Qubole now supports efficient updates and deletes for data stored in cloud data lakes. Users can make inserts, updates, and deletes on transactional Hive Tables—defined over files in a data lake via Apache Hive—and query the same via Apache Spark or Presto. Our changes to support reads on such tables from Apache Spark and Presto have been open-sourced, and ongoing efforts for multi-engine updates and deletes will be open-sourced as well.
In this post, we will describe this capability, the design choices, implementation details, and the future roadmap.
Motivation and Background
We have seen a lot of interest from users for an efficient and reliable solution for updates and deletions of data in data lakes, typically residing on cloud object storage systems. The traditional approach for such updates and deletions has been to overwrite the data at a partition level. This approach requires a rewrite of large amounts of data for even a few rows changed— and thus fails to scale efficiently. The need for a performant and cost-effective solution has also become urgent because of regulations like GDPR and CCPA.
After comparing different technological approaches, we selected Apache Hive’s ACID Transactions as the basis for update/delete support in Qubole. Hive Transactions are now supported in Qubole with Hive 3.1, and users can use Hive’s DML statement to append, update, and delete data in transactional tables in OrcFile format, and append data in Parquet format. We have also enhanced Presto and Apache Spark in Qubole to be able to read such transactional tables—and are contributing these changes back to open source. Our solution builds on Hive’s Metastore Server to provide both automated and manual compaction/cleanup services on data as it is mutated.
TL;DR: Dive right in!
Setup Guide for Open Source Users
- Users have to use Hive 3.0 and greater. If you are using older releases we recommend upgrading the Hive Metastore database and server to 3.1.2 directly. Older Hive versions, such as v2.3, can continue to work against Hive 3.1.2.
- For reading Hive transactional tables from Spark, users must use the Spark ACID data source available at https://github.com/qubole/spark-acid or use the corresponding Spark package directly with Apache Spark v2.4 or greater.
- For reading Hive transactional tables from Presto, users must build PrestoSQL from the master branch and apply the patch at PR-1257 (corresponding to the open issue PrestoSQL-576).
If you have any questions, contact us at [email protected].
Setup Guide for Qubole Users
- To enable reading/writing of Hive ACID transactional tables from Hive, please refer to the Qubole product documentation.
- To enable reading of Hive ACID transactional tables from Presto and Spark, please contact Qubole technical support.
Example Usage
Below is an example of a typical flow with a Full ACID table (limited to OrcFile format currently):
- Create a transactional table in Hive and insert some data
create table acidtbl (key int, value string) stored as orc TBLPROPERTIES ("transactional"="true"); insert into acidtbl values(1,'a'); insert into acidtbl values(2,'b');OR
- Convert an existing OrcFile non-transactional table to transactional with just a cheap metadata operation
alter table nonacidtbl set TBLPROPERTIES ('transactional'='true'); - Delete, Update, or Merge some data using Hive
delete from acidtbl where key=1; update acidtbl set value='updated' where key=2; merge into acidtbl using src on acidtbl.key = src.key when matched and src.value is NULL then delete when matched and (acidtbl.value != src.value) then update set value = src.value when not matched then insert values (src.key, src.value); - Read the results using Hive or Presto
select * from acidtbl;
- Read the results using Spark (Scala in the below example)
scala> val df = spark.read.format("HiveAcid").options(Map("table" -> "default.acidtbl")).load() scala> df.collect()
Transactional tables can also be declared over existing datasets in OrcFile format using Hive’s create table syntax with a pre-existing location and without requiring any data format conversions. Insert-only tables can be created over Parquet datasets in a similar manner. Refer to the Qubole product documentation for more details.
Technical Deep Dive
Why Hive ACID?
A number of open-source projects are tackling the problem of Multi-Version Concurrency (MVCC) and transactional updates and deletes to data in a data lake. The prominent ones are:
We ruled out Apache Kudu because it is not built for data in cloud storage. All the rest of the projects support snapshot isolation. We evaluated them on the following different dimensions, in no specific order:
- Support for updates and deletes
- Support for compaction and cleanup
- Support for Parquet and ORC formats
- Support for Hive, Spark, and Presto
- Support for SQL DML statements
- Write amplification
- Open-source governance
The table below summarizes our findings, as of this date. We have marked certain entries in red to indicate that they are problematic. Certain others are marked in green to indicate the strength of the given solution.
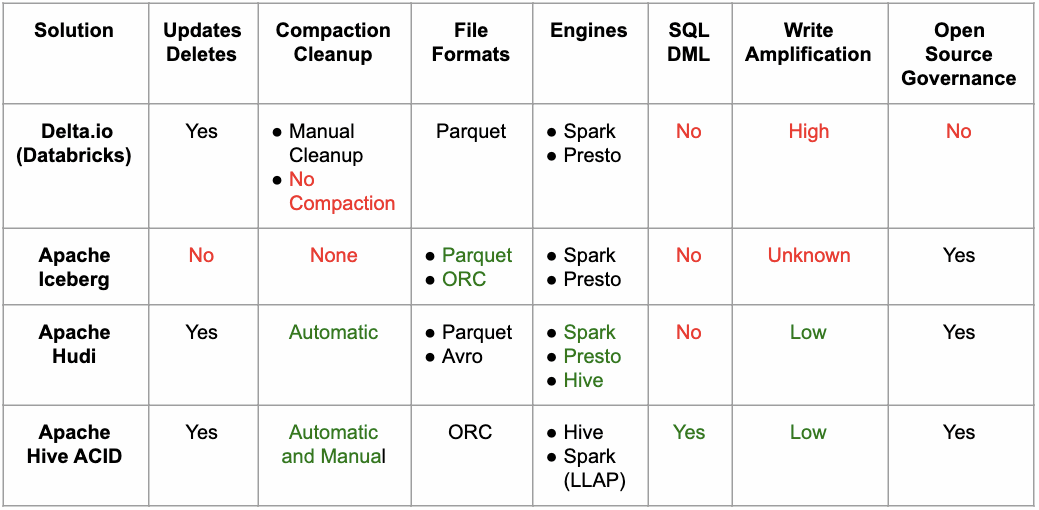
When we looked at the overall space we felt that it’s easiest to enhance Hive ACID up to the point where it fulfilled all of our requirements. More specifically:
- We would have to add read/write support for Hive ACID in Presto and Spark
- We would have to add update/delete support for Parquet format in Hive ACID
These development items are significantly easier because Apache Hive has a strong record of open source development and being open to contributions from the community. While this is a subjective call, we felt that the hurdle to a fully functional solution was significantly harder and would require significantly more time for the other choices. Some examples:
- Apache Iceberg is very promising, but the design for update/delete support is not finalized
- Apache Hudi seemed promising as well, but data ingestion seemed very tightly coupled with Spark, which we felt would have taken a lot of effort to extend to other engines.
- Delta.io is tailor-made for Spark and Parquet, but it has significant deficiencies in having high write amplification, lack of SQL DML support, and lack of compaction support. It also doesn’t have a well-defined open source governance model like the other projects on this list (which are all Apache projects).
So we are happy to build upon the work that Cloudera and the open-source community have done so far towards transactional support in HIVE.
How Hive ACID works
Hive ACID works (roughly) by maintaining subdirectories to store different versions and update/delete changes for a table. The Hive metastore is used to track different versions. We have made a quick animation to explain this below:
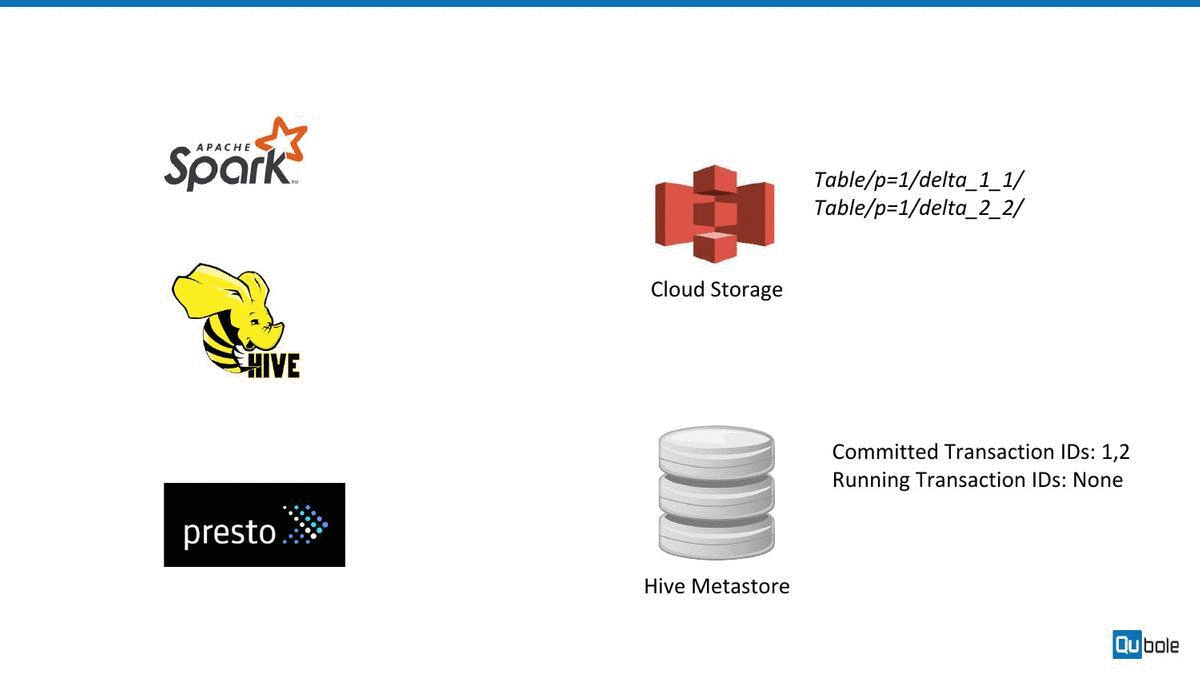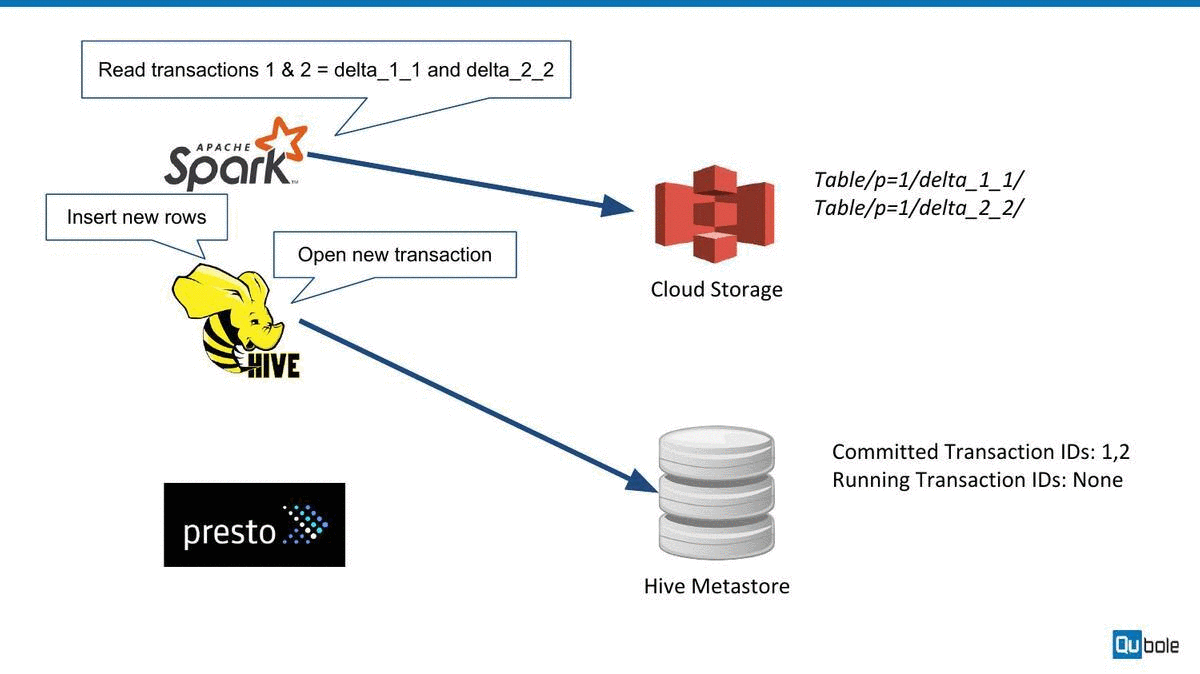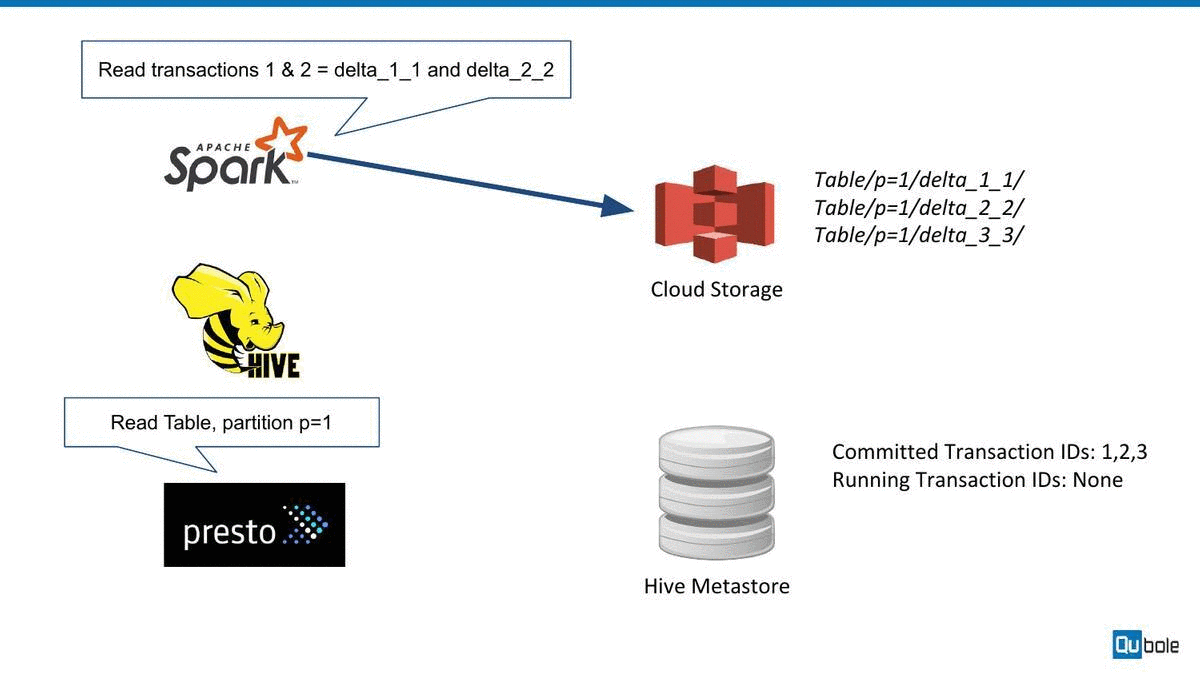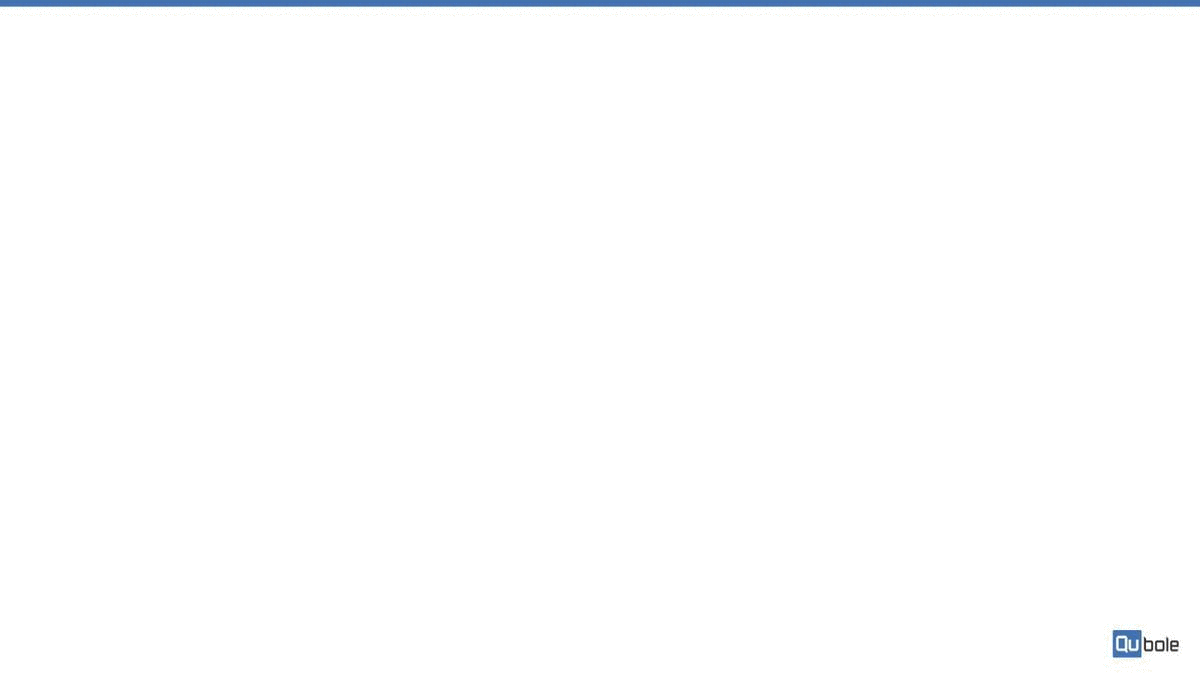
Challenges with Hive ACID
Hive ACID is predominantly used in environments that use Hadoop Distributed File-System (HDFS). Inevitably, attempts to use such software in the cloud run into teething issues because of differences in the semantics of cloud storage viz-a-viz HDFS. Two specific issues are worth highlighting.
- Renames are expensive on cloud storage — Apache Hive writes data to temporary locations first and renames it to the final location in a final commit step. Renames are expensive operations in cloud storage systems like AWS’ S3.
In order to reduce the performance impact due to this impedance mismatch, we have changed the behavior of Hive in Qubole to write directly to the final location and avoid the expensive rename step. This is an optimization Qubole has always had for regular tables—it is particularly appropriate for transactional tables since data for an ongoing transaction is not read by any queries. - Renames of directories are not atomic on cloud storage —Since renames of directories are not atomic, partial data can become visible in the destination directory. This is not a problem with transactional updates in Hive. But Hive ACID compaction in Hive 3.1 is not run as a transaction. As a result compactions (which perform a rename) are unsafe to run concurrently with a read operation. This is fixed in later versions of Hive via HIVE-20823. In Qubole we have solved this issue in Hive 3.1 using a commit marker in the destination directory (that the reader waits for).
Spark Implementation
As discussed, w are open-sourcing read support for Hive ACID transactional tables in Spark. We wanted to pick a design approach that was easily open-sourced. With this in mind, we gravitated towards a Spark DataSource-based implementation, which can be open-sourced as a third-party library and easily pulled in by users via the Spark packages channel.
We chose DataSource v1, as it is the more stable DataSource API at the moment. Some salient features of this implementation:
- It uses Hive’s readers (InputFormat) for reading Hive transactional tables; going forward it will use Hive’s writers (OutputFormat) for inserts, updates, and deletes as well.
- Talks to the Hive Metastore to get a current snapshot of the transactional table that can be read, and uses the same snapshot throughout the lifetime of the RDD.
- Does not acquire read locks on the Hive tables, and hence relies on the administrator to not delete data that might be being read. The administrator will need to disable automatic cleanup so that data is not deleted by the Hive Metastore.
- Will take write locks during data ingestion and update.
For more details on how to use the library is available, refer to the GitHub page. In our next Qubole Data Service release, we will make this available as a native library for Spark clusters.
Presto Implementation
There were two main challenges that we faced in Presto when adding support for reading Hive transactions tables:
- Reconciling Hive and Presto transactions —Presto has its own transaction management. We extended this transaction management to set up a Hive transaction for each individual query in a Presto transaction. Multiple Hive transactions (only one active at a time) can be a part of a Presto transaction. They are opened at the start of a query and closed at the end of the query; any failure in a Hive transaction fails the whole Presto transaction.
- Performant reader for Hive transactional tables —We evaluated multiple design choices for this and decided to extend Presto’s native ORC reader. Changes for this approach were more involved than the other alternatives, but it was the best option from a performance point of view. In this implementation, we ensured that transactional tables continue to use streaming split generation, utilize lazy materialization of data read, and do not suffer from the performance penalties that exist in Presto’s native ORC reader for STRUCT data types. This led to promising results in our benchmarks, which showed little to no penalties of performance in reading Hive transactional tables in comparison to flat tables.
What’s Next
We are currently working on enhancing Spark’s capabilities to provide enable the insert, update and delete transactions from Spark into Hive ACID tables. We expect it to be available in open source (and in Qubole) very soon. You can follow the Spark-ACID GitHub repo for the latest updates.
The Presto changes are in the process of being merged into open-source, and you can follow the Presto Pull Request #1257 for the latest details and patch.
We are evaluating adding update/delete support for Parquet datasets in Hive ACID. If you are interested in this (or have any other questions) – please feel to reach us at [email protected].
For further information or to request a demo contact us through your account manager or by filling out this form. For a free 14-day test drive of Qubole, Start Free Trial now.



