With 90% of all the data in the world created in just the last 2 years, data scientists who historically worked on Python or R are slowly moving to distributed Spark ML for developing Machine Learning (ML) models at scale, and realize the full potential of data-driven business value.
Spark Architecture
When transitioning to enterprise data science at scale on a distributed Spark architecture, data scientists find it very challenging to provision and manage package dependencies for multiple dialects like Python & R on a multi-node cluster—aside from having to deal with the complexity of keeping the clusters scaled appropriately. These challenges stretch time to market and lead data scientists to abandon a distributed framework despite their potential to activate large volumes of data and deliver the desired business value.
Qubole is an open data lake platform that provides a frictionless experience for data scientists with easy access to Spark cluster computing resources through a choice of Jupyter and Zeppelin Notebooks. At Qubole, we continuously innovate and address the challenges data scientists face, by making it easy for them to migrate from a single-node framework to a distributed environment/framework like Spark ML. In this blog, we will walk through how Qubole removes some of these roadblocks, by introducing the concept of “package management” on fully-managed autoscaling Spark clusters.
Package Management
Package management is a set of capabilities in Qubole’s open data lake platform that abstract dependency management across all nodes in a cluster. It greatly simplifies and automates the processes of logically specifying dependencies through an easy-to-use UI, with no additional administrative or DevOps efforts. Package management provides meaningful and convenient ways to provision, de-provision, and manage packages for Python and R dialects on distributed Spark clusters.
Before the introduction of package management, Qubole users managed dependencies by adding all package installation instructions in a bootstrap script. This script runs on all nodes in the clusters at startup. Although effective, this bootstrap script approach had the following shortcomings, which provided the motivation to develop a package management solution in Qubole:
- Any changes in bootstrap need a restart of the cluster to take effect. This is a loss in productivity that translates into avoidable operational expenses (OPEX).
- Cluster startup and node autoscaling are slower with this bootstrap approach because the whole script is run on all the nodes separately when the node starts.
- By default, Qubole supports the default Python version of 2.7. To change the Python version, users had to make changes in bootstrap. Most of the time, this needed manual intervention.
PySpark Packages
Package management is based on the Anaconda distribution of Python and it provides an abstraction to manage Conda environments. Each package manager consists of two Conda environments – one for Python and another for R. All of this comes with a very intuitive User Interface (UI). Some of the important features in package management are:
- Users in an account can create multiple package managers. A package manager can be attached to a cluster and both of the conda environments in that package manager become automatically available in the cluster. All PySpark commands running on the cluster automatically start using the Python environment in the package manager and all SparkR commands running on the cluster start automatically using the R environment in the package manager.
- Users can select the Python version (3.7 or 2.7) and R version (3.5) for the package manager from the UI.
- All package manager environments are complete Anaconda distributions packed with 200+ Python and R packages (like pandas, NumPy, Scikit-learn, etc.etc).
- Users can add any conda, pip, or cran packages to the package manager environments from the UI. Packages become available on a cluster immediately without requiring a restart of the cluster or the Spark application.
- The logs and debugging information of installations on the cluster are presented in real-time on the UI.
The following screenshot captures all the available UI components available:
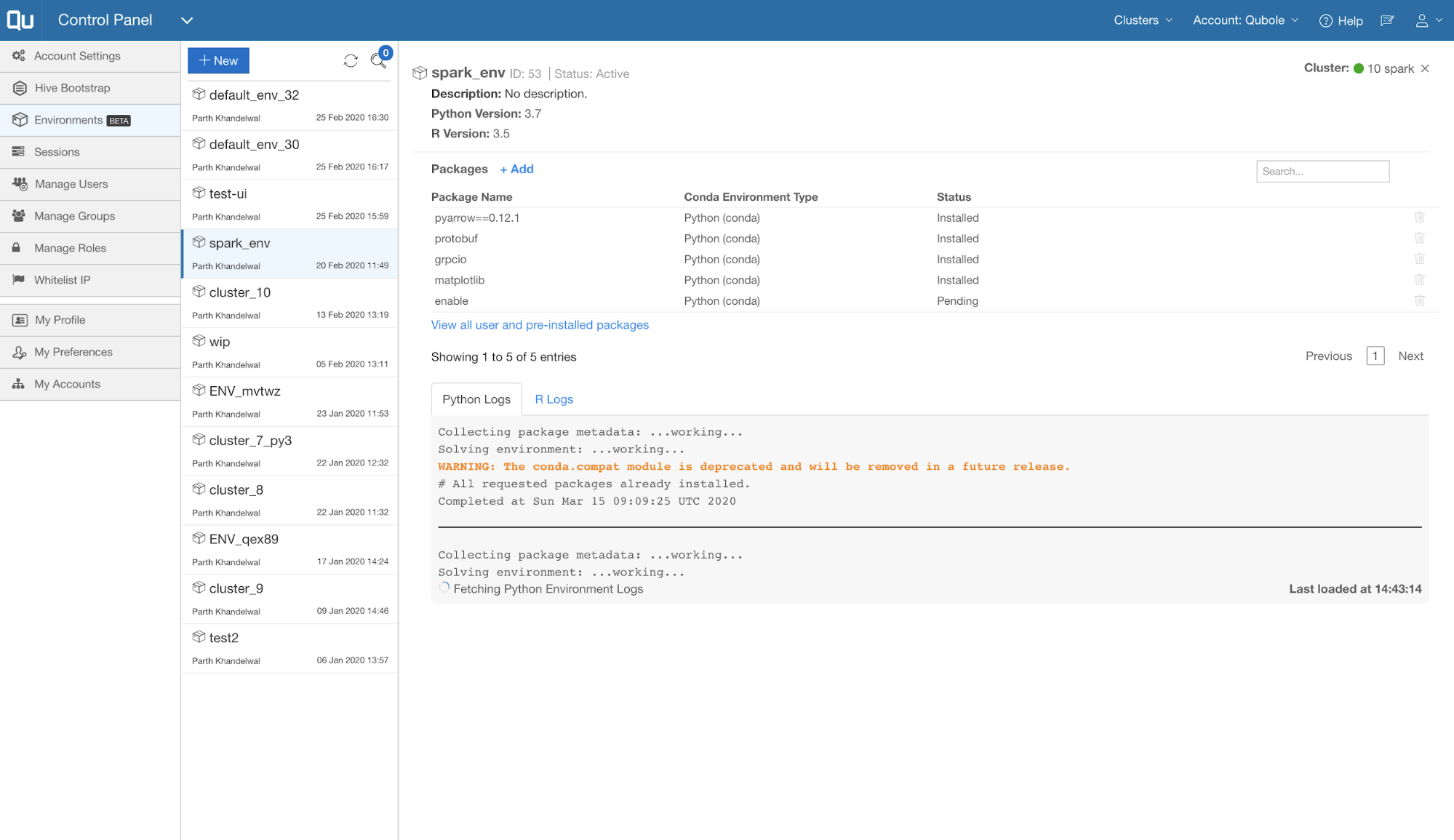
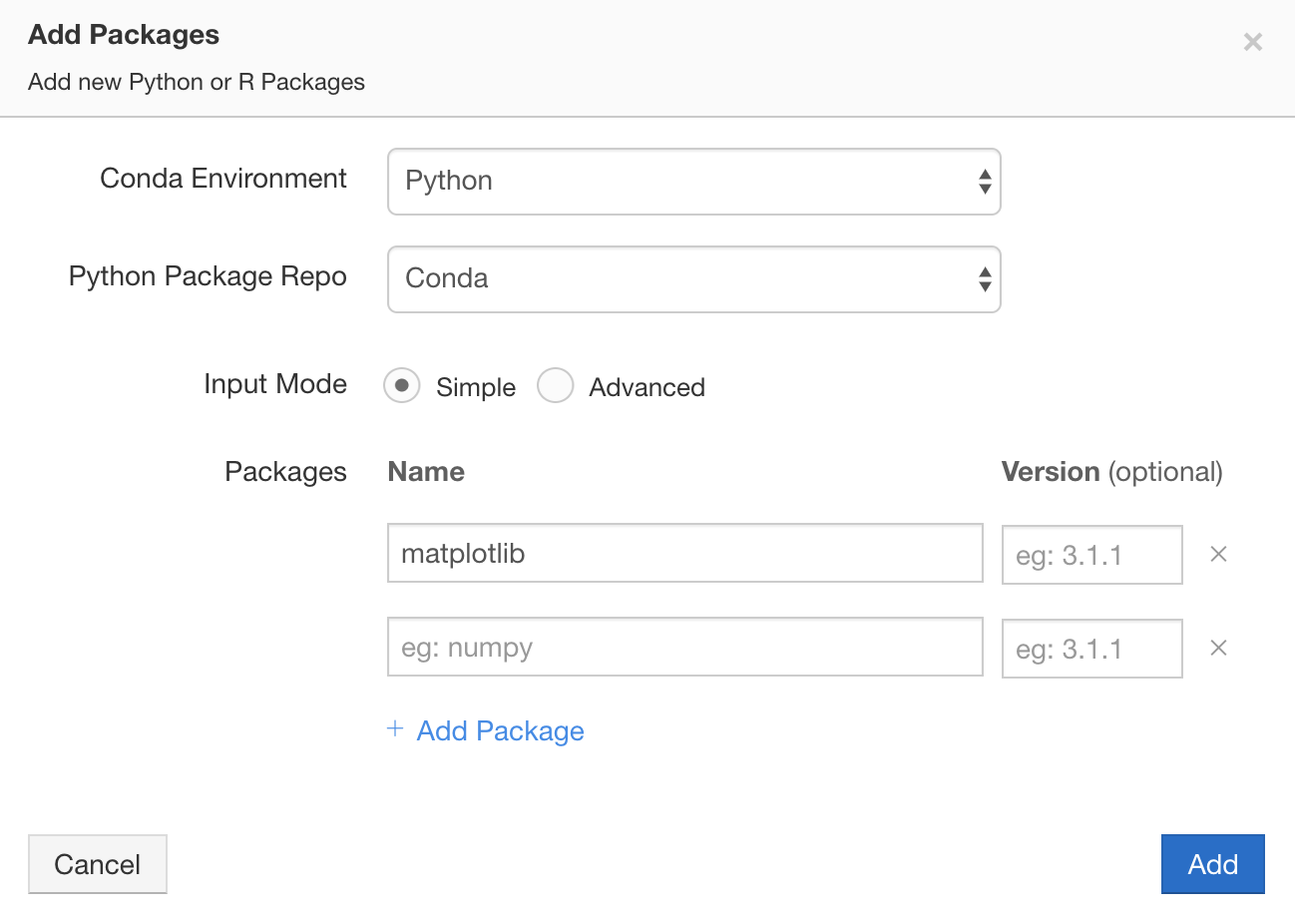
For complete details, refer to the Qubole user guide and API docs.
Implementation Details and Challenges Solved
While working on package management, our focus was on making the end-user experience similar to using Anaconda in an undistributed manner. There were many technical challenges we solved as part of this process, some of which are:
- Anaconda distribution comes with 200+ default packages and this makes it very big in size. It takes a lot of time to install, which significantly slows down the cluster start. Hence, we decided to ship Anaconda pre-installed and ready to use as part of our software.
- Clusters in Qubole can span 1000s of nodes. When a user adds a package in the UI, we install it on all nodes of the cluster simultaneously. Many design decisions were made to make this communication channel from UI to cluster work efficiently and without fail.
- When a user installs some extra packages in the package management environment, we create a digest of all the changes. When a cluster is restarted, we don’t reinstall all the packages again, we simply use the digest to make the environment available quickly.
What’s next?
Based on customer feedback, we are working on the following features in package management:
- Right now we only support conda-forge and default conda channels. We are working on adding support for custom conda channels and support to upload wheel and egg files.
- We are working on UI Revamp to support the upgrading of packages and restoring an environment to a previous state.
- We will also be working on supporting Jars and Maven coordinates through package management.
Summary
At Qubole, we believe it is really important for enterprises to overcome the inertia to adopt/practice distributed data science at scale. Our customer experiences show that this evolution directly translates into competitive advantages and tangible business value. Qubole’s package management helps data scientists focus on simplifying data science at scale, while the platform provides seamless access to autonomous and resilient cluster computing resources. Plus dependencies are abstracted and managed at the cluster level through Qubole’s package management capability.
Sign up for a free 14-day trial to experience the power of package management and Spark on Qubole.



