
At Qubole, we’ve made significant progress on our adoption of Spark on QDS with new features and scalability. Here are some recent stats pertaining to Apache Spark on Qubole Data Service (QDS):

Apache Spark on QDS–New Features and Highlights
To accommodate growing demands and leverage technological advancements made by the Apache Spark community, we at Qubole continue to release complimentary enhancements and optimizations pertaining to Apache Spark offered as a service on Qubole–the leading Big Data platform in the Cloud. Here are some highlights:
Spark 2.0 Support
- Qubole now supports Spark 2.0 so data teams using QDS can start taking advantage of major Spark 2.0 updates including API stability, substantial performance improvements, support for SQL 2003, and enhancements related to Machine Learning including support for MLlib APIs in SparkR, and ML algorithms in DataFrames-based API.
- One of the more exciting features of Spark 2.0 is ML persistence. It enhances the productivity of data team members by bridging the gap between data scientists and data engineers. Data scientists using QDS can now build, test, and save complex pipelines on centralized storage such as AWS S3–which can then be accessed by data engineers to deploy in production already tested complex pipelines without needing to recode, retrain and retest any of it yielding expected results.
- For more details on Apache Spark Release 2.0, click here.
As a result of migrating big data processing & analytics workloads to Apache Spark 2.0 on QDS, some of our customers are already seeing up to 5X performance gain across Spark jobs.
GitHub Integration for Spark Notebooks
- With our GitHub integration, the power of collaboration and version control is now integrated into Qubole’s Spark Notebooks. Once a Notebook is linked to a GitHub account and repository, data team members will be able to start saving their work on GitHub without leaving the Qubole Notebook interface. All queries, commands, and results for Spark, SparkSQL, Scala, and Python will be saved to configured GitHub repository.
- This integration will allow data team members to share and restore the entire state of a Notebook without having to rewrite queries and/or commands even when the associated cluster is not running.
- For setup and configuration details, click here.
Optimized Split Computation for SparkSQL
- We’ve implemented optimization with regard to AWS S3 listings which enables split computations to run significantly faster on SparkSQL queries. As a result, when there are a large number of partitions in Hive tables, we’ve recorded up to 6X and 81X improvements in query execution and AWS S3 listings respectively.
- For more details, click here.
Auto-scaling in Spark
- In the open source version of auto-scaling in Apache Spark, the required number of executors for completing a task is added in multiples of two. In Qubole, we’ve enhanced the auto-scaling feature to add a required number of executors based on configurable SLA. In addition, Qubole’s auto-scaler can add and remove nodes based on the resource requirements in the cluster. For instance, if the number of executors that need to run is more than the capacity of the cluster, Qubole can add nodes and provide resources to these executors. Similarly, if there are not enough executors in the cluster, nodes are automatically and gracefully removed.
- With Qubole’s auto-scaling, cluster utilization is matched precisely to the workloads, so there are no wasted compute resources and it also leads to lowered TCO. Based on our recent benchmark on performance and cost savings, we estimate that auto-scaling saves Qubole’s customers over $300K per year for just one cluster.
- For more details, click here.
Heterogeneous Spark Clusters
- Qubole now supports heterogeneous Spark clusters for both on-demand and Spot instances. This means that the slave nodes in Spark clusters may be of any 40+ AWS instance types.
- For On-Demand nodes, this is beneficial in scenarios when the requested number of primary instance type nodes are not granted by AWS at the time of the request.
- For Spot nodes, it’s advantageous when either the Spot price of the primary slave type is higher than the Spot price specified in the cluster configuration or the requested number of Spot nodes is not granted by AWS at the time of the request.
- For more details, click here.
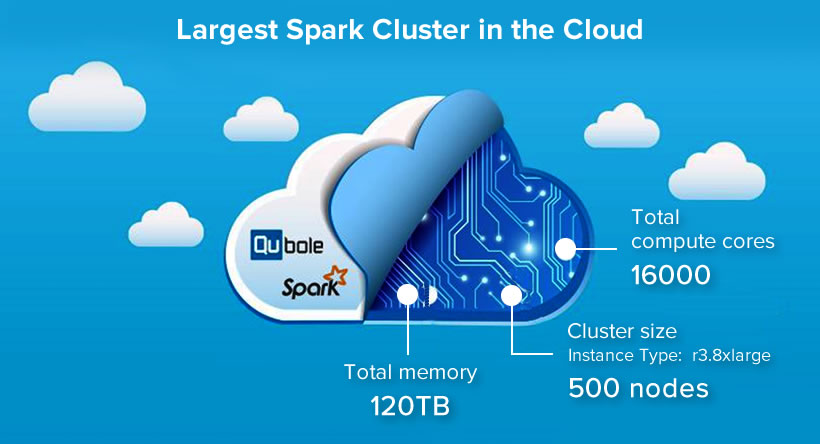
Largest Spark Cluster in the Cloud
We are also proud to announce that we’ve scaled up the largest Apache Spark cluster in the Cloud. It was launched on Qubole Data Service (QDS) by one of our customers for their Big Data processing workloads.
Conclusion
There is no question Apache Spark is on the rise and it continues to dominate the landscape when it comes to in-memory computing, real-time analysis as well as iterative and machine learning use cases. By using enterprise scale Apache Spark as a service on Qubole for your Big Data workloads and applications, you can quickly start leveraging all the benefits and power of Apache Spark with minimal operational and configuration overhead.
To get an overview of QDS, click here to register for a live demo.
Apache Spark, Spark, Apache, and the Spark logo are trademarks of The Apache Software Foundation.



