Customers love that Qubole enables collaboration via a shared workbench across multiple analysts in an organization. Increasingly though, we have started finding use cases where organizations want to share data across Qubole accounts. Departments in different geographies want to share selected data sets with each other. Also, organizations want to share data with their partner organizations.
In the first of our posts on collaboration – we describe how data in AWS S3 can be shared across Qubole accounts in a secure manner using AWS IAM Roles and Policies.
Data Sharing in AWS
AWS exposes multiple security mechanisms like IAM policies, bucket-level policies, and S3 ACLs which allow controlling access to various S3 resources:
- S3 ACLs can be configured at an S3-bucket/object level but if a large number of objects are being shared then it becomes increasingly difficult to maintain these ACLs as there is no central place to manage them.
- In the case of bucket-level policies, there are constraints on the data size (~20 KB) of the policy.
- IAM Policies allow a concise way to describe access control policies on sets of S3 objects. IAM Policies can be attached to IAM Roles. IAM Roles can be assumed by users both within an AWS account and across AWS accounts.
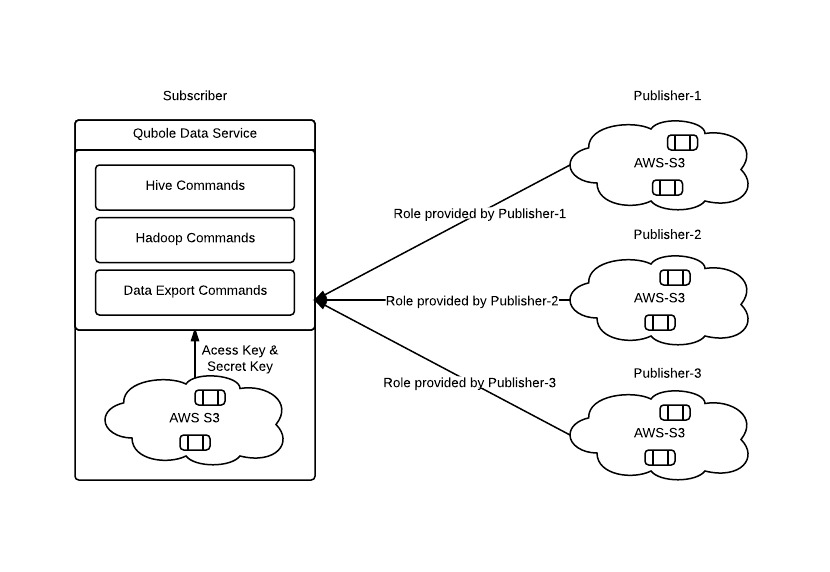
Based on this information and feedback from users, we chose to provide support to use IAM policies and roles to share data across Qubole accounts. The following workflow shows how this methodology can be used to share data with partners:
- The Owner of the data (also called the Data Publisher) creates a cross-AWS-account IAM role for each partner with the desired IAM policy to control S3-access as required.
- The Partner (also called Data Subscriber) can now log in using IAM-user credentials of their AWS-account and then assume this cross-AWS-account IAM role to access S3 resources delegated by the owner. Each partner needs the right to assume the role created on their behalf by the AWS account owner and hence be able to access the selected S3 resources when doing so.
Note that the owner and the partner can either use the same AWS account or (more commonly) different AWS accounts.
Integrating AWS Data Sharing in QDS
The Data Publisher (Owner) does not have to do anything in Qubole in addition to the above workflow. The Publisher may not even be a Qubole user.
The Data Subscriber (Partner) can analyze their own buckets in Qubole using their own AWS access/secret keys. In addition, the Data Subscriber can now analyze the data published by the Owner by assuming the role created by them.
Note that each Qubole user can be both a publisher and a subscriber. And a Qubole user may subscribe to data sets from different publishers as well.
Configuring Qubole as a Data Subscriber
- The Subscriber’s account storage credentials give the subscriber access to their own buckets.
This can be configured from the UI using the Flow: “Control Panel” -> “Account Settings” -> Storage Settings” -> “Aws access key & Aws secret key”
- In addition, the subscriber can set up a mapping listing of the publisher’s buckets and the role that has been granted access to them. The mapping is captured in JSON as follows:
{“s3-bucket-1”:{“roleName”:”AWS-Role-1-ARN”}},
“s3-bucket-2”:{“roleName”:”AWS-Role-2-ARN”,”externalId”:”AWS-Role2-External-id”}}
The mapping described above declares that role of AWS-Role-1-ARN must be assumed for access to any resources in bucket s3-bucket-1 and similarly AWS-Role-2-ARN must be used for access to resources in bucket s3-bucket-2. An external id is required for all cross-AWS-account roles.
So, this notation allows a subscriber to subscribe to data from many different publishers both within the same AWS account and outside of it.
- This mapping must be passed down to any software reading data off AWS S3. The bulk of the data processing technologies offered by Qubole uses a common substrate of Hadoop components (The S3 Native FileSystem and the Jets3t library) to read data off AWS S3.
In QDS, these configurations are stored on a per-Hadoop-cluster basis – and available through the UI at: “Control Panel” -> “Cluster” -> “Edit” -> “Override hadoop configuration variables”. The following variables need to be set to the json string above:
fs.s3.awsBucketToRoleMapping=…
fs.s3n.awsBucketToRoleMapping=…
Accessing cross-account Buckets through QDS
Once buckets have been set up for cross-account access in the manner detailed above, they can be accessed through the below set of commands:
- Data Processing Commands: Hive, Hadoop (ie. Map-Reduce), Shell Commands
- Data Export Commands
For example, the subscriber can query data in the Publisher’s buckets using Hive or even join such data with their own data. They can also export data from the Publisher’s bucket to their own RDBMS (for example RedShift).
 How it Works?
How it Works?
Whenever performing data access operations in AWS S3, QDS looks up whether a role has been set up for the S3 bucket. If yes, it assumes that role. AWS issues a temporary set of credentials, valid for a maximum of one hour when a role is assumed. QDS caches these credentials and uses these for subsequent data access. Before the temporary credentials get expired, QDS automatically requests a new set of temporary credentials.
Changes in Hadoop required for accessing S3 resources based on roles are being tracked in HADOOP-11038. The changes required to span across Hadoop and Jets3t.
Interested?
This functionality is now generally available and interested users can sign up for a free trial of QDS. If you have suggestions on how we can enable collaborative data processing in the Cloud, please feel free to ping us at [email protected]. We are also actively hiring and you can reach us at [email protected].



