Ad Hoc Data Analysis on Big Data Sets
- Home >
- Best-of-Breed Engines

The potential for ad-hoc analytics is getting really interesting with technologies such as Hadoop to facilitate queries on big data sets. In this short article, you’ll see its potential through an example of creating a 360-degree view of a customer. You’ll also learn why ad hoc analytics using an on-premise Hadoop deployment limits performance, scalability, and usability and discover that the cloud is a real game-changer for facilitating fast, interactive queries accessible by business analysts with an infinite capacity to scale.
What is ad hoc analysis on big data sets?
What is driving ad-hoc analysis on big data sets?
Why is ad hoc analysis difficult with on-premise Hadoop?
Why is ad hoc data analytics easier in the cloud?
Who is successfully running ad hoc analytics with Qubole?
1. What is ad hoc analysis on big data sets?
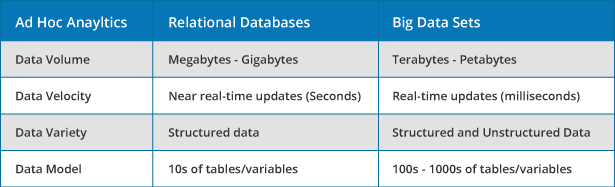
Ad hoc analytics is the discipline of analyzing data on an as-needed or requested basis. Historically challenging, ad hoc analytics on big data sets versus relational databases adds a new layer of complexity due to increased data volumes, faster data velocity, greater data variety, and more sophisticated data models.
2. What is driving ad-hoc analysis on big data sets?
Organizations are experiencing an increasing need to enable ad hoc analytics on big data sets to optimize their sales and marketing initiatives, discover new revenue opportunities, enhance customer service and improve operational efficiency.
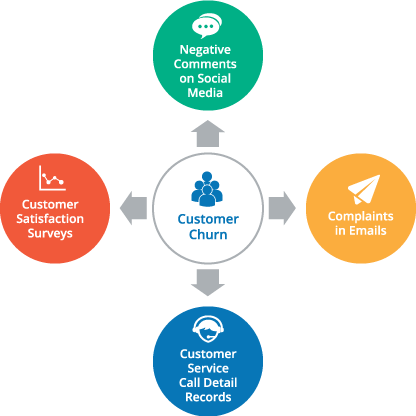
Let’s take a look at the role of ad hoc analytics on big data sets to achieve a 360-degree view of customers for an organization trying to understand why its customer churn has increased. By querying its structured, internal data the company can determine things like products losing customers, price changes that might have impacted defection, and changes in customer service metrics. But these only tell part of the story.
An extended 360-degree view using ad hoc analytics on big data sets allows the organization to bring in additional unstructured information, both internal and external to the company, to understand other factors relevant to customer churn. Data like social media comments, the results of customer satisfaction surveys, call detail records for customer service, and complaints received via email help the company fully understand and respond to its high rate of customer churn.
3. Why is ad hoc analysis difficult with on-premise Hadoop?
Most businesses processing ad hoc analytics on big data sets use Hadoop because it’s designed to handle huge volumes of data across a large number of nodes that can be added as needed. It leverages parallel processing across commodity servers, making it more affordable to scale than other options for big data. Plus, Hadoop accommodates any data format, requires no specialized schema, and provides high availability.
However, on-premise Hadoop deployment presents many challenges for ad hoc analysis. You can get more details by reading Cloud vs. On-Premise Hadoop. Here, we’ll focus on just some of the major ad hoc analysis challenges.
![]()
![]() Batch Processing
Batch Processing
Hadoop and its primary programming language, MapReduce, are designed for batch-oriented processing of big data sets. Apache Hive is a data warehousing system for large volumes of data stored in Hadoop. It’s considered one of the de-facto tools for Hadoop since it provides a SQL-based query language that makes it easy to query big data sets. However, queries performed with Hive are usually very slow because of its reliance on MapReduce.
To gain real-time interactive query functionality, organizations must use real-time processing engines such as Apache Spark and Facebook’s Presto alongside Hadoop. Unfortunately, these open source tools can be very difficult for some organizations to deploy and support.
![]()
![]() Inelastic Processing
Inelastic Processing
With on-premise deployments, fixed clusters mean that ad hoc data queries can easily run out of capacity or take way too long to process. As a result, companies either limit the number of queries they run, try to avoid processing queries during times of peak usage, or spend too much money because they are over-provisioning capacity to guarantee acceptable performance under any condition.
![]()
![]() Specialized Skill Requirements
Specialized Skill Requirements
Creating and executing ad hoc analytics in an on-premise Hadoop environment requires developers and data scientists with specialized MapReduce, Pig, and Hive skills. And, users need to obtain technical assistance to start and stop clusters every time they run a query.
4. Why is ad hoc data analytics easier in the cloud?
Qubole Data Service (QDS) is a Big Data as a Service (BDaaS) solution available on Amazon Web Services, Google Computer Engine, and Microsoft Azure that removes ad hoc analysis obstacles associated with on-premise Hadoop. QDS makes interactive real-time ad-hoc queries on big data sets in the cloud scalable and easy.
![]()
![]() Real-Time Interactive Queries
Real-Time Interactive Queries
Using advanced caching and query acceleration techniques, Qubole has demonstrated query speeds for Hadoop and Hive up to five times faster compared to other cloud-based Hadoop solutions.
The QDS platform includes “Everything as a Service”… MapReduce, Hive, Pig, Oozie, and Sqoop, plus Hadoop Spark and Presto, open-source cluster computing frameworks for real-time interactive queries on data stored in Hive, HDFS, Hbase, Amazon S3 or Microsoft Azure Blob. Storage. QDS allows users to launch and provision Spark or Presto clusters and start running queries in minutes.
![]()
![]() On-Demand Elastic Clusters
On-Demand Elastic Clusters
QDS runs on an elastic Hadoop-based cluster that scales up or down to meet ad hoc query processing requirements on big data sets. With QDS auto-scaling, nodes are automatically added to clusters to accommodate more data and to provide better query processing performance and are removed when they are no longer needed.
![]()
![]() Easy to Use
Easy to Use
With QDS, business analysts can query big data sets using SQL rather than having to write MapReduce or Pig code. Its visual query editor and query builder give users an easy way to start running queries in just a few minutes. And, QDS immediately responds when users execute queries; there’s no need to bring in IT to start or stop clusters.


