For most of our customers, an object storage service such as Amazon S3 is the source of truth for their data, rather than the Hadoop Distributed File System (HDFS) within the cluster. That’s because object storage services provide high scalability, durability, and storage security, all at low costs. Qubole users create external tables in a variety of formats against an S3 location. These tables can then be queried directly using the SQL-on-Hadoop engines (Apache Hive, Presto, and Spark SQL) offered by Qubole.
However, cloud object stores can create multiple challenges for the conventional file systems running a big data stack. Qubole has optimized Hive and Hadoop for object stores like S3. In our previous blog series, we presented various issues of running these stacks on data residing in S3 and techniques to solve them. Since then, we’ve applied some of those techniques to our Spark and Presto offerings too. Today, we’ll discuss one of those optimizations implemented to make Spark work better with different cloud object stores.
Cloud Object Stores Versus Conventional File Systems
One of the drawbacks of cloud object stores (such as Amazon S3 and Azure Data Lake) is that individual calls to read/write or list the status of an object may have substantially more overhead than in conventional file systems (including HDFS). This overhead can become significant if we are listing a lot of files/directories, or reading/writing many small files. However, these object stores also have some unique features like prefix listing that conventional file systems do not offer. In this blog, we will talk about how we use prefix listing to gain performance improvements in Spark.
Alter Table Recover Partitions – Background
All big data engines (Spark/Hive/Presto) store a list of partitions for each table in the Hive metastore. If, however, new partitions are directly added to the file system, the metastore (and hence the engine) will not be aware of these changes to partition information unless the user runs ALTER TABLE table_name ADD/DROP PARTITION commands on each of the newly added or removed partitions, respectively. However, users can run the ALTER TABLE table_name RECOVER PARTITIONS command, which identifies all of the new partitions added and updates the metastore with new information.
How Does It Work?
Partition recovery is a two-step process:
- Partition Discovery: Identify all of the partitions in the source dir`ectory of the table
- Update Metastore: Update the Hive metastore with the partition information identified in the first step
Let’s look at an example to understand this better. Suppose we have a table named table_1 that is partitioned by year, month, date, and hour columns. So a file of this table in the case of S3 will look like this:
s3://bucket1/warehouse/table_1/year=2018/month=3/day=23/hour=4/sales.parquet
Suppose we have 10 years’ worth of data. That means the total number of partitions = 10 (years) * 12 (months) * 30 (days) * 24 (hours) = 86,400 partitions.

Tcxxo identify these partitions, Spark firstly lists the directories present in the root table location (i.e. s3://bucket1/warehouse/table_1 in this case). That will give us the first-level partition directories present in this table. Then for each of these directories, it will again do another listing to identify the second level of partitions. It will continue to do this recursively until we cover all partition levels (i.e. four levels of partition in the example above). The total number of S3 calls made in this process is 86,400. Making a large number of API calls on an object store can be time-consuming, thus degrading the overall performance.
Once the partition information is available, Spark will update the metastore with the partition information. This is done using Hive’s internal alterTable API call. This step is also time-consuming, as this will require us to update the metastore database with the new information. The updating of the database happens in a paginated manner to prevent any throttling.
Optimization Done
In the Partition discovery mentioned above, to identify all the partitions of a table, we can use the prefix listing API of the object store. Using this, we have added support for the listStatusRecursively API in our file system implementation. This API allows us to list all files present in a directory recursively, i.e. all files present in the directory and all of its subdirectories. This way, we don’t need to make individual API calls for each subdirectory.
Using this API, we can reduce the total number of object store calls from 86,400 to roughly 18 in the above example (assuming the single object store list API call can return a maximum of 5,000 files). This improves the overall performance significantly.
Note that this will still require us to update the metastore with new partition information.
Performance Benchmarking
Benchmark setup
- Table Schema:
Partition Columns: year – String, month – String, date – String
Non-Partition Columns: orderId: Integer - Total partitions ~ 10000 [28 (years) * 12 (months) * 30 (days)]
Query
ALTER TABLE sales RECOVER PARTITIONS
Test Case: We tried three different scenarios on this table.
- Table Directory has 10,000 partitions – All partitions are already known by the metastore
- Table Directory has 10,000 partitions – The metastore is not aware of any of the partitions
- Table Directory has 10,000 partitions – The metastore is aware of about 9,000 partitions, and the remaining 1,000 partitions are new
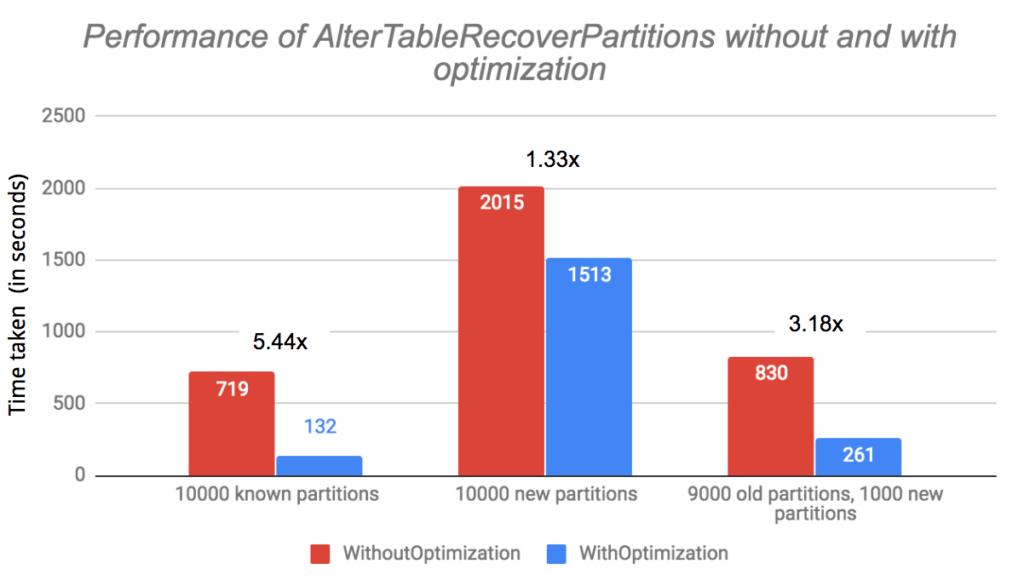
We can see that the improvement is much higher in a case when the new partitions are numerically lower. In all three cases, our optimization has helped the Partition Discovery step at the same proportion. But since the Metastore Update step takes a different amount of time in different cases, the overall improvement ratio changes.
Conclusion
Qubole includes these object-store optimizations that significantly improve the overall performance of running Hadoop-based engines on the cloud object store. These are just a few of the changes we have made so that data analysis is more efficient and performant for our users.



