One of the important functions of a database administrator is to manage storage structures to optimize performance in a relational database. Admins use tables, views, indexes, and cubes to tune the database as well as control the behavior of users (e.g., discourage full table scans and cross joins).
There are similar well-known techniques in the big data world. Two factors make it hard to use these techniques in the Hadoop ecosystem. First, none of the open-source analytic engines support these techniques natively. This means data engineers need to create these optimizations manually and then document, communicate, and train end-users on the data structures to use. This doesn’t scale well for large enterprises. Second, it is very common to use more than one technology or analytic engine to improve performance and accessibility. For example, base tables optimize for scale, so they are hosted in S3 and managed through Apache Hive, while materialized views are stored in a data warehouse like Redshift for fast access.
Quark solves both these problems and helps data engineers manage these storage structures in their big data ecosystem. Before we describe Quark further, let’s first walk through the internal data architecture at Qubole, and where Quark fits in.
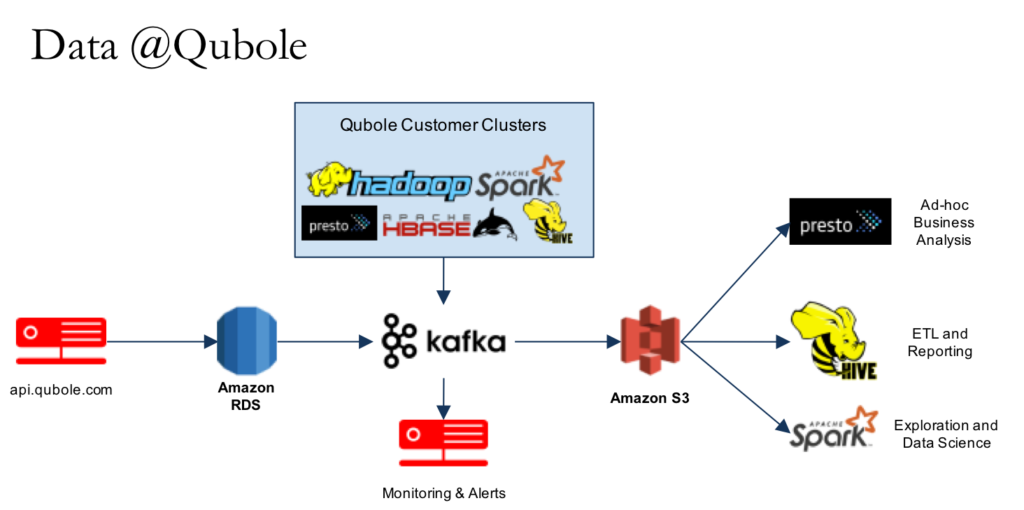
The diagram above shows a simplified version of the data infrastructure at Qubole. It is representative of the typical infrastructure we help to run for our customers. The data engineers generate derived datasets of the core transactional data for each type of analysis – ad hoc, reporting, and advanced data modeling. In Quark, they are registered as materialized views. Quark then automatically chooses the best dataset and SQL engine for the queries submitted by analysts. This significantly simplifies the model for our analysts and they don’t need to know the underlying data structures when writing SQL queries.
Quark
We have developed and released Quark as an open-source project. Quark enables the following use cases:
- Create & manage optimized copies of base tables:
- Narrow tables with important attributes only.
- Sorted tables to speed up filters, joins, and aggregation
- Denormalized tables wherein tables in a snowflake schema have been joined.
- OLAP Cubes: Quark supports OLAP cubes on partial data (last 3 months of sales reports for example). It also supports incremental refresh.
- Bring your own database: Quark enables you to choose the technology stack. For example, optimized copies or OLAP cubes can be stored in Redshift or HBase, or ElasticSearch, and base tables can be in S3 or HDFS and accessed through Hive. This is a powerful feature and data teams can choose the stack best suited to their architectural and cost constraints.
- Rewrite common bad queries: A common example is to miss specifying partition columns which leads to a full table scan. Quark can infer the predicates on partition columns if there are related columns or enforce a policy to limit the data scanned.
We designed Quark with some specific features in mind:
- Compatibility with BI tools: Quark supports ANSI SQL and provides a JDBC driver so that your analyst can use your favorite BI tool, such as Tableau.
- Complex Data Structures: like Maps and Arrays. Useful for mapping JSON.
- SQL Dialects: Quark has to work with multiple SQL engines. We have built the ability to morph the SQL query to match the SQL engine where the dataset is available.
In the future, we hope to build an ETL system that will use metadata in Quark to guide ETL processes.
Architecture
From a user’s perspective, Quark acts like a typical database. It consists of a server and a JDBC client. The JDBC client allows Quark to be used with any BI tool that can submit queries using the JDBC protocol.
Database Administrators
Database administrators are expected to register data sources and define views and cubes. Quark can pull metadata from a multitude of data sources through an extensible Plugin interface. Once the data sources are registered, the tables are referred to as data_source.schema_name.table_name. Quark adds an extra namespace to avoid conflicts. DBAs can define or alter materialized views with DDL statements such as:
create view page_views_partition as
select * from hive.default.page_views
where timestamp between “Mar 1 2016” and “Mar 7 2016”
and group in (“en”, “fr”, “de”)
stored in data_warehouse.public.pview_partition
Quark stores its catalog in a database such as MySQL, Postgres, or SQLite.
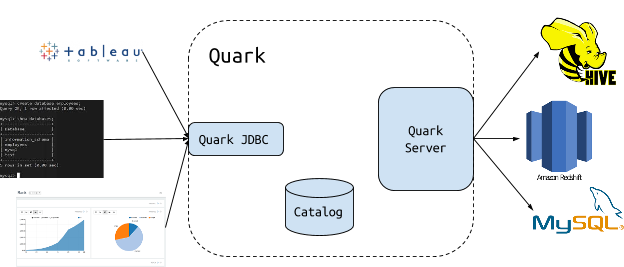
Analysts
Analysts will submit SQL queries to Quark through a command-line utility or BI tools like Tableau or notebook interfaces like Apache Zeppelin. The SQL queries should refer to a canonical set of tables. Typically these are tables defined in the Apache Hive metastore.
Internals
Quark’s capabilities are similar to a database optimizer. Internally it uses Apache Calcite which is a cost-based optimizer. It uses Avatica a sub-project of Apache Calcite to implement the JDBC client and server.
Quark parses optimizes, and routes the query to the most optimal dataset. For example, if the last months of data in hive.default.page_views are in a data warehouse, Quark will execute queries in the data warehouse instead of the table in Apache Hive.
Community
Quark has already proved useful for internal use cases at Qubole as well as at a few of Qubole’s customers. However, there is much more work to be done, and we’d love for you to get involved. Quark is fully open-source software, licensed under the Apache Software License 2.0.
Resources for getting involved:
- Source Code: https://github.com/qubole/quark/
- Mailing List: [email protected]
- Gitter: https://gitter.im/qubole/quark
Summary
Quark is a system that can manage the metadata of datasets for ETL engineers. It also helps analysts to use the right dataset for their reports. Quark supports JDBC. It is designed to work well with current investments made by the data team both for data storage systems and reporting tools. We welcome feedback and suggestions and also for developers to get involved in the open-source project.



