Today at Google Cloud Next 2019, we announced the launch of Qubole Data Platform on Google Cloud — an easy, collaborative, enterprise service for advanced analytics, machine learning, and AI built on a modern architecture leveraging Kubernetes. From its inception, we have closely partnered with Google engineering and product teams to build and launch this service on Google Cloud. Qubole Data Platform on GCP offers data science and data engineering teams a rich and unified experience with built-in notebooks, dashboards, and an integrated workbench to execute any command, all available right within the platform.
Highlights of Qubole Data Platform on GCP
Unified Experience with Built-In End-User Tools
Qubole Data Platform offers built-in end-user tools for data scientists and data engineers, enabling self-service access and collaboration.
Data scientists can use native Qubole notebooks integrated with Apache Spark.
Key benefits to data scientists include:
- Build and train models using data stored in BigQuery or Google Cloud Storage.
- Develop models in multiple languages like Python, Scala, SQL, and R using Spark and Notebooks.
- Add additional packages easily and let the service manage dependencies for them.
- Collaborate with others using shared folders, Github, and Access Control Lists.
- Publish notebooks to dashboards for easy visualization and consumption of results by business users.
- Deploy models to production at scale using the Airflow service on Qubole.
Data engineers can use Qubole’s unified workbench to execute any command. Key benefits include:
- Easily preview data stored in Google Cloud Storage or BigQuery Storage.
- Import data into Cloud Storage using built-in connectors to multiple data sources.
- Create and execute commands via the API, SDK, or the UI workbench.
- Build, schedule, and deploy scalable pipelines into production using Airflow on Qubole.
- Monitor and debug jobs with easy access to command status and logs.
- Share command history with others to collaborate on jobs.
Enterprise Support for Big Data Engines
Qubole’s data platform is powered by performance-optimized versions of open source engines like Spark, Hadoop2, Hive, and Airflow to process big data for any analytics or machine learning use case on GCP. The platform offers several enhancements to these open-source engines including advanced caching, filtering, and join optimizations for enhanced performance. Additionally, Qubole’s specialized engineering and support teams offer customers premium 24×7 support for each engine-based service within the platform.
Advanced Automation
The platform offers advanced automation in multiple areas — from account setup to advanced cluster management — to deliver a superior self-service experience to customers. With sophisticated SLA-based autoscaling and termination of idle clusters, the tedious tasks of provisioning and managing clusters are handled by the service automatically, allowing your data teams to focus on drawing insights from data instead of managing infrastructure.
Enterprise-Grade Security
The Qubole Data Platform is built on the premise of ease-of-use, collaboration, and self-service access, while also including the right security measures to meet the demands of enterprises. The service offers integration with Cloud IAM to automatically set up service accounts needed to orchestrate cloud resources in a customer’s GCP project. At the same time, it uses fine-grained permissions to control Qubole access to customer projects.
While the platform allows users to easily share notebooks and commands, it also offers Access Control Lists to enable secure collaboration. Lastly, the platform supports Role-Based Access Control so service administrators can assign the right roles and permissions to end-users to limit their access to tables, clusters, and other resources within the service.
Day-1 Self-Service Access
Google Cloud users have convenient access to Qubole via GCP Marketplace and can easily sign up using their Google account. The service provides a seamless setup using either a simple automated option or a manual option using a guided script. It includes built-in connectors to multiple data sources like MySQL, Postgres, MongoDB, and BigQuery to provide fast access to data. It offers integrated billing via marketplace to give customers the convenience to receive a single bill from Google that includes their Qubole usage.
Integrated with Google Services
The service integrates with multiple Google Services to provide the best end-to-end experience for customers, including:
- Google Compute Engine – Customers have the choice to select from standard, high-memory, or high-CPU pre-defined instances to meet workload SLAs. The platform offers intelligent and reliable management of preemptible VMs to help customers lower their cloud costs.
- Google Cloud Storage – The service provides tight integration with Google Cloud Storage (GCS) with the ability to import data from multiple data sources into Cloud Storage, allowing customers to build a central data lake in GCS for data analytics needs.
- BigQuery – The service provides Spark and Hadoop connectors for BigQuery that allow these engines to directly read data in BigQuery Storage to enable efficient ETL and machine learning use cases directly from data in BigQuery.
- Cloud IAM – With Cloud IAM, customers can easily authenticate into the service using their Google Cloud account and use fine-grained custom roles to control Qubole access to compute and storage resources in their GCP project.
- GCP Marketplace – Customers can easily purchase Qubole from the GCP Marketplace with Qubole usage included in their GCP monthly bill.
Platform Architecture
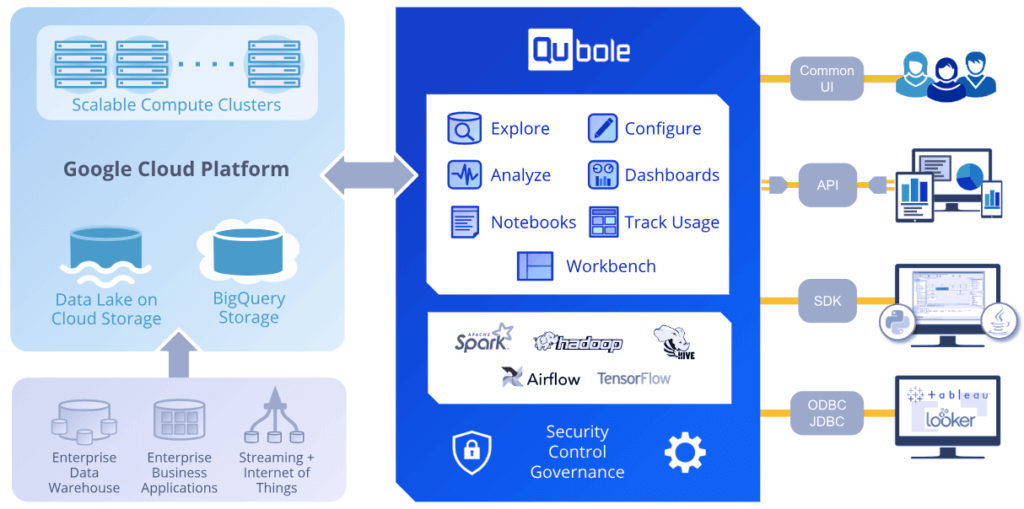
Qubole’s data platform is built on a modern scalable control plane using Kubernetes and hosted natively in Google Cloud. The control plane authenticates users into the service using their Google Cloud account and provides access via a User Interface (UI), APIs, or SDK. It provisions and orchestrates big data clusters within a VPC in the customer’s GCP project, and fully handles autoscaling of these clusters and their access to data stored in Google Cloud Storage and BigQuery storage.
The platform offers customers a choice of open-source engines like Apache Spark, Hive, Hadoop2, and Airflow with multiple optimizations for enhanced performance. It also provides a unified Hive metastore hosted in the customer’s VPC that acts as a central metadata store for all data within the data lake.
Once clusters are launched, customers can submit, monitor, and manage their jobs from either the Qubole UI, APIs, or SDK. They can use interfaces like notebooks to build their machine learning models, an integrated workbench to create and execute commands, and tools like Airflow to build and deploy scalable data pipelines to production. Benefits of the architecture are:
- Full control of data and compute — Qubole separates data and control tiers, enabling customers to retain full control since both clusters and data always stay in their Google project.
- Automatic scalability of users and commands — The Qubole tier is built on a modern architecture that leverages Kubernetes, which allows it to automatically scale to handle a higher volume of user sign-ups and concurrent commands.
- Unified, self-service experience — Qubole integrates tools and interfaces like notebooks, Airflow, built-in data connectors, and a command workbench to deliver a self-service experience to data engineers and data scientists.
- Lower costs and high reliability — Unlike other solutions, Qubole fully provisions, orchestrates, and autoscales clusters in the customer’s VPC based on a complete context of the workload, SLA, and priority of each job, including intelligent management of preemptible VMs.
Conclusion
We are very excited to partner closely with Google and launch the Qubole Data Platform on Google Cloud. We are confident that Qubole’s self-service data platform will enable data science and data engineering teams to explore, analyze, and derive insights from their data at scale. As we launch the platform in public preview on Google Cloud, we look forward to your feedback on the user experience and product capabilities to help you build enterprise data applications at scale.
To learn more, visit our Qubole on GCP webpage or sign up for a free trial of Qubole on GCP.



