Qubole introduced first-generation Caching for S3 files in Presto in 2014 and documented the observed performance gains. In a nutshell: for CPU-efficient engines like Spark and Presto, performance is improved by caching remote files on local disk storage, removing bottlenecks in network IO. Our users also benefited from these performance gains, as this blog post from MediaMath attests.
Today, we are introducing RubiX, the next-generation local disk cache for Presto. RubiX is our next-generation disk cache for cloud storage systems that works across different big data engines and solves some key problems in our first-generation cache. We have decided to open source RubiX, and you can find it at https://github.com/qubole/rubix.
Background and Prior Work
Our first-generation caching system was designed exclusively for Presto. We wrote a new FileSystem, implementing Hadoop’s FileSystem interface. Presto used this new FileSystem to access S3. This file system maintained a cache of files. The first read request to an S3 file would bring that file to the local disk. Then any subsequent requests on the same file were served from the local disk. The OS page cache transparently provided in-memory caching for data sets that fit within the RAM.
Drawbacks
The first-gen system cached whole files. This led to large penalties warming up the cache for workloads that queried data stored in columnar layouts (such as ORC and Parquet) and accessed only a small subset of the columns. The overhead stemmed from reading entire files while loading into the cache when only small portions of it were required by such queries. Caching whole files could also lead to inefficient usage of memory and disk resources.
We also, rather than restricting it to just Presto, wanted to build a caching mechanism available to all the big data engines Qubole offers: Hadoop, Hive, Presto, Spark, and Tez. The first-gen cache was tightly coupled with Presto as the Presto’s scheduler was changed to schedule all splits from the same file on the same node. We needed a cache that could be utilized across all engines, ideally without any changes to the engines themselves.
Another roadblock to making this available to all engines was that not all engines run as long-running servers. In Presto, the Presto server in each node is a long-running process. All queries are handled by the same server hence sharing the cache amongst queries is easy. But with engines like Hive, Spark, and Tez, where each query can start its own process/JVM, the cache needs to be laid out so that different processes can share the cache to actually make it useful.
To summarize, the improvements we wanted to make to the first-gen cache included:
- Better caching for tables in columnar storage layout to only cache columns being accessed.
- Make the scheduling logic independent of Presto in order to provide caching capabilities to all engines.
- Allow the cache to be shared across multiple JVMs/tasks (since some engines use several per machine).
And of course – all these objectives had to be attained without compromising the performance of the first-gen cache.
RubiX and Alternatives
Before we finalized building our own solution, we looked at some of the existing options that we could leverage.
We looked at S3 fuse filesystems like s3fs, s3ql, etc. We envisioned mounting an S3 bucket locally and leveraging the OS page-cache for performance improvements. But all these filesystems required full control over the S3 buckets and any updates to the buckets from outside these file systems would lead to data corruption, so these were not realistic solutions.
Next, we tried HTTP caches, where Varnish Cache seemed to be the best in class. We ran Varnish in all nodes, routing all traffic to S3 via Varnish. We ended with a setup very similar to the one in this post from Moz. It solved all of the issues mentioned above, but it was a key-value-based cache where the key can be the filename or filename:byte-range. This brings down the cache hit to unacceptable numbers because depending on the query, the byte-range requested for files changes, thus changing the key and creating many duplicate copies in the cache. It performed well for text formats where a whole file needs to be read every time, but with columnar layouts like ORC, it performed worse than direct access. Since columnar layouts are a major use case for us, we had to pass on this option too.
Finally, we decided to write our own framework to achieve this, and work on RubiX started as a result. Roughly the main changes to RubiX are:
- A new implementation of the Hadoop FileSystem interface (similar to the first-gen Cache) to smoothly integrate with all the engines.
- Push the caching logic into FileInputStream of the new FileSystem to get better control over what we cache.
- Moved the logic of split allocation into the FileSystem itself.
- Extracting out the state of cache from FileSystem into a separate process.
The next section covers these improvements in detail.
Improvements in RubiX
Columnar Caching for faster warm-up times
There are two viable options for doing this:
- Caching at table level where we have the information about columns and cache the data for the columns that are read. We tried, a long time back, to cache individual columns in files, and this approach we knew was fraught with intractable issues when the number of columns is large. Too many small files can be created and based on our prior experience with this approach, we chose not to go down this route.
- Cache in the filesystem level, which does not know about the constructs like tables and columns but works on the level of files and byte ranges. We chose to do it in the FileSystem in order to keep the cache independent of the engines.
For this, we divided each file into logical blocks with configurable block sizes. For example, a 1 GB file in S3 is considered to be made up of 1024 blocks of 1 MB each. Each read request is now done in units of this block size and the blocks which are read for the first time are stored in a sparse file on a local disk. Thus only the parts of the files that are needed are loaded into the cache which improves the cache warm-up time considerably when only a subset of columns are used from the table.
Engine Independent Scheduling Logic
We leveraged the locality-based scheduling logic which all the big data engines have and that is used by HDFS as well. Let us consider HDFS to understand how it works. Assuming a replication factor of 1 in HDFS, each block of the file will reside on one of the nodes of the cluster. Schedulers retrieve the information about where the block is located and try to schedule the split on the node on which the block resides, thereby reducing the need for network IO.
On the same lines, RubiX decides which node will handle a particular split of the file and always returns the same node for that split to the scheduler, thereby allowing schedulers to use locality-based scheduling. The only difference being HDFS already has the block residing on some node, and it sends that information to the scheduler while RubiX uses consistent hashing to figure out where the block should reside. Consistent hashing allows us to bring down the cost of rebalancing the cache when nodes join or leave the cluster, e.g. during auto-scaling.
Shared cache across JVMs
All the data in the blocks reside on the local disk, so the only prerequisite to making the cache shareable amongst different jobs is making the state of the cache available to all jobs. For this, a cache manager is used, which is a lightweight server running on each node of the cluster that keeps track of the blocks of files that have been already brought onto the disk. Each job, while bringing in the blocks of a file to the disk, updates the cache manager with the new state, thereby making the information about the cached blocks available to all other jobs which can now use the cached data rather than going to S3.
Experimental Numbers
Setup
The initial release of RubiX targets Presto. We collected some numbers based on the following setup in QDS for AWS:
- Presto v0.119
- 3-node cluster, 1 master, and 2 slaves with no work scheduled on the master node.
- Node Type: r3.2xlarge
- Dataset: TPCDS scale500 in ORC Format
- Dataset Size: 51GB data with ~1.4 billion records
- Memory Configuration: Presto uses 70% of memory so ~18GB of memory per node is available to the operating system, a portion of which it will utilize for page-caching.
20 queries on this dataset were run 3x, repeated with the following three configurations:
- No caching
- File Caching
- New Block Caching
The full list of queries is available here. These queries were taken from this benchmark post, as they provide a good mix of interactive and reporting queries. We have added another query here to demonstrate a needle in the haystack use case.
An improvement over direct access to S3
This chart plots the time taken without caching vs the time taken with RubiX
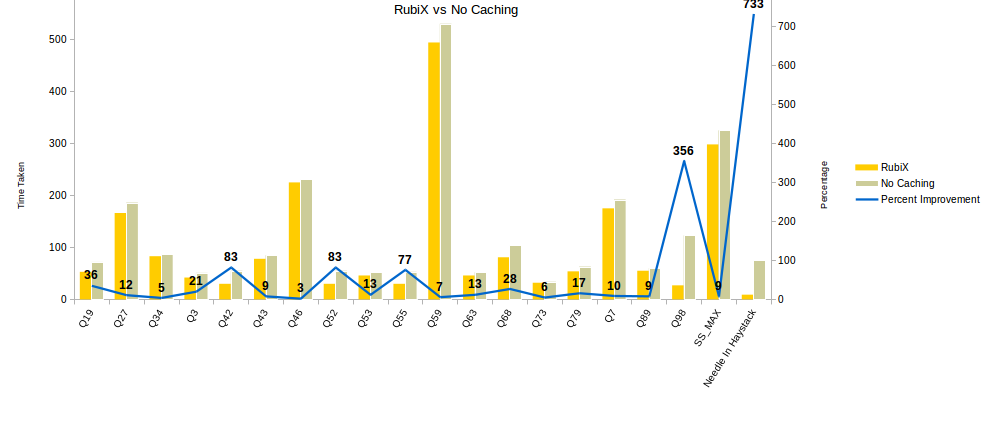
We saw improvements as big as 8x, with the more data being read in a query the higher the improvements. Some queries, as seen in the chart, only saw a slight improvement because they were not compute-intensive. In such cases, a cache is not of as much benefit.
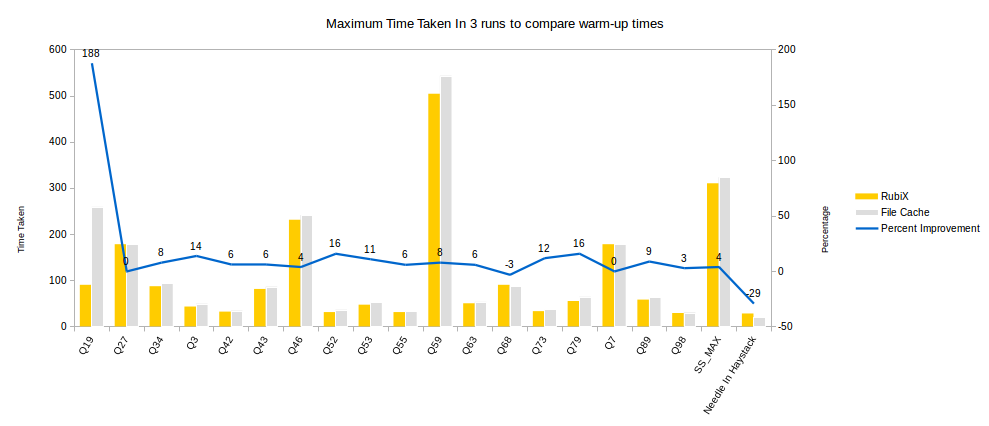
Warmup time w.r.t. File Caching
To compare the warmup times, the maximum time taken out of 3 runs for each query was plotted, and as seen below, RubiX provided significant improvement in warmup times over the first-gen cache. The queries are run in the same order as mentioned in the chart below, and the first query in the first-gen cache faced the brunt of the warm-up phase while RubiX amortized the cost of warmup across queries and the impact of warmup was smaller as queries proceeded because each run which required some warm-up would utilize some of the cached data as well.
Conclusion
Our first-generation file caching provided considerable performance improvements to Presto. RubiX goes a step ahead and makes it possible to get those improvements in other engines as well while working great with the optimized columnar storage formats. We are working on providing this caching capability to Tez and Spark too, which would allow analysts to achieve better turnaround times without any manual intervention.
RubiX is now available for early access for Presto users on QDS. To try it out, drop us a mail at [email protected] to get it enabled for your account. You can also find the open-source code for RubiX at https://github.com/qubole/rubix.



