This is Part 1 of 3
Snowflake Big Data
Snowflake and Qubole have partnered to bring a new level of integrated product capabilities that make it easier and faster to build and deploy Machine Learning (ML) and Artificial Intelligence (AI) models in Apache Spark using data stored in Snowflake and big data sources.
Through this product integration, Data Engineers can also use Qubole to read Snowflake data, perform advanced data preparation to create refined data sets, and write the results to Snowflake, thereby enabling new analytic use cases.
In this three–blog series we cover the use cases directly served by the Qubole–Snowflake integration. First, we will discuss how to get started with ML in Apache Spark using data stored in Snowflake. Blogs two and three will cover reading and transforming data in Apache Spark; extracting data from other sources; processing ML models; and loading it into Snowflake.
Snowflake Data Lake
Advanced analytics allows companies to derive maximum value from the critical information they store in their Snowflake cloud data warehouses. Among the many tools at the disposal of data teams, Apache Spark and ML are ideal for carrying out these value-generating advanced analytics.
The Qubole-Snowflake integration allows data scientists and other users to:
- Leverage the scalability of the cloud. Both Snowflake and Qubole separate compute from storage, allowing organizations to scale up or down computing resources for data processing as needed. Qubole’s workload–aware autoscaling automatically determines the optimal size of the Apache Spark cluster based on the workload.
- Securely store connection credentials. When Snowflake is added as a Qubole data store, credentials are stored encrypted and they do not need to be exposed in plain text in Notebooks. This gives users access to reliably secure collaboration.
- Configure and start up Apache Spark clusters hassle-free. The Snowflake Connector is preloaded with Qubole Apache Spark clusters, eliminating manual steps to bootstrap or load Snowflake JAR files into Apache Spark.
As the figure below illustrates, the process begins by adding Snowflake as a Qubole data store through the Qubole interface. Users can then select their preferred language for reading data from Snowflake, process it with machine learning algorithms, then write back the results to either Snowflake or any other storage or application, including dashboards, mobile apps, etc.
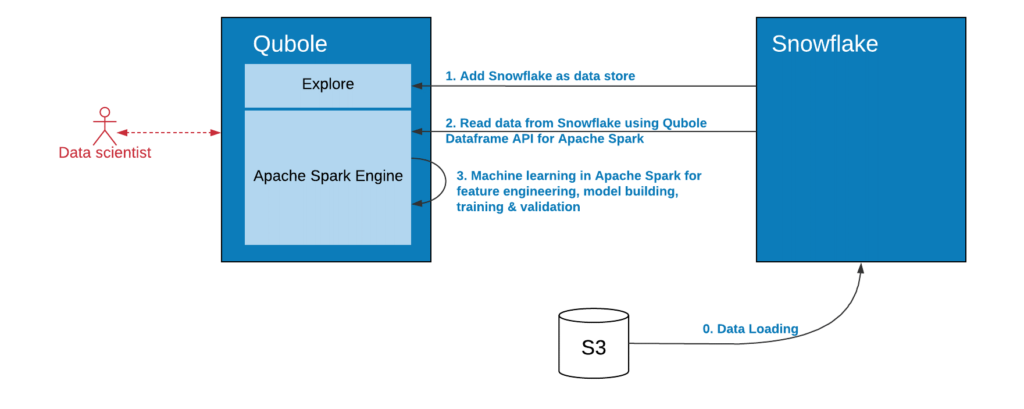
Snowflake Data Warehouse
If you’re ready to take the dive into Qubole–Snowflake integration for your own analytics projects, getting started is straightforward. The first step is to connect to a Snowflake virtual Data Warehouse from the Qubole Data Service (QDS). Administrators can do this by adding Snowflake as a Data Store–individual users can add a number of Data Stores to a Qubole account. These Data Stores are direct connections to Snowflake databases with configured credentials that are encrypted and protected by QDS. Non-administrator users cannot edit or see the credentials.
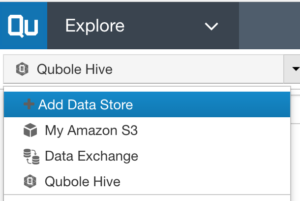
Here’s an example of a Snowflake Data Store created in QDS. A successful connection will allow users to explore tables in the Snowflake database.
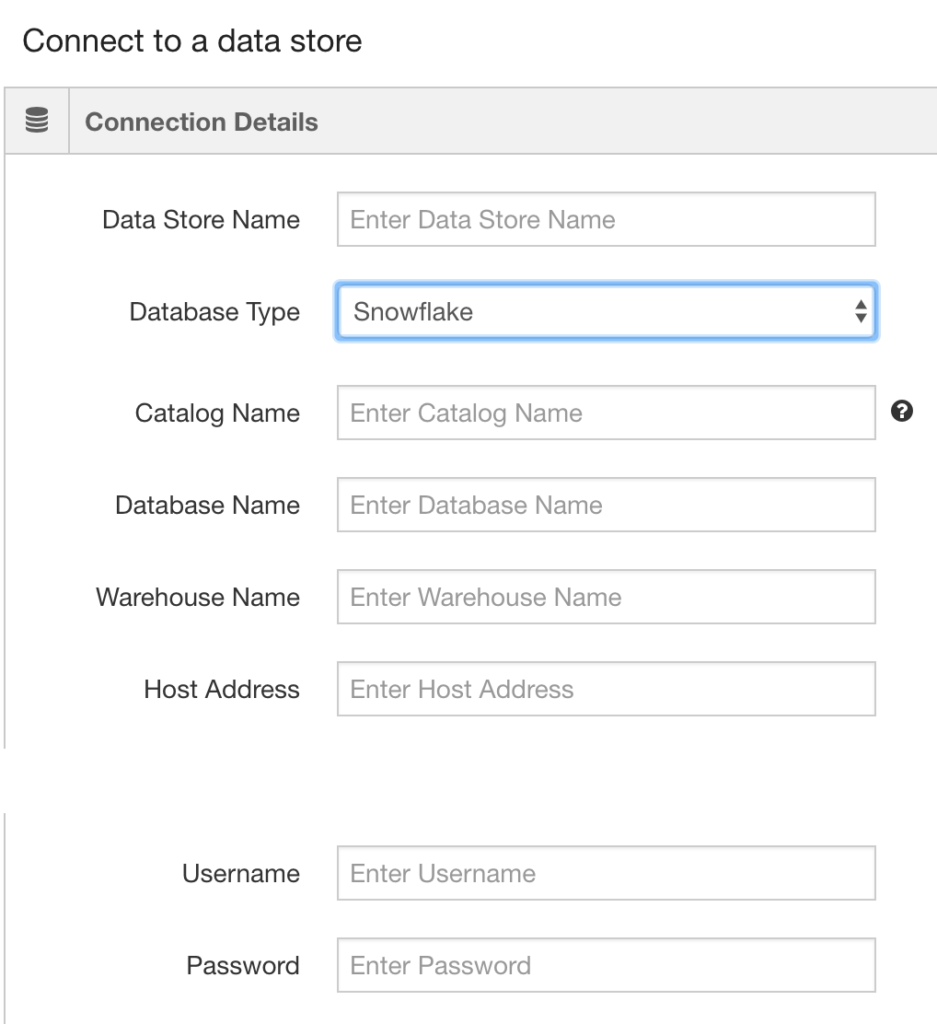
You will need to supply a few parameters for the connection:
| Catalog Name | This needs to be unique within an account. QDS will use this to retrieve encrypted authentication credentials. |
| Warehouse Name | This is the name of the virtual data warehouse in Snowflake.This information is only used to display a view of the database and tables in the Explore Page, and users may override this value when calling the API. |
| Database Name | This is the name of the database you’re connecting to in Snowflake.This information is only used to display a view of the database and tables in Explore Page, and users may override this value when calling the API. |
Once you’ve established a successful connection, the Explore interface will display all the available Snowflake tables and objects on the left pane, and the connection Properties on the right pane, as shown below.
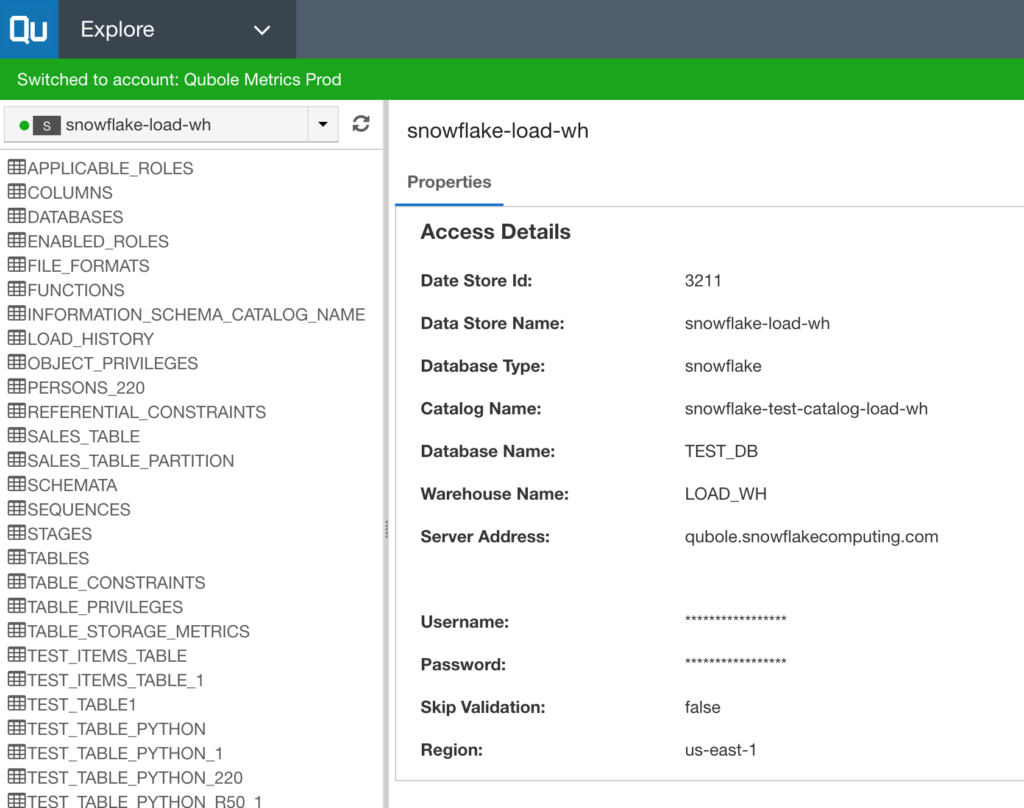
Snowflake Data Store
By adding Snowflake as a Data Store in a QDS account, QDS will automatically include the Snowflake-Apache Spark Connector in each Apache Spark Cluster provisioned in that account.
Once the Snowflake virtual data warehouse is defined as a Qubole Data Store, Zeppelin and Jupyter Notebooks can read and write data to Snowflake using Qubole’s Dataframe API with the user’s preferred language (Scala, Python, or R).
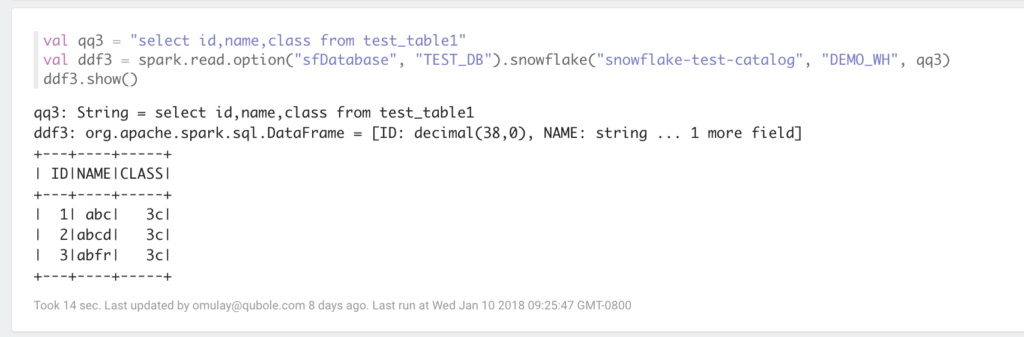
Below is a sample code in Scala used to read data from Snowflake using Qubole Dataframe API.
Spark Snowflake Connector
Qubole removes the manual steps needed to configure Apache Spark with Snowflake, making it more secure by storing encrypted user credentials, eliminating the need to expose them as plain text, and automatically managing and scaling clusters based on workloads.
Snowflake Integration
The integration between Snowflake and Qubole provides a secure and easy way to implement advanced analytics using Machine Learning and Apache Spark. Data teams can leverage the scalability of the cloud and the Qubole + Snowflake integration to easily build, train, and score models using data in Snowflake and big data sources.
For more information on Machine Learning in Qubole, visit the Qubole Blog. To learn more about Snowflake, visit the Snowflake Blog.
Read the next blog in this series to dive deeper into the advanced data integration use cases.



