Introduction
In an earlier blog post, we presented a secure, multi-tenant, reliable, and scalable service that provides access to logs and history for MRv2 applications. In this article, we will cover the challenges faced in scaling the aforementioned service for Tez applications and some approaches to overcoming those challenges.
Application Timeline Server
Application Timeline Server (ATS) was introduced in Apache Hadoop as a single generic service in YARN to store, manage, and serve per-framework application timeline data for both running and finished applications. ATS provides a REST client library that the Application Master (AM) can use to publish Application Timeline data.
The Tez framework is integrated with ATS and provides a UI that displays views of the Tez Application(s). Using ATS as the backend, the Tez UI displays diagnostics information about the applications, Directed Acyclic Graphs (DAG), vertices, and tasks. This information includes container logs, counters, configuration, start/stop time, and other data.
Ephemeral Clusters and ATS
Qubole Data Service (QDS) allows users to configure their clusters to autoscale based on the workload and shut down automatically when there is a period of inactivity. This results in substantial cost savings. ATS and the Tez UI server running on cluster master are responsible for storing and serving timeline data for applications running on that cluster. For debugging an application that had been running on a scaled-down cluster, users need to access its log, configuration, counters, etc. through the Tez UI. As ATS stores this data in the local file system, cluster termination results in data loss and makes it challenging to access Timeline Data once the cluster is terminated.
To remedy this, Qubole has provisioned a multi-tenant version of ATS and the Tez-UI server in the QDS Control Plane (henceforth called Offline ATS and Offline Tez UI respectively). The online Tez UI is used only when the cluster is running. Otherwise, the Offline Tez UI serves the request. Both these services let users access application logs and other data through a standard workflow, irrespective of the current state of the cluster.
Architecture with ATS v1
The first iteration of ATS, v1, uses LevelDB on top of the local file system to store Timeline Data. The architecture for Offline Tez UI with ATS v1 is similar to the Job History Server (JHS) described in the previous blog.
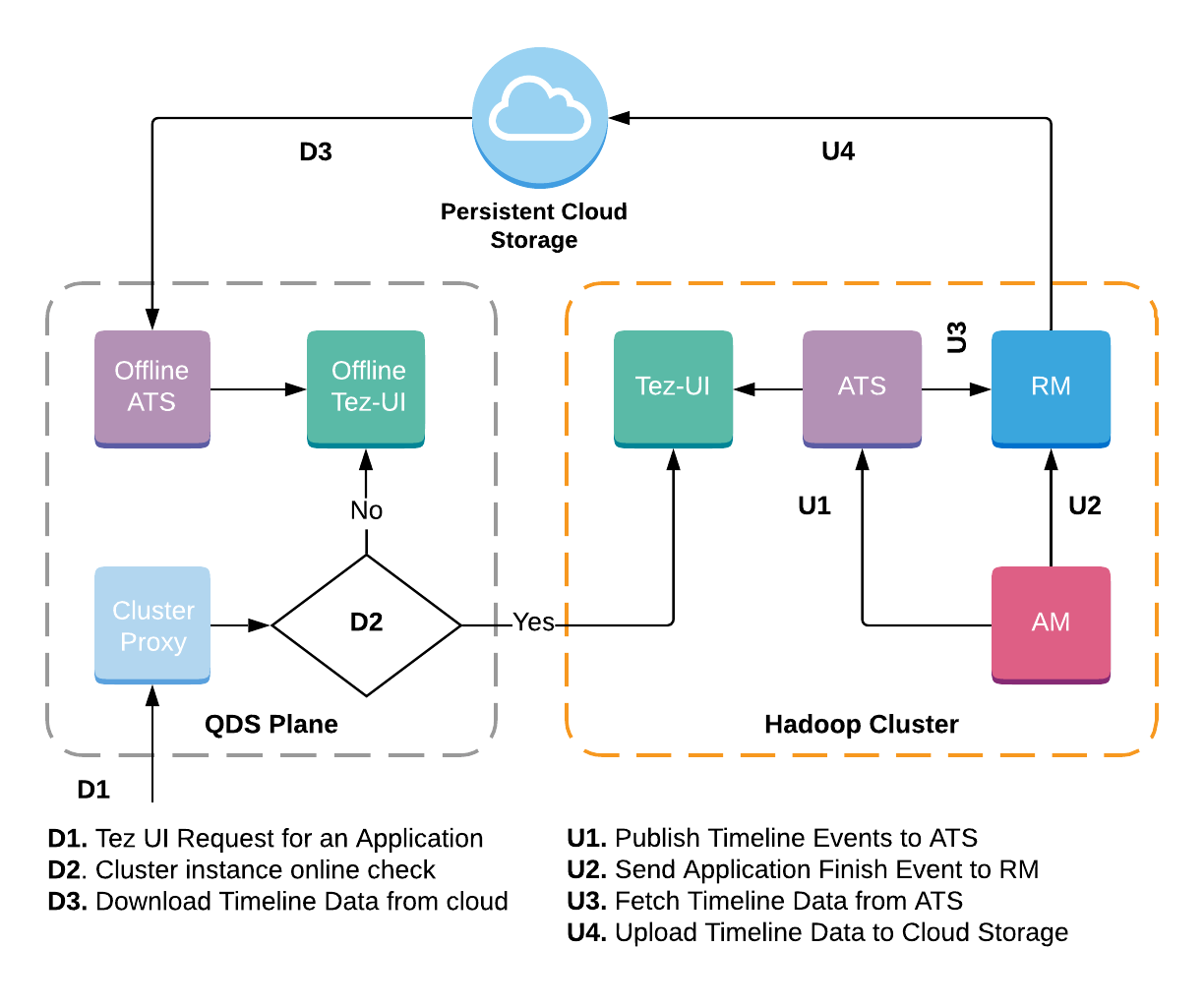
The diagram above illustrates the process. When a Tez application is running, the Application Master sends Timeline Data to ATS (U1). This Timeline Data is stored in the LevelDB Timeline Store that is shared across all applications running in the cluster. Once the application is finished, the AM sends a FINISH event to the Resource Manager (RM) (U2), and the RM fetches data from ATS for this application through the ATS REST APIs (U3). Once the data is fetched, RM creates a local LevelDB Timeline Store on this data, and the generated LevelDB files are then backed up to a Persistent Cloud Storage (U4).
Application Timeline data in the form of the LevelDB store can now be accessed even if the cluster is down. When Offline Tez UI is requested to view an Application (D1), Offline ATS consumes LevelDB files stored in the cloud (D3).
Shortcomings of ATS v1
Being a single point of contact for all Timeline Data related requests, ATS often suffers from performance, reliability, and scalability issues:
- Bottleneck as cluster scales: ATS uses the LeveldbTimelineStore by default. LeveldbTimelineStore does not scale well, as significant time is spent deleting old data. This becomes a bottleneck when a large number of concurrent applications are running on the cluster. The improved RollingLeveldbTimelineStore solves scalability issues to some extent, but that application also slows down when Timeline Data is on the order of 10GBs. This results in decreased throughput and increased latency for ATS’s web services.
- Delay in Tez AM termination: As the AM sends pending timeline data to ATS during the shutdown, the time required for the AM to close becomes proportional to the pending events queue size thereby introducing an additional delay. This delay can be on the order of hours for large queries, as it is proportional to the number of DAGs served by an AM which in turn is proportional to the number of tasks in a DAG.
- Potential loss of data: The AM and ATS are tightly coupled, as the AM writes events directly to ATS. If the ATS server is down, the events sent thereafter are lost and cannot be recovered. This leads to missing or inconsistent information in Tez UI.
- Single point of failure: As only one instance of ATS runs on the master node, if ATS goes down, Tez UI becomes unavailable.
Apache Hadoop introduced ATS v1.5 to overcome the aforementioned shortcomings.
ATS v1.5 Architecture
As mentioned, the LevelDB-based storage solution was unable to scale ATS, which caused delay and degraded performance. To overcome this, ATS v1.5 introduced a distributed architecture wherein the AM stores timeline data on a highly distributed and reliable Hadoop File System (HDFS). In ATSv1.5, the AM and ATS are decoupled. The AM writes data directly into HDFS, and ATS lazily reads data from HDFS on-demand. This ensures the AM is no longer a bottleneck when writing Timeline Events and allows better scaling.
Timeline Data is stored in two parts:
- Summary Data contains metadata about the Tez Application and DAGs. For every application, summary data is loaded from HDFS into the Summary LevelDB Timeline Store of ATS. This allows All DAGs and the Application pages to load faster by using summary data without contacting HDFS.
- Entity Data contains events about vertices and tasks of the DAGs. All these events are published in HDFS and read by ATS only when requested by Tez UI. This lazy loading keeps the data handled by ATS to a minimum so that it does not face scalability issues.
Offline Tez UI with ATS v1.5
The AM publishes timeline events by appending data to files stored in HDFS. Therefore, using a File System that supports the append operation is recommended for better performance. Due to this limitation, however, the AM cannot be configured to store data in a cloud-based Persistent FileSystem like Amazon S3.
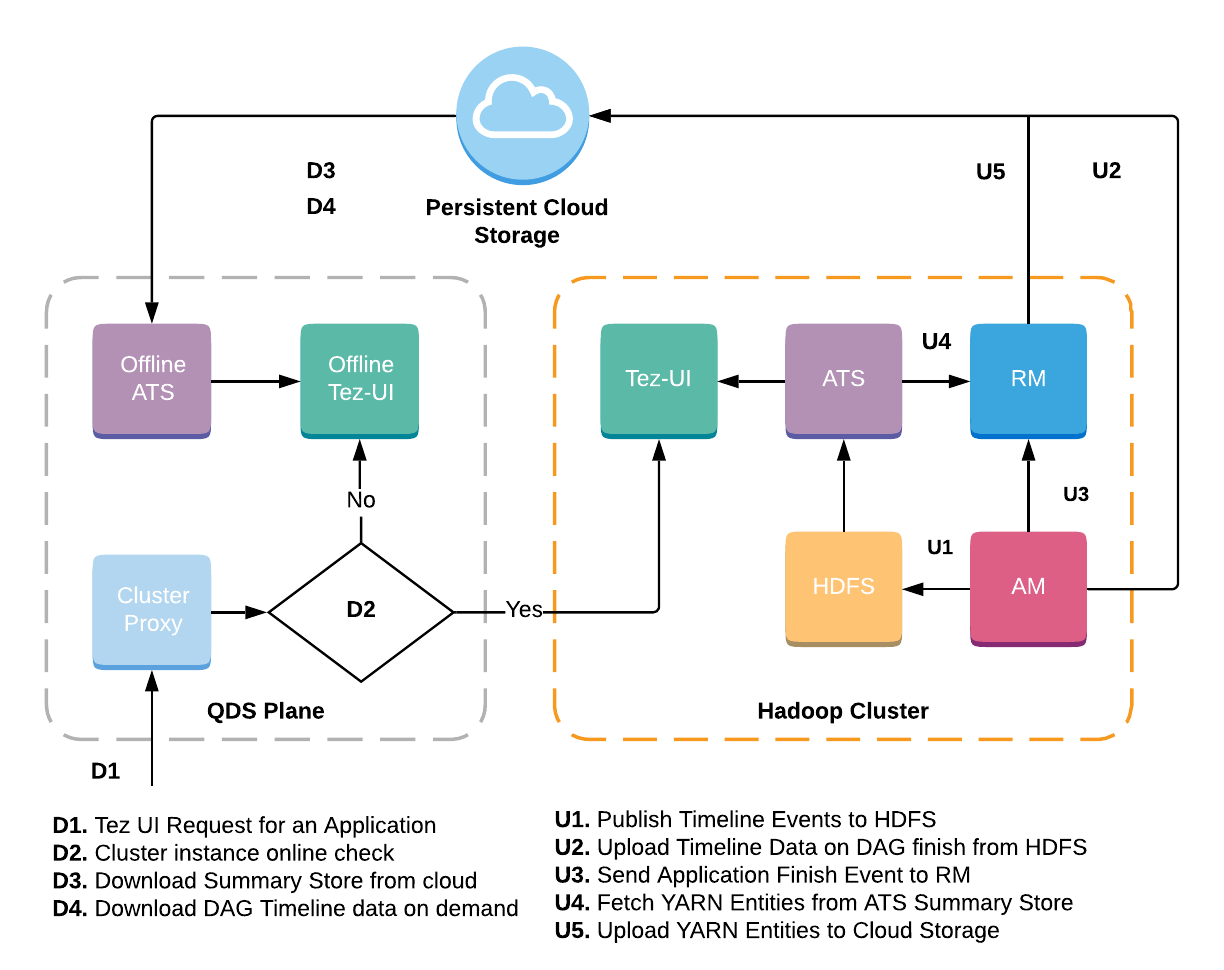
The architecture for Offline Tez UI with ATS v1.5 (shown above) is similar to ATS v1 (shown earlier) with the following differences:
- Timeline Data is published into HDFS by AM (U1).
- The AM uploads Timeline Data from HDFS to Persistent Cloud Storage when a DAG is finished (U2).
This change in storage architecture helped in making Offline Tez UI more efficient and reliable by limiting the amount of data fetched from ATS. For example, when the Application page is opened, only Summary Data(D3)is downloaded, whereas when a DAG specific page is opened, Tez UI fetches only the DAG’s Timeline Data from ATS (D4).
Advantages of ATS v1.5
Using ATS v1.5 provides the following advantages:
- Scalability: Unlike ATSv1, the AM writes data to HDFS which removes the dependency on ATS and helps it scale, even for large queries.
- Fault-tolerant: In the event of a failure within ATS, the AM is not affected and will continue to write data to HDFS.
- Reduced AM termination time: In ATS v1.5, due to its improved performance, the backlog to be processed during AM termination tends to be negligible. This improves the AM termination time.
Offline TezUI: ATSv1 vs ATSv1.5
By consuming ATS v1.5 as the backend service for Tez UI, several improvements were achieved over ATS v1.

ATS v1.5 is available for our customers using the Hadoop cluster with Hive 2.1 and 2.3. No action is required on the customer’s side as this is enabled by default. ATSv1.5 will be supported in Hive 3.1 in a future release.



