CLOUD DATA WAREHOUSING
What is a Cloud Data Warehouse?
Businesses rely on accurate analytics, reports, and monitoring to make critical decisions. These insights are powered by data warehouses that are optimized for handling a variety of information that feeds these reports. The information in these data warehouses is most commonly sourced from a combination of disparate data sources (e.g. CRM, product sales, online events, etc.). They provide an organized schema for the information that allows end-users to more easily interpret the underlying data.
GETTING STARTED IS EASY. TRY QUBOLE TODAY AND GET RESULTS.
Data Warehousing in the Cloud
Data warehouses were built to handle mostly batch workloads that could process large data volumes and reduce I/O for better performance per query. And with storage being tied directly with compute, data warehouse infrastructures can quickly become outdated and expensive. Today, with cloud data warehousing capabilities, companies can now scale out horizontally to handle either compute or storage requirements as necessary. This has significantly reduced the concern about wasting potentially millions of dollars from over-provisioning servers to handle bursty data requirements or a project that may only be short-term.
Cloud Data Warehouse vs. Cloud Data Lake
There are two fundamental differences between cloud data warehouses and cloud data lakes: data types and processing framework. In a cloud data warehouse model, you have to transform the data into the right structure to make it usable. This is often referred to as “schema-on-write”.
Cloud Data Lake
In a cloud data lake, you can load raw data, unstructured or structured, from various sources. With a Cloud Data Lake, it’s only when you are ready to process the data that it is transformed and structured. This is called “schema-on-read.” When you marry this operational model with the cloud’s unlimited storage and compute availability – businesses can then scale their operations with growing volumes of data, a variety of sources, and query concurrency, while paying only for the resources utilized.
Watch this video to learn how to scale beyond a data warehouse to meet customer demands
Modern Cloud Data Warehouse
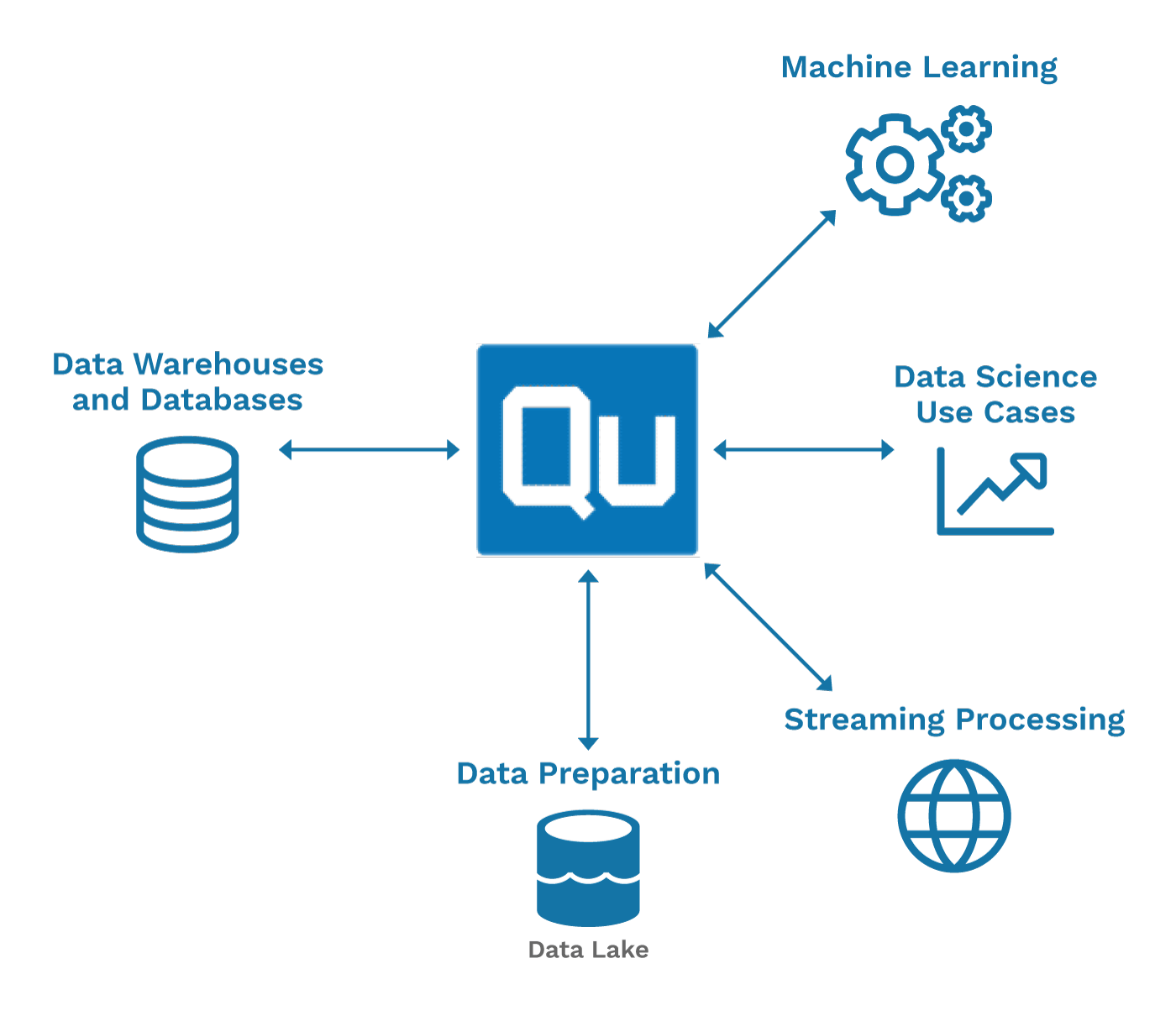
As companies advance in understanding the information they own, so does the need for improved infrastructure to handle the larger compute requirements to run complex analytics and workflows. This has paved the way for cloud infrastructures such as Informatica and Talend, which allow users to leverage compute for different technologies at their fingertips, all on top of the same data. With cloud infrastructure, companies can now grow their advanced analytics and ETL operations separately from their data warehouse workloads.
Using Qubole as the central cloud operations platform for the data lake, companies can seamlessly integrate with their data warehouses so that end-users can easily access data across their data lake and warehouses. This allows data teams to develop predictive analytics applications without disrupting the system that products and business intelligence rely on.
QUBOLE OPTIMIZED DATA WAREHOUSE SOLUTIONS

Object Storage
- Object Storage (AWS S3, Azure Blob, Azure Data Lake, Google Cloud Storage)
- Unified Metadata and Schema – Hive MetaStore

Data Store Integration
Data Marts (Cassandra, MongoDB, HBase) and Data Warehouses (Traditional Relational Database Managed Systems, Snowflake, SQL Server, AWS Redshift)

Data Processing Engine
- ETL (Hive and Spark)
- Interactive Analytics (Presto and Spark)
- ML and Advanced Analytics (Tensorflow and Spark)

Interfaces
- Qubole (UI, SDK, Notebooks, Dashboards)
- BI Softwares (Tableau, Looker, Apache Superset, Qlik, Mode)
- ETL workflow managers and schedulers (Apache Airflow, Oozie, Azkaban, Talend, Informatica)

User Security and Policy Management
- Access and Permissions control on data and compute access
- Separate teams based on compliance standards (SOC-2, PII, PCI, HIPAA, and more)


