DATA FABRIC
Data Fabric vs Data Lake
By definition, a data lake is an operation for collecting and storing data in its original format, and in a system or repository that can handle various schemas and structures until the data is needed by later downstream processes.
The primary utility of a data lake is to have a single source for all data in a company — ranging from raw data, prepared data, and 3rd party data assets. Each of these is used to fuel various operations including data transformations, reporting, interactive analytics, and machine learning. Managing an effective production data lake also requires organization, governance, and servicing of the data.
The idea of a “Data Fabric” started in the early 2010s. Forrester first used the term in their published research in 2013. Since then, many papers, vendors, and analyst firms have adopted the term. The goal was to create an architecture that encompassed all forms of analytical data for any type of analysis with seamless accessibility and shareability by all those with a need for it.
Visit IderaDataFabric.com to learn how to create a successful Data Fabric for your enterprise.
How Data Lakes Contribute to Data Fabric
Qubole’s Data Lake platform stores large amounts of structured, semi-structured, or unstructured data in a central repository in its raw format to enable the data team to leverage insights in a cost-effective manner for improved business performance.
The platform provides end-to-end services that reduce the time, effort, and cost required to run Data pipelines, Streaming Analytics, and Machine Learning workloads on any cloud. It provides the right levels of security and governance, not only for data access but also for managing the data and the pipelines that the users are building.
Furthermore, it delivers built-in financial governance to help you optimize and reduce your cloud spending so that you can reinvest those resources in creating and running additional workloads to get even more value from your data.
And, as the leading provider of the Open Source Data Lake Platform, this is where Qubole contributes to Data Fabric initiatives generally whilst also being a component element of the IDERA Data Fabric.
Missed this webinar? Full recording now available on-demand
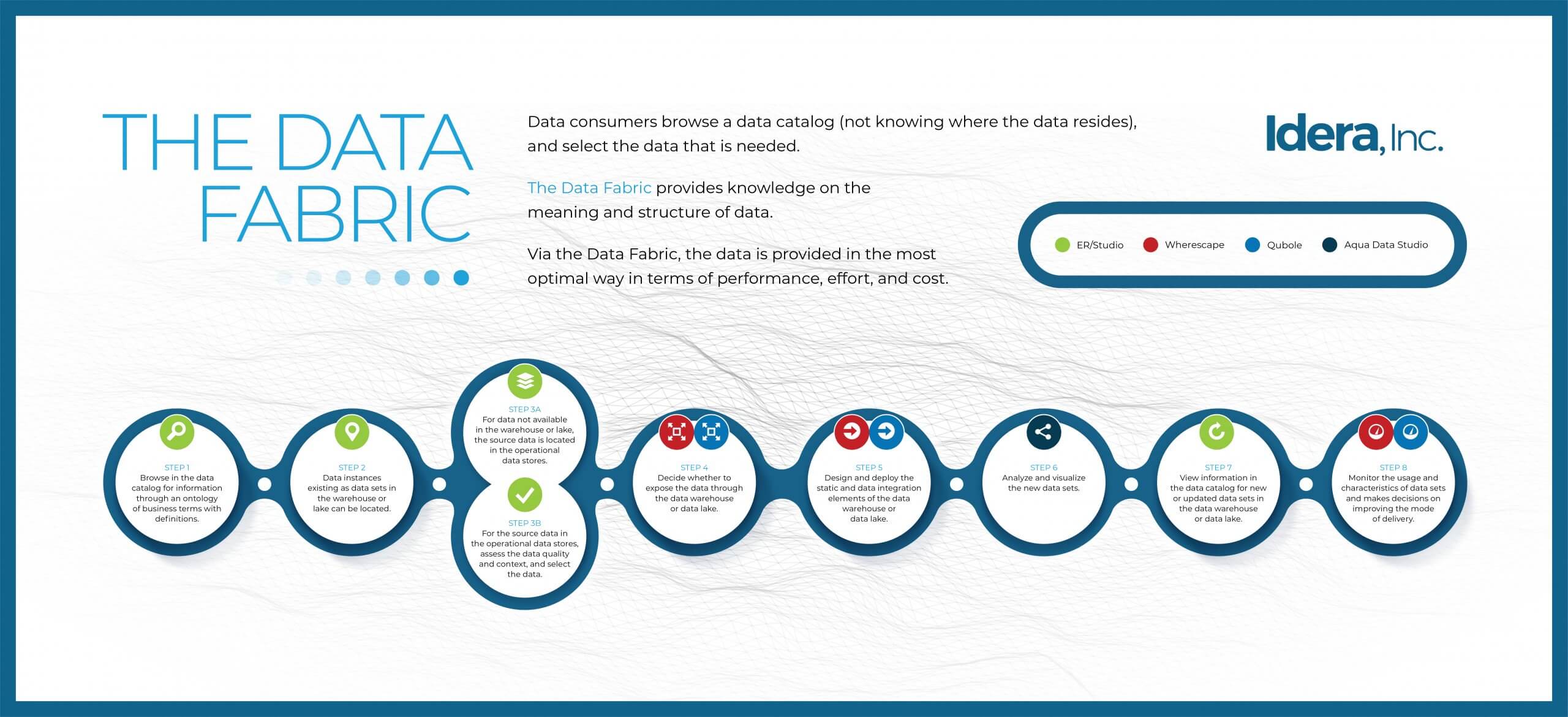
IDERA Data Fabric
For a wider understanding of the IDERA Data Fabric and to understand how key technologies are combined within a single framework to deliver improved efficiency and cost, improved availability, improved security and governance, and reduced risk we invite you to join our live webinar, presented by Claudia Imhoff, or you can request a copy of Claudia Imhoff’s Whitepaper.
Read our Whitepaper on: “Creating a Successful Data Fabric for Your Enterprise – Understanding the Data Fabric Processes and Technologies”.


