Both Qubole and Databricks are solving the same problem – enabling analytics and machine learning on data lakes. Moreover, if you are here because you are evaluating Qubole vs. Databricks or looking for Databricks alternatives, you are at the right place. There are many who love us more than Databricks due to the choice and openness, we bring to the table.
Where are you in your Data Lake Journey?

I am building a new cloud data lake
Whether you are migrating your on-premises data lake to the cloud or building a new data lake, Qubole offers:
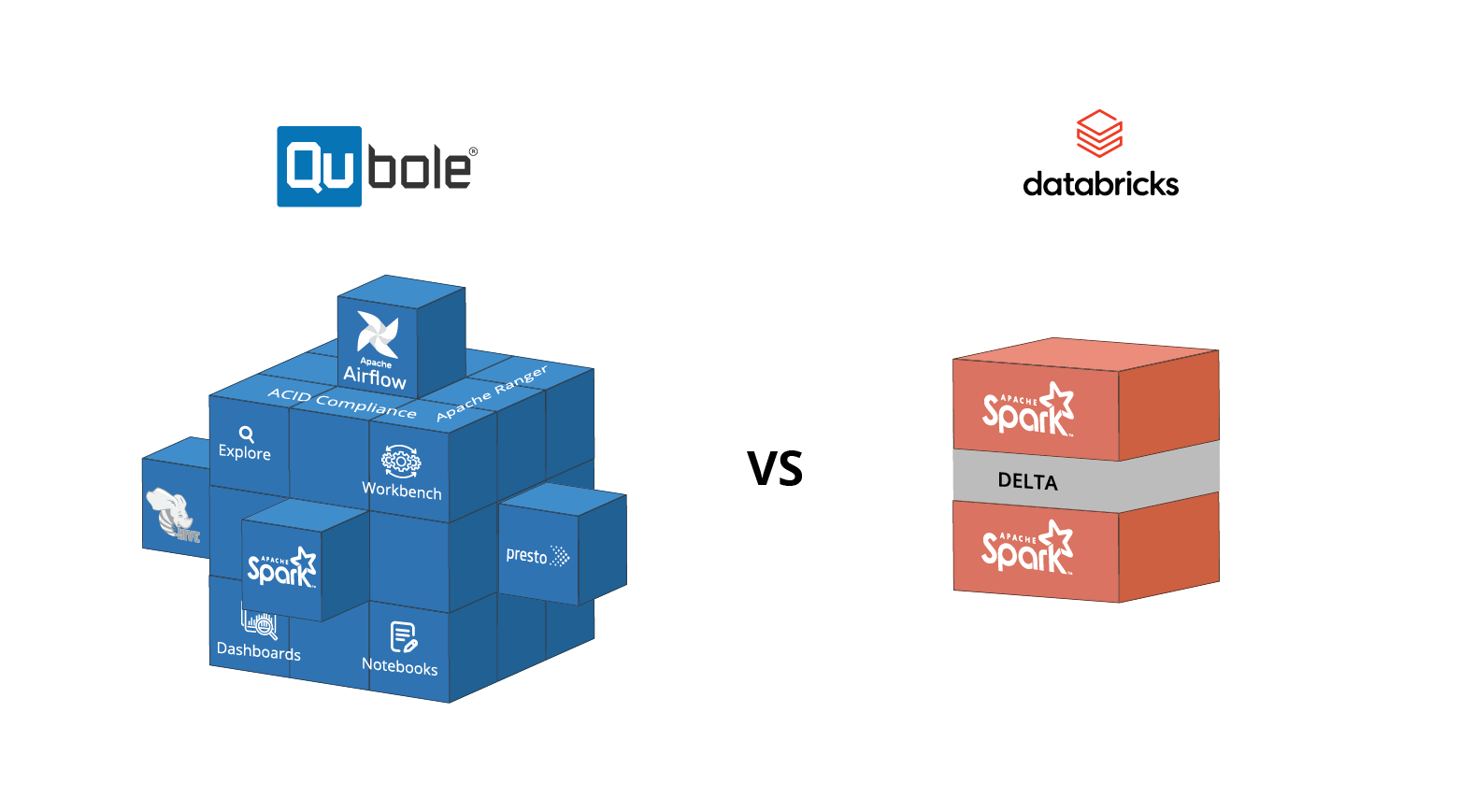
- Choice of cloud and data processing engines including Apache Spark, Presto, Hive, and more
- Qubole Notebooks, SQL workbench, dashboards, and pre-built integration with Tableau, Looker, RStudio, and more
- 10 times higher administrative efficiency
- 50% lower cloud costs
I want to augment my cloud data warehouse with a data lake platform
If you are augmenting your cloud data warehouse with a data lake platform, Qubole provides:
- Fast and cost-effective data processing
- Continuous Data Engineering to deliver rapidly changing data
- Combination of Data Warehouse data with any data source and capability to query from multiple data sources
- Cost savings by only storing critical data in the costly cloud data warehouse while also ensuring archived or hot data can be queried through standard SQL commands.


I want to replace my data lake platform
Whatever the reason is for replacing your data lake, Qubole has the capability to deliver:
- 50% lower cloud costs
- An end-to-end self-service platform built for multiple-workload
- Delivers 3 times faster time to value
- 10 times more users and data per administrator
- A self-service Open Data Lake platform built for all data users: data scientists, data analysts, and data engineers.
Accelerate Your Data Journey From Desktop To Enterprise Scale

Data Scientists
Enable end-to-end feature engineering at enterprise scale.
Address data wrangling, exploration, and model development needs.
Integrate with leading ML workflows and model deployment tools.

Data Engineers
Manage data pipelines efficiently and provide the flexibility of preferred programming language and data processing frameworks (Apache Spark, Presto, Hive, Airflow).
Provide fully automated and optimized infrastructure for SQL and Programmatic (Python, Scala) pipelines

Teams
Provide the relevant datasets to have baseline consistency with your analyst peers.
Ensure easy and single-click collaboration with your analyst peers by sharing your findings and model outputs for trend and pattern analysis.
Have ACID compliance and data masking across open source frameworks and public clouds.
Leverage IAM controls of cloud providers to give access rights to users
OPEN VS CLOSED DATA LAKE
- Move your first workload to Qubole, free for 30-days
- Stand-up an elastic cluster in a matter of minutes with your data on the cloud of your choice
- Add up to 5 users and get $700 of Qubole compute hours
- No credit card is required to get started!
GET TANGIBLE RESULTS WITH QUBOLE
Customers using Qubole Open Data Lake Platform
Qubole is trusted by customers all over the world with getting their data science and data engineering on the cloud right.
TESTIMONIALS






