Co-authored by Hariharan Iyer, Member of the Technical Staff at Qubole.

Introduction
Big data engines like Hadoop and Spark are known to work well when running on homogeneous clusters. This allows the underlying resource manager to optimally place tasks on the nodes and also lets users tune their jobs as per the configuration of a single machine type. While this setup has performance benefits, in many use cases it can also lead to a higher Total Cost of Ownership (TCO) because of the inability to pick and choose instances (for a given cluster) based on the workload and the availability/cost of different instance types.
Today we are announcing the availability of Heterogeneous clusters on Qubole Data Service (QDS). Customers can now mix and match EC2 instances of different types within the same cluster – leading to significant cost savings and more reliable clusters. These instances can come from different instance families as well as different purchasing options (like On-Demand and Spot).
In working with early customers using this functionality – we have found heterogeneous Spot clusters save a further 60+% in costs over homogeneous Spot clusters. Homogeneous Spot clusters in QDS have already been observed to show savings of up to 80% over On-Demand clusters (and for this reason – are extremely popular with our customer base – with 50% of compute hours in QDS coming from Spot instances). With heterogeneous Spot clusters – we are now seeing these cost savings exceed 90%.
Background
Traditionally Qubole clusters have been homogeneous. While users can choose different instance types for master and slave nodes – all the slave nodes are of the same instance type. We have seen a number of issues with this approach:
- A specific region/AZ may run out of capacity for a given instance type. This may be unpredictable – and the user has no way to specify a fallback instance type
- In rare cases – a large cluster in certain regions/AZs may only be feasible by using multiple instance types
- Spot Fleet functionality allows a cost-efficient selection of instances across multiple instance types in the Spot market. The usage of this functionality is only possible by allowing the usage of multiple slave instance types in the same QDS cluster.
- With multiple instance types – it may also be feasible to choose instance types dynamically based on the workload running at any given point in time.
Heterogeneous clusters in QDS were inspired by these observations.
Heterogeneous Clusters
Heterogeneous clusters allow users to specify worker nodes of different types.
- The nodes may belong to the same family of instances (e.g. they may all be either m4.2xlarge or m4.4xlarge)
- They may even be from different families (e.g. an m4.xlarge and a c4.xlarge).
Users provide QDS an ordered list of whitelisted instance types that may comprise the cluster and associated instance weights. Heterogeneous clusters are complementary to other ways of configuring QDS clusters:
- Customers can continue to supply minimum and maximum sizes for auto-scaling purposes as before (where these sizes represent normalized sizes are described below)
- Customers can choose different purchasing options independently. Both On-Demand and Spot instances can leverage heterogeneous instance type specifications.
- Customers can choose different cluster composition options independently. For example, pure On-Demand, pure Spot, or Hybrid clusters – all work with heterogeneous instance type specifications.
Instance Weights and Normalized Cluster Size
In a homogeneous cluster, each instance has the same capacity. But this is not true for a heterogeneous cluster. For example, the compute capacity of an m4.4xlarge instance is twice that of an m4.2xlarge instance. While this may be obvious when the instances belong to the same family, it may not be as clear when they are of different types (for example when trying to determine to compute the power of c4.xlarge as compared to m4.xlarge).
QDS solves this by enabling users to assign weights to instance types. There is one primary instance type with a weight of 1.0, and all other instance types are weighted relative to this one. For example – the relationship between different nodes in the m4 instance family can be captured by the following enumeration of instance types and user-defined weights:
| Instance Type | Weight |
| m4.4xlarge | 1.0 |
| m4.2xlarge | 0.5 |
| m4.xlarge | 0.25 |
| c4.4xlarge | 0.5 |
In this case, m4.4xlarge is the primary instance type. To make the example more interesting, we have added instance types from a different family – the c4.4xlarge. We have given c4.4xlarge a weight of 0.5 because it has about half the memory capacity of an m4.4xlarge. At any given point in time – the cluster may be composed of a mix of these instance types now. Suppose the current cluster composition is:
| Instance Type | Weight | Number of Instances |
| m4.4xlarge | 1.0 | 5 |
| m4.2xlarge | 0.5 | 8 |
| m4.xlarge | 0.25 | 4 |
In the above scenario, we define the normalized size of the cluster as 5 * 1.0 + 8 * 0.5 + 4 * 0.25 = 10 – and this is the number used by QDS for auto-scaling purposes.
Instance Purchase Mechanics
- On-Demand Instance: While specifying a whitelisted set of instance types and weights – users also specify an ordering of instance types. QDS uses this ordering when purchasing On-Demand instances – purchasing instances by stepping through the instances types in the order specified until the desired capacity has been provisioned.
- Spot Instances: In this case, Qubole uses AWS Spot Fleet to provision heterogeneous spot instances. A one-time, lowest price pool spot fleet is created from the set of instance types and weights provided. AWS then automatically finds the cheapest combination of nodes of the different instance types that would fulfill the requested number of instances.
Customized Workload Sizing
When using heterogeneous clusters, one may not always be able to use the configuration of the primary instance type for Hive/Spark jobs. For example, one of the instance types in the configuration may not have sufficient memory to run tasks using the primary instance type’s configuration. To work around this problem, QDS uses the job configuration of the “smallest” instance type in the configuration by default. You can read more about how this works here.
Cost Savings
In this section, we present an analysis of real-world usage of heterogeneous Spot clusters that shows:
- > 60% savings compared to homogeneous Spot clusters
- > 90% savings compared to homogeneous On-demand clusters
Background: The power of Spot Fleet
The Spot instance price is set by Amazon EC2 and fluctuates periodically depending on the supply and demand of Spot instance capacity. It is often observed that the price of one particular instance type is very high while that of a comparable instance from a different family, or even a different instance from the same family, is very nominal.
Examine the following Spot price graphs of c3.4xlarge and c3.8xlarge instances. Note that the y-axis scales are logarithmic and different for the two graphs.
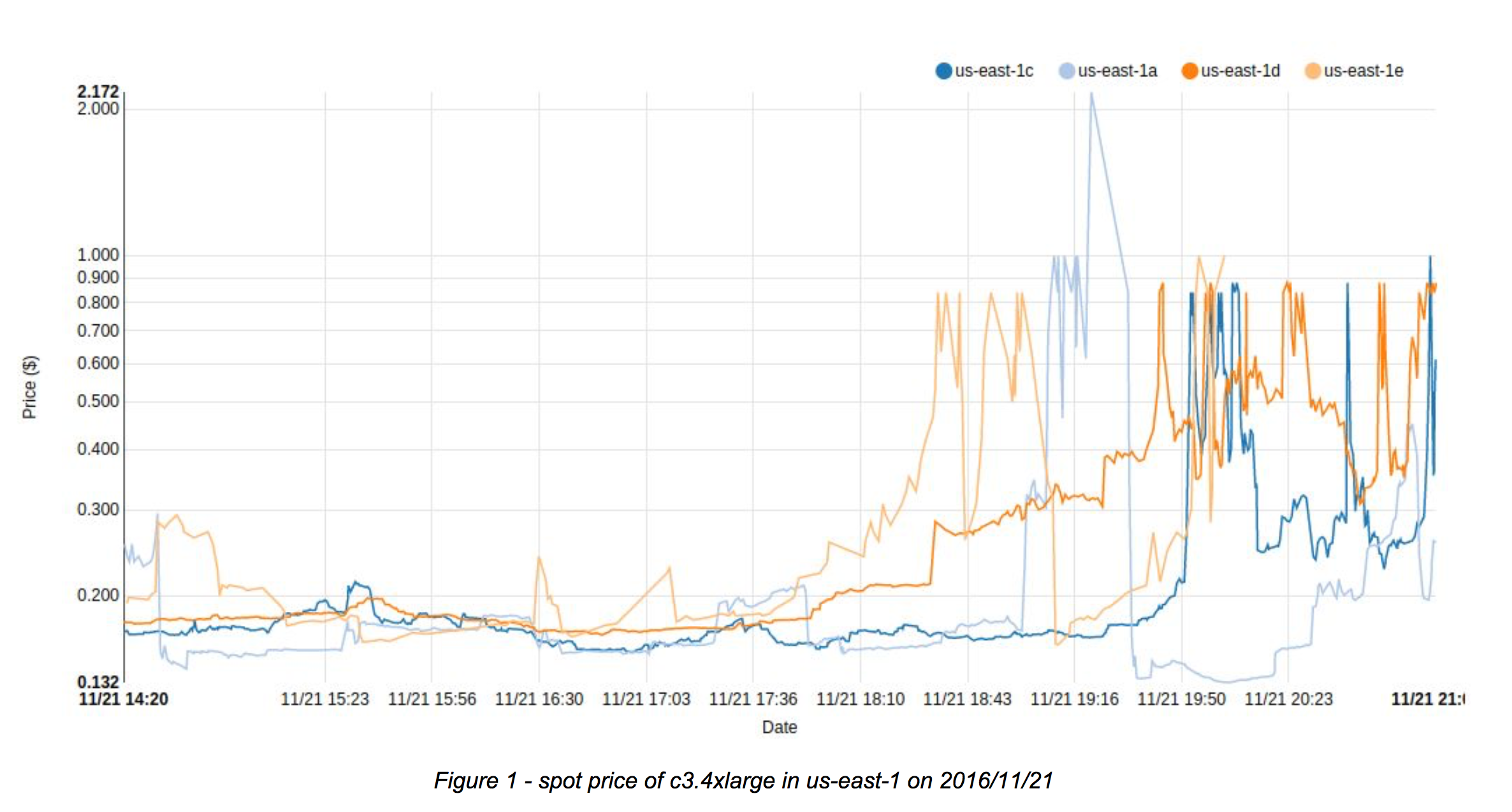
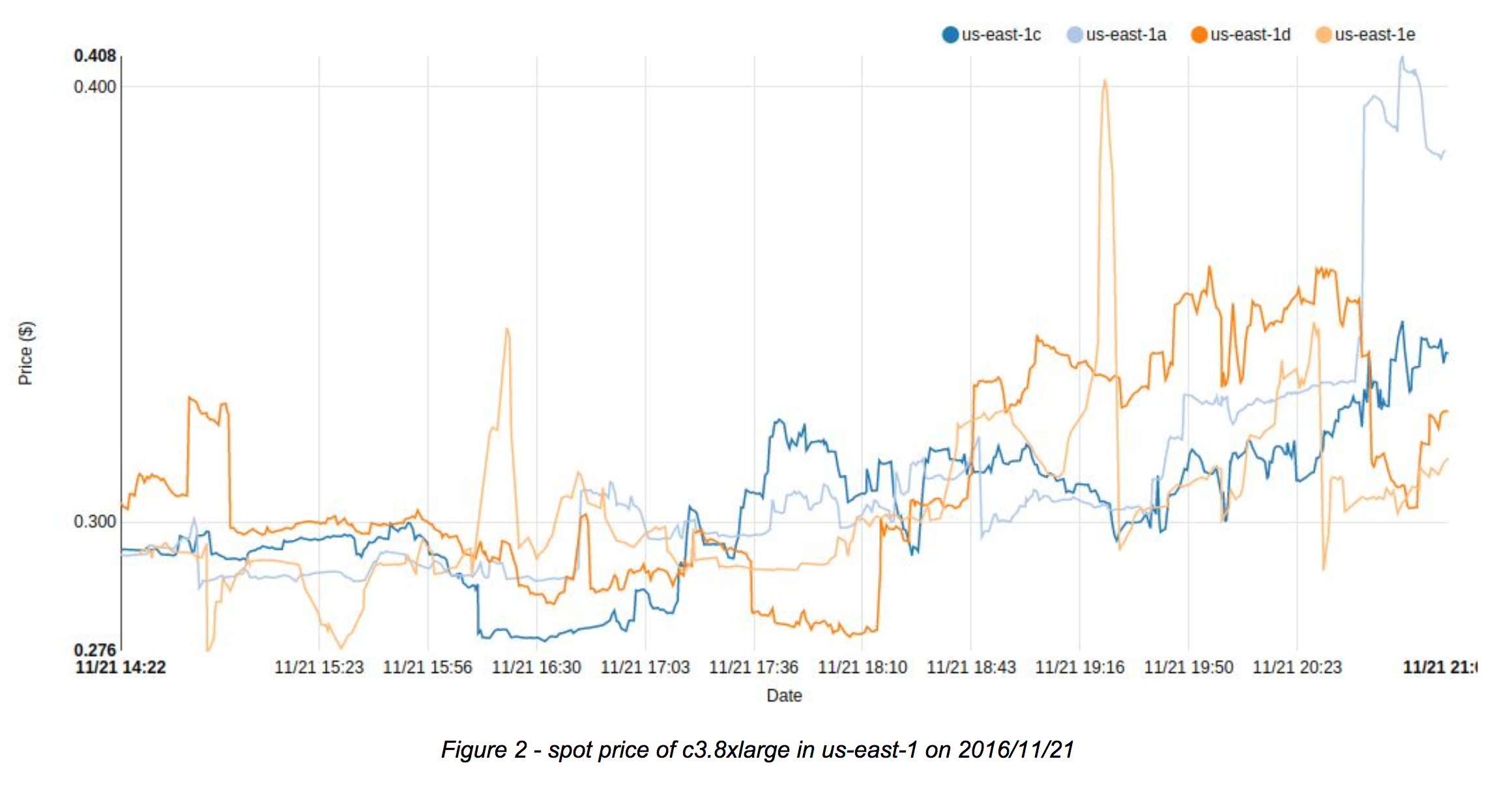
The spot price of c3.4xlarge – which is the smaller and cheaper instance type – has frequently exceeded the price of its larger, more expensive counterpart over the period of the day. The latter has been well under $0.400 for the most part (barring two short spikes), while the former has been above $0.400 almost throughout the latter half of the time period considered.
Spot Fleet functionality from AWS enables customers to specify different instance types that can be used to execute a workload and let AWS automatically provision the cheapest selection/combination of instances that satisfy the required capacity. In the above example, Spot Fleet could have automatically provisioned the cheaper instance type (c3.8xlarge) leading to significant cost savings.
Private Beta Test Environment
One of our customers, whose workload is very elastic and cost-sensitive, agreed to beta test Heterogeneous clusters on QDS. We’ll focus on two clusters that had the most usage.
Cluster-A
- The primary instance type is m4.4xlarge
- Additional instance types are m4.2xlarge with a weight of 0.5 and m4.xlarge with a weight of 0.25
- Scales between 5 and 90 normalized instances. All auto-scaled instances are Spot instances
- The cluster is used for Hadoop/Hive
Cluster-B
- The primary instance type is r3.4xlarge
- Additional instance types are r3.2xlarge with a weight of 0.5 and r3.xlarge with a weight of 0.25
- Scales between 6 and 30 normalized instances. All auto-scaled instances are Spot instances
- The cluster is used for running Spark
We’ll compare the costs from the actual usage seen (via heterogeneous clusters) vs. what we would’ve seen if we were using a homogeneous cluster composed only of the primary instance types. We can do this because EC2 provides an API to obtain the comprehensive price history for all Spot instances.
Analysis
To show how we compute the cost savings – we will start with an example. On October 13th at 15:06 UTC – Cluster-A requested to scale up by 20 m4.4xlarge instances with a Spot price of $0.2233. Instead, QDS provisioned 40 m4.2xlarge instances with a Spot price of $0.088:
- 20 m4.4xlarge @ $0.2233 = $4.47 for the hour
- 40 m4.2xlarge @ $0.088 = $3.52 for the hour
So in this case the heterogeneous cluster was able to save 21% because it was able to select purchase option #2 – a choice that would not be available to a homogeneous cluster.
We applied this framework to all instances provisioned in these two clusters from 10/10 through 10/15. Our conclusions were as follows:
- Instances provisioned by Cluster-A cost a total of $2,131 during this time period. If only the primary instance type was used instead – Cluster-A would have cost $6,466 instead. Hence heterogeneous Spot clusters saved 63.7% over a homogeneous Spot cluster during this time period.
- We got similar results for Cluster-B. Instances provisioned by Cluster-B cost a total of $781. If only the primary instance type was used instead – an estimated $2,221 would’ve been spent instead. This equates to a savings of 66.5% for the heterogeneous configuration over the homogeneous one.
We also compared the costs to an On-Demand cluster. If, instead of using heterogeneous Spot clusters, we had used On-Demand instances of the primary instance type, what would the difference in pricing be? It turns out that heterogeneous clusters save an eye-popping 92% from On-demand pricing!
Note: For Cluster-A it was usually cheaper to substitute in m4.2xlarge instances in place of m4.4xlarge. Interestingly, later in the month, it was consistently cheaper to use m4.xlarge instances.
Conclusion
The public cloud marketplace is proliferating with instances of different types and purchasing options. Heterogeneous clusters allow us to take advantage of this diversity to run big-data clusters reliably and with high-cost savings and we are excited to offer our first take on it. This feature will be enabled for all accounts soon, but if you’d like to get early access, email us at [email protected].
For information on how to configure heterogeneous nodes via the QDS web interface, click here.



