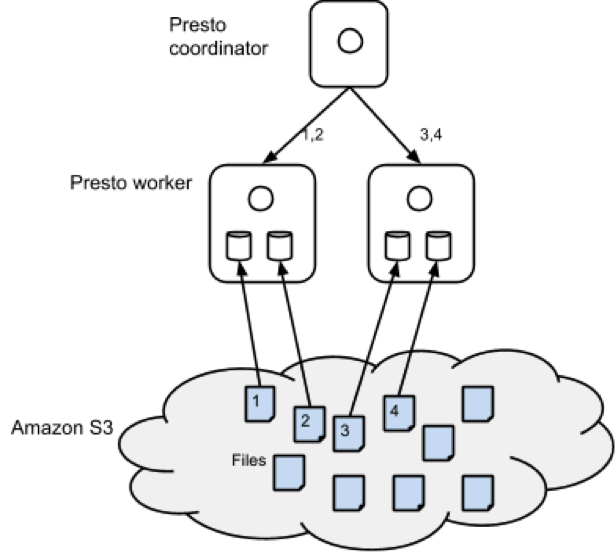
We attempted to use MappedByteBuffer and explicit ByteBuffers for an in-memory cache but quickly abandoned this approach – the OS filesystem cache did a good enough job and we didn’t have to worry about garbage collection issues.
One problem remained, though. What if a node was added or removed due to auto-scaling? The danger with using simple hashing techniques was that the mapping of files to nodes could change considerably causing a lot of grief. The answer was surprisingly simple – consistent hashing. Consistent hashing ensures that the remapping of splits to nodes changes gracefully. This blog post does a great job of explaining consistent hashing from a developer’s point of view.
We used Guava extensively for the caching implementation. Guava has an in-memory pluggable cache. We extended it to support our use case of maintaining an on-disk cache. Furthermore, we used Guava’s implementation of consistent hashing.
Experimental Results
To test this feature, we generated a TPC-DS scale of 10000 data on a 20 c3.8xlarge node cluster. We used delimited/zlib and ORC/zlib formats. The ORC version was not sorted. Here are the table statistics.
| Table | Rows | Text | Text, zlib | ORC, zlib |
| store_sales | 28 billion | 3.6 TB | 1.4 TB | 1.1 TB |
| customer | 65 billion | 12 GB | 3.1 GB | 2.5 GB |
We used the following queries to measure performance improvements. These queries are representative of common query patterns from analysts.
ID Query Description Q1 select * from store_sales where ss_customer_sk=1000; Selects ~400 rows Q2 select ss_store_sk - sum(ss_quantity) as cnt from store_sales group by ss_store_sk order by cnt desc limit 5; Top 5 stores by sales Q3 select sum(ss_quantity) as cnt from store_sales ssjoin customer c on (ss.ss_customer_sk = c.c_customer_sk)where c.c_birth_year < 1980; Quantity sold to customers born before 1980 Quantity sold to customers born before 1980
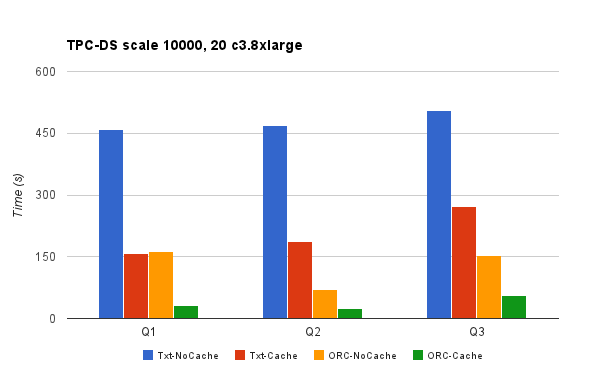
Txt-NoCache means using Txt format with caching feature disabled. The Txt-NoCache case suffers from both problems – inefficient storage format and slow access. Switching to caching provides a good performance improvement. However, the biggest gains are realized when caching is used in conjunction with the ORC format. There is a 10-15x performance improvement by switching to ORC and using Qubole’s caching feature. We incorporated Presto/ORC improvements courtesy of Dain (@daindumb) in these experiments. Results show that queries that take many minutes now take a few seconds, thus benefiting the analyst use-case.
Conclusion
Presto, along with Qubole’s caching implementation, can provide the performance necessary to satisfy the Data Analysts while still retaining all the benefits of cloud economics – pay-as-you-go and auto-scaling. We’re also in the process of open-sourcing this work.
If you’re interested in giving this a try, do sign up for a free trial. If these sorts of problems and solutions interest you, please reach out to us at [email protected]




