We are pleased to announce the 0.6.0 release of the ACID Data source for Apache Spark. This release should further empower Data lake users in enterprises to enable ACID support for Data governance, regulatory compliance, and Data engineering. Qubole provides multi-engine transactionality support via its open-sourced ACID connectors for Apache Spark and Presto. Qubole’s transactionality support encompasses primary open-source Data Lake engines – Apache Spark, Apache Hive, and Presto [1], to enable:
- Multi-Engine Transactional Updates and Deletes: Use Apache Spark and Apache Hive to perform write operations including Updates and Deletes with multi-engine Atomicity, Concurrency, Isolation, and Durability guarantees.
- Multi-Engine Transactional Reads: Use any of the significant open-source Data Lake engines – Apache Spark, Apache Hive, and Presto – to read from your data lake under multi-engine transactional guarantees. Snapshot Isolation is the isolation level offered.
Some of the notable improvements and functionality added in 0.6.0 of ACID Data source for Apache Spark are:
- SQL MERGE: Users can now use SQL MERGE [8] using Data Source in their Apache Spark pipelines to efficiently Upsert data for various use cases like Change Data Capture (aka CDC [7]) or General Data Protection Regulation (aka GDPR [6]). Here are the details of the documentation.
- Performance Improvements: Users can now benefit from improved write performance of ACID Data source by up to 50% and split computation times up to 8x.
- Feature Enhancements: Several improvements around update/delete (92, 83, 59) have been made. Improvements around support for task retries (43) and handling Partition predicates (21) have also been made. In total, 24 JIRAs are fixed in this release.
MERGE Command:
Users need efficient Upsert operation for multiple use cases in Data Lake like:
- Capture and Sync Change Data Capture (aka CDC [7]): CDC captures the changes in ‘source’ data, typically an enterprise OLTP system, and updates the data in ‘destination (s)’. The data can be your cloud objects stores like AWS S3 using multiple engines for Ad-hoc analytics, data engineering, streaming analytics, and ML.
- General Data Protection Regulation (aka GDPR [6]): With compliance such as GDPR, specifically Right to Forget or CCPA’s Right to Erasure, enterprises have built workflows to delete user records on demand from the Data lake
For such use cases, Users can run standard SQL MERGE queries using ACID Data source v0.6.0.
SQL Syntax
MERGE INTO <target table> [AS T] USING <source table> [AS S] ON <boolean merge expression> WHEN MATCHED [AND <boolean expression1>] THEN <match_clause> WHEN MATCHED [AND <boolean expression2>] THEN <match_clause> WHEN NOT MATCHED [AND <boolean expression3>] THEN INSERT VALUES ( <insert value list> ) Possible match clauses can be <match_clause> :: UPDATE SET <set clause list> DELETE Possible insert value list can be <insert value list> :: value 1 [, value 2, value 3, ...] [value 1, value 2, ...] * [, value n, value n+1, ...] Possible update set list can be <update set list> :: target_col1 = value 1 [, target_col2 = value 2 ...]
Additional syntax details can be found here.
Illustration
Consider a simplified CDC (change data capture) use case for a ride-hailing cab business, where a table on object store S3 named ‘driver(id: int, city: string, ratings: string)’ partitioned by ‘city’ are getting updates/deletes/inserts from upstream OLTP system once every hour. For the above use case, every hour, the ‘drivers’ with the city ‘closed’ needs to be deleted, other matching drivers need to be updated and new drivers need to be inserted.
Without ACID functionality, such Upserts would have been an elaborate pipeline, typically performing these steps:
- Figure out all the partitions based on ‘city’ with updates/deletes for drivers.
- Rewrite those partitions applying those updates/deletes.
- Insert the new driver records.
With frequent updates, the above pipeline is relatively slow and cumbersome. Also, if the above pipeline fails midway, it can lead to data corruption.
With MERGE, once all the CDC data is dumped into the table on S3 named ‘source’, the CDC pipeline can issue the following command:
MERGE INTO driver as t USING source as s ON t.id = s.id WHEN MATCHED AND t.city = 'closed' THEN DELETE WHEN MATCHED THEN UPDATE t.city = s.city, t.ratings = s.ratings WHEN NOT MATCHED THEN INSERT VALUES (*)
This simplifies the pipeline immensely and makes it efficient to avoid rewriting the entire partition. MERGE is supported only for ACID tables and executed under ACID transaction guarantees. As per our observation, updating 1% of data spread across 5% of partitions using MERGE improves ETL runtime over the traditional approach by 57%.
Optimized Write Performance:
The write performance of Data Source has improved in 0.6.0 mainly by optimizing the number of objects created in the writer code. Runs show insert performance into an unpartitioned table of size 100 GB enhanced by 46% and performance on size 1TB improved by 50%
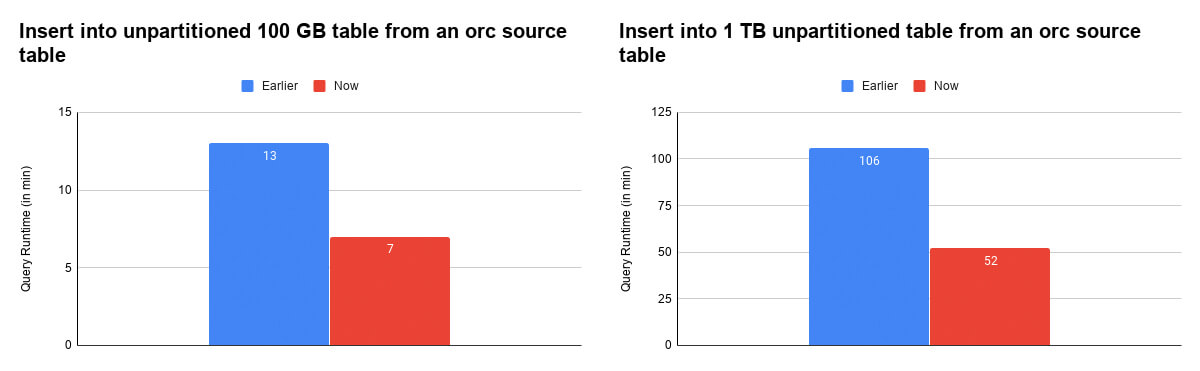
Figure 2: Write Performance Improvements for 100GB and 1TB.
Optimized Split Computation:
Split Computation time has significantly improved for partitioned ACID tables, as shown in Figure 4 below. Benchmarking against tables with 10,000 partitions saw an improvement of around 8x in Split Computation
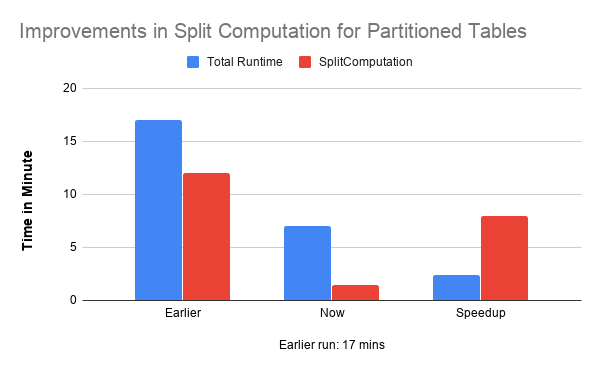
Figure 4: Improvements in Split Computations.
For every ACID table, HiveAcidRDD is created to read them in our Data Source. HiveAcidRDD.getPartitions does Split Computation to compute Hive Splits for the ACID table, and it is then converted into Array[HiveAcidPartition]. Note HiveAcidPartition is an RDD Partition that is different from the Table Partition. For partitioned tables, we used to compute splits in parallel using threads on the Spark Driver JVM. Due to the limitation of single JVM parallelism, it was time-consuming. With a powerful parallel computing engine like Spark at its disposal, split computation is parallelized using the engine resulting in reduced computation time.
Release Notes and Acknowledgement:
Release notes for Open Sourced version can be found here: https://github.com/qubole/spark-acid/releases/tag/v0.6.0
We want to thank all who have been using this Data Source in the Open source community and making it better. We would especially like to acknowledge our friends at Rapid River (Carlos Lima and Shuwn Yuan Tee) and VMWare ( Veera Venkata Rao et al) who have used this Data Source extensively at scale and helped us make it better. We would also like to thank our friends at Cloudera: Mahesh Kumar Behera and Anurag Shekhar, who are working towards building features like DataSource v2 support.
Carlos Lima from Rapid River said:
We needed a tool that allowed us to stream data into a mutable Hive table. Spark Acid was able to help us achieve this goal. Amogh and the team at Qubole went out of their way to help us complete our project successfully. It really was above and beyond what was necessary. We wish everyone involved the very best with the release of version 0.6.0.
References:
- https://www.qubole.com/blog/qubole-open-sources-multi-engine-support-for-updates-and-deletes-in-data-lakes/
- https://www.infoworld.com/article/3534516/is-your-data-lake-open-enough-what-to-watch-out-for.html
- https://www.qubole.com/blog/building-a-data-lake-the-right-way/
- https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions
- https://discover.qubole.com/whats_new/167
- https://gdpr-info.eu/
- https://en.wikipedia.org/wiki/Change_data_capture
- Andrew Eisenberg, Jim Melton, Krishna Kulkarni, Jan-Eike Michels, and Fred Zemke. 2004. SQL:2003 has been published. SIGMOD Rec. 33, 1 (March 2004), 119–126. DOI:https://doi.org/10.1145/974121.974142



