Introducing the 2018 Big Data Trends and Challenges Survey, sponsored by Qubole
In its second year, the 2018 Big Data Trends and Challenges Survey report* — conducted by Dimensional Research and sponsored by Qubole — reveals that while big data volume continues to skyrocket, enterprises are gaining greater business value from their data. In addition, more companies are shifting their big data processing to the cloud and diversifying their workloads. The survey includes responses from 401 data professionals working at enterprises around the world.
On-premises environments have yielded sub-optimal results for big data initiatives due to infrastructure complexity, the need for specialized talent, and cost overruns, among other reasons. With big data projects estimated to fail 85 percent of the time, enterprises are realizing the significance of not only investing in big data initiatives but providing the resources to guarantee success.
As a result, companies are turning to the agile, more powerful compute power of the cloud to build and optimize their big data projects. This change is reflected in the report, which shows 44 percent of businesses now have data lakes of more than 100 terabytes — an increase of 22 percent from the previous year. Organizations are storing and processing increasingly vast amounts of data in the cloud for sophisticated use cases such as machine learning, ad hoc analysis, application data integration, and data streaming.
Nearly Half of Respondents Express Big Data Project Growth
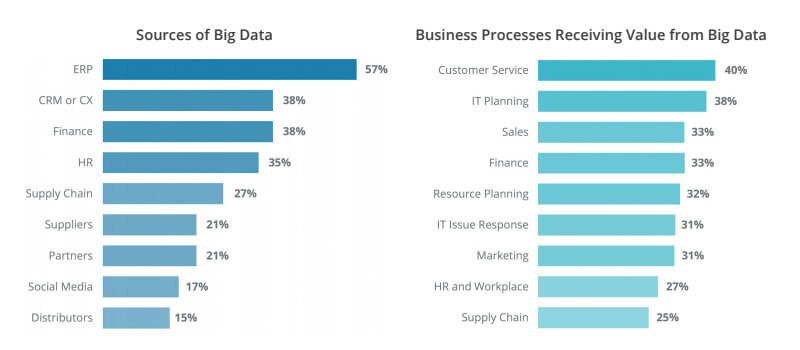
According to the report, the value of big data is widely understood among organizations today. Half of the respondents said they’ve been leveraging big data for quite some time (an increase of 23 percent from 2017). In addition to big data projects becoming more seasoned, companies are also seeing broader adoption of big data across teams. In 2017 close to half of the respondents received requests for big data project support from only two or three internal teams, whereas in 2018 the number of departments requesting support grew to four to 10 teams.
Engine Diversification Grows in Popularity
Open source engines and technologies continue to gain popularity, with the largest growth seen across tools like Presto, Apache Spark, and Flink. The 2018 Big Data Trends and Challenges Survey Report reveals Presto and Spark experienced significant gains between 2017 and 2018, with 63 percent and 29 percent increases for Presto and Spark, respectively. In our analysis of anonymized customer data (published earlier this year in our 2018 Big Data Activation Report) we also noted a significant upward trend among Presto and Spark usage: a 420 percent increase year-over-year for Presto, and a 298 percent increase for Spark.
Closing Thoughts
The 2018 Big Data Trends and Challenges Survey report offers valuable insights into where the market is heading, including companies’ preferences for processing big data and the types of workloads they’re conducting. We also see trends around the specific challenges that organizations continue to face as they move forward in their machine learning and analytics journey.
Perhaps the most important insight is the contrast between these broader market trends versus data from data-driven companies that have embraced and adopted these technologies, described in the previously launched Big Data Activation Report. We encourage you to review them together and share any conclusions you draw with us on Twitter, Facebook, or LinkedIn.
To dive into the survey data yourself, click here.
*View results from the 2017 survey here.



