Cloud native Architecture: What Is It, And Why Do You Need It?
Cloud-native architectures have become the new norm for enterprise deployments in almost every category. As the volume, variety, and velocity of data increase exponentially, the cloud offers a more efficient and cost-effective option for managing the unpredictable and bursty workloads associated with big data than traditional on-premises data centers.
This guide to cloud-native architecture will tell what you need to know about cloud-native data architecture and why we require it and why enterprises choose Qubole.
Let’s get straight into it.
What is Cloud Native Architecture?
Cloud-native architecture takes full advantage of the distributed, scalable, and flexible nature of the cloud, abstracting away many layers of infrastructure – networks, servers, operating systems, etc., and allowing them to be defined in code.
Going cloud-native means maximizing your focus on writing code, creating business values, and keeping the customers happy.
An open data lake is cloud-agnostic and portable across any cloud-native environment, including public and private clouds. This enables administrators to leverage the benefits of both public and private clouds from an economic, security, governance, and agility perspective.
An Open data lake ingests data from sources such as applications, databases, real-time streams, and data warehouses. It stores the data in a raw or open data format that is platform-independent.
And when done right, a cloud-native data lake provides a future-proof data management paradigm, breaks down data silos, and facilitates multiple analytics workloads at any scale capacity up or down depending on demand.
The data is stored in a central repository that is capable of scaling cost-effectively without fixed capacity limits; is highly durable; is accessible in raw form and provides independence from fixed schema; and is transformed into open data formats such as ORC and Parquet that are reusable, provide high compression ratios and are optimized for data consumption.
CLOUD-NATIVE ARCHITECTURE DIAGRAM
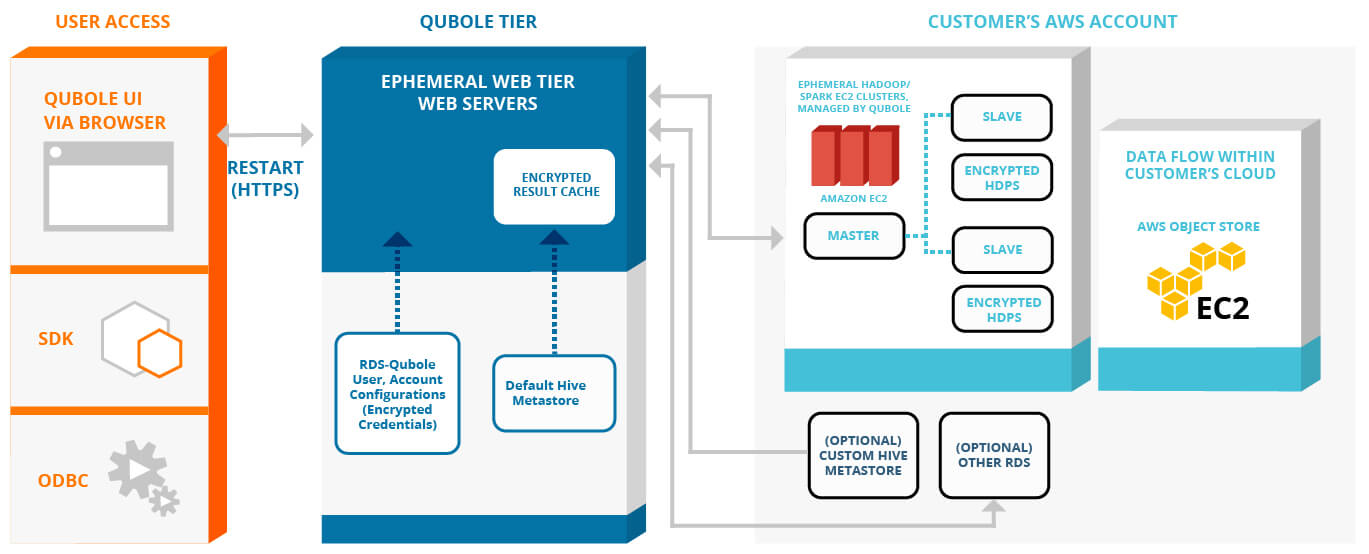
WHY WE REQUIRE A CLOUD NATIVE PLATFORM
According to a Statista survey, the global big data market is projected to reach USD 103 billion by 2027, more than double its projected demand in 2018. For all the promise big data holds, companies must stay focused and continue digital transformations by adopting a cloud-agnostic platform to improve the way they work with data, so they do not fall behind.
Over the last few years, the volume of data has grown at a blistering pace. Fast-growing mobile data traffic, cloud computing traffic, as well as the rapid development of technologies such as Artificial Intelligence (AI) and the Internet of Things (IoT) all contribute to the increasing volume and complexity of data sets. Gartner estimates that by 2022 more than half of the new major business systems will make business decisions based on real-time analytics.
Yet enterprises as a whole are leaving a lot of value on the table and face difficulties translating amassed data into actionable insights. McKinsey estimates that more than 70 percent of the potential value of all data is unrealized, and only one percent of big data captured in an unstructured format is analyzed or put to use.
In short, we are getting good at capturing a lot of data. However, ensuring this data is available to users to inform business decisions usually reveals significant problems with the economics of scaling and making data available across all consumption points.
To expand from a few focused projects and transition to a truly data-driven business — where data informs every business decision — organizations need to focus on a cloud-first approach. The scalability and elasticity of the cloud are very well suited for the bursty nature of big data workloads. There is no upfront cost for experimentation so you can scale capacity up or down depending on demand.
BUSINESS BENEFITS OF CLOUD NATIVE PLATFORMS
The cloud approach provides data teams with five key capabilities necessary to enable users access to data:
![]()
![]() Scalability: With the cloud, there are no limitations on the amount of data that can be processed. You can scale up resources when you need to match demand. This ensures that anyone who needs data processing can do so and only pay for the compute they use.
Scalability: With the cloud, there are no limitations on the amount of data that can be processed. You can scale up resources when you need to match demand. This ensures that anyone who needs data processing can do so and only pay for the compute they use.
![]()
![]() Elasticity: Provision or de-provision resources to meet real-time demand. You can change the capacity and power of machines on the fly, leading to greater agility and flexibility.
Elasticity: Provision or de-provision resources to meet real-time demand. You can change the capacity and power of machines on the fly, leading to greater agility and flexibility.
![]()
![]() Self-Service and Collaboration: Everything is API-driven. Users can choose the resources they need without requiring that someone else provision there for them.
Self-Service and Collaboration: Everything is API-driven. Users can choose the resources they need without requiring that someone else provision there for them.
![]()
![]() Cost Efficiency: The benefits are two folds:
Cost Efficiency: The benefits are two folds:
- First, the cost is on a usage basis as opposed to software licensing, so you only pay for what you use.
- Second, your operational costs are much lower because the cloud boosts the productivity of IT personnel.
![]()
![]() Monitoring and Usage Tracking: Finally, the cloud provides monitoring tools that allow organizations to tie usage costs to business outcomes, and therefore gain visibility into their Return On Investment (ROI).
Monitoring and Usage Tracking: Finally, the cloud provides monitoring tools that allow organizations to tie usage costs to business outcomes, and therefore gain visibility into their Return On Investment (ROI).
GETTING STARTED ON YOUR CLOUD MIGRATION
Enterprises can take a few different approaches when making their move to the cloud. These can be broadly categorized as:
Lift and Shift: In this approach, the entire on-premise software stack is replicated on the cloud to take advantage of the shift from CapEx to OpEx. This approach is a great way to get started and experiment on the cloud without a very significant upfront investment. The downside is that it does not take advantage of cloud features such as separation of compute and storage, autoscaling, and other cost optimizations.
Lift and Reshape: True generic cloud computing is adopted and is a minimum requirement for success with big data on the cloud. As organizations mature, they will be able to take a workload-driven approach to take advantage of the cloud’s elasticity. The IT team moves from estimating and provisioning for ‘what-if’ scenarios to a facilitator of business outcomes. However, technologies and tools in the big data space are continuously evolving, and it becomes very cumbersome to support all users and multiple use cases as new users are onboarded.
Autonomous Cloud Data Platform: This approach builds on top of the lift and reshapes by adding advanced features explicitly built to optimize costs and cloud computing for big data operations. Using a combination of heuristics and machine learning, big data cloud automation ensures workload continuity, the best performance, and significant cost savings. Automation of lower-level tasks makes engineering teams less reactive and more focused on improving business outcomes.
Several successful companies have leveraged Qubole’s cloud-native data platform to transition to the cloud and successfully use big data to improve business outcomes.
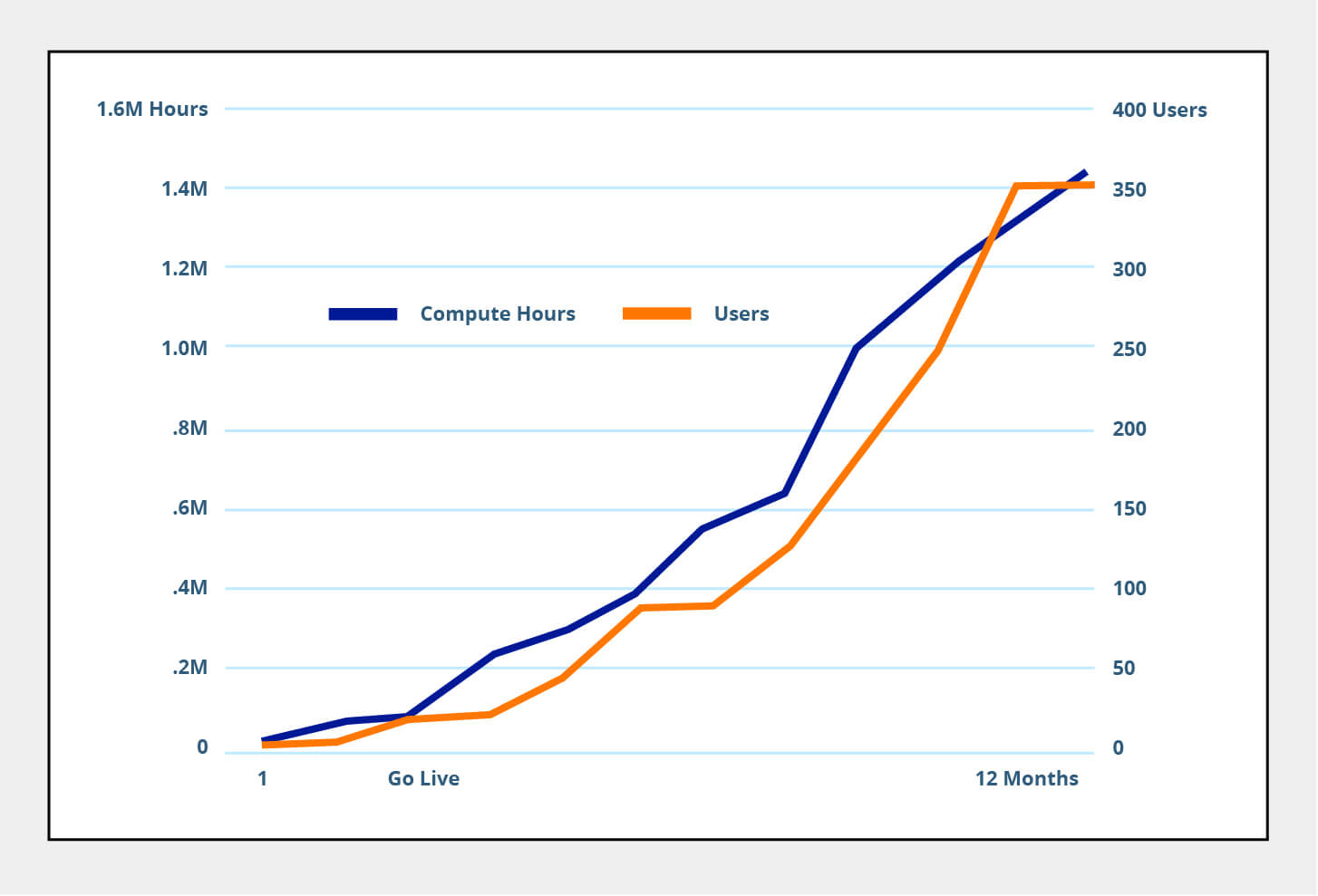
The chart below shows the activation growth of five customers who deployed Qubole. On average, they were able to onboard over 350 users in the first 12 months. They used an average of 1.5 million compute hours representing high data activation and multiple use cases.
Why Organizations Choose Qubole
![]()
![]()
3x faster time to value: Qubole delivers rapid innovation with self-service access to big data, enabling use cases that can be deployed in days — not weeks or months.
![]()
![]()
Single platform: Our platform offers a shared infrastructure for all users with the ability to leverage multiple best-of-breed engines. Qubole is massively scalable on any cloud, thereby preventing vendor lock-in.
![]()
![]() 10x more users and data per administrator: Qubole’s self-service platform enables administrators to input policy controls and controls user/group access privileges. The platform’s automation capabilities ensure that all users and workloads are provisioned.
10x more users and data per administrator: Qubole’s self-service platform enables administrators to input policy controls and controls user/group access privileges. The platform’s automation capabilities ensure that all users and workloads are provisioned.
![]()
![]()
50 percent lower TCO: Several cost optimization features allow users to leverage lower and cheaper compute.


