Public cloud platforms like AWS, Azure, and GCP provide more than 100 types of instances each with different characteristics in memory, CPU, and storage optimizations, as well as specialized hardware like GPUs. The Qubole team commonly gets asked what is the best instance family and type for customers’ ad hoc use cases on Presto versus other workloads (such as data prep). Interestingly, the instance-type most frequently chosen by our users is the R-family in AWS, which is memory-optimized. However, as we researched, we found that this is not necessarily the most performant and efficient.
In this blog, we will study the performance of Presto for ad hoc workloads on AWS with various instance types using TPC-DS as the representative workload. We will show that:
- On AWS, C-family is the most performant.
- C-family is sufficient for memory requirements of TPC-DS as well as many customer workloads.
Survey and Comparison of Instance Types in AWS
At the time of publishing, we counted 122 distinctly named types in AWS. Since a comprehensive benchmark across all types is infeasible, we culled the lists using the following rules:
- An instance type should have at least 60GB of RAM and 8 cores.
- An instance should not have specialized hardware like GPU.
The two rules reduced the number of candidates to 53 on AWS.
Instance types are characterized by the unit economics of memory and CPU. For example, R-family* in AWS is memory-optimized because the GB per cost per hour is higher than other instance types. The chart below visualizes the unit economics for the reduced list.
*Note: We have grouped by the family since the unit economics is the same within a family (r4.2xlarge, r4.4xlarge …)
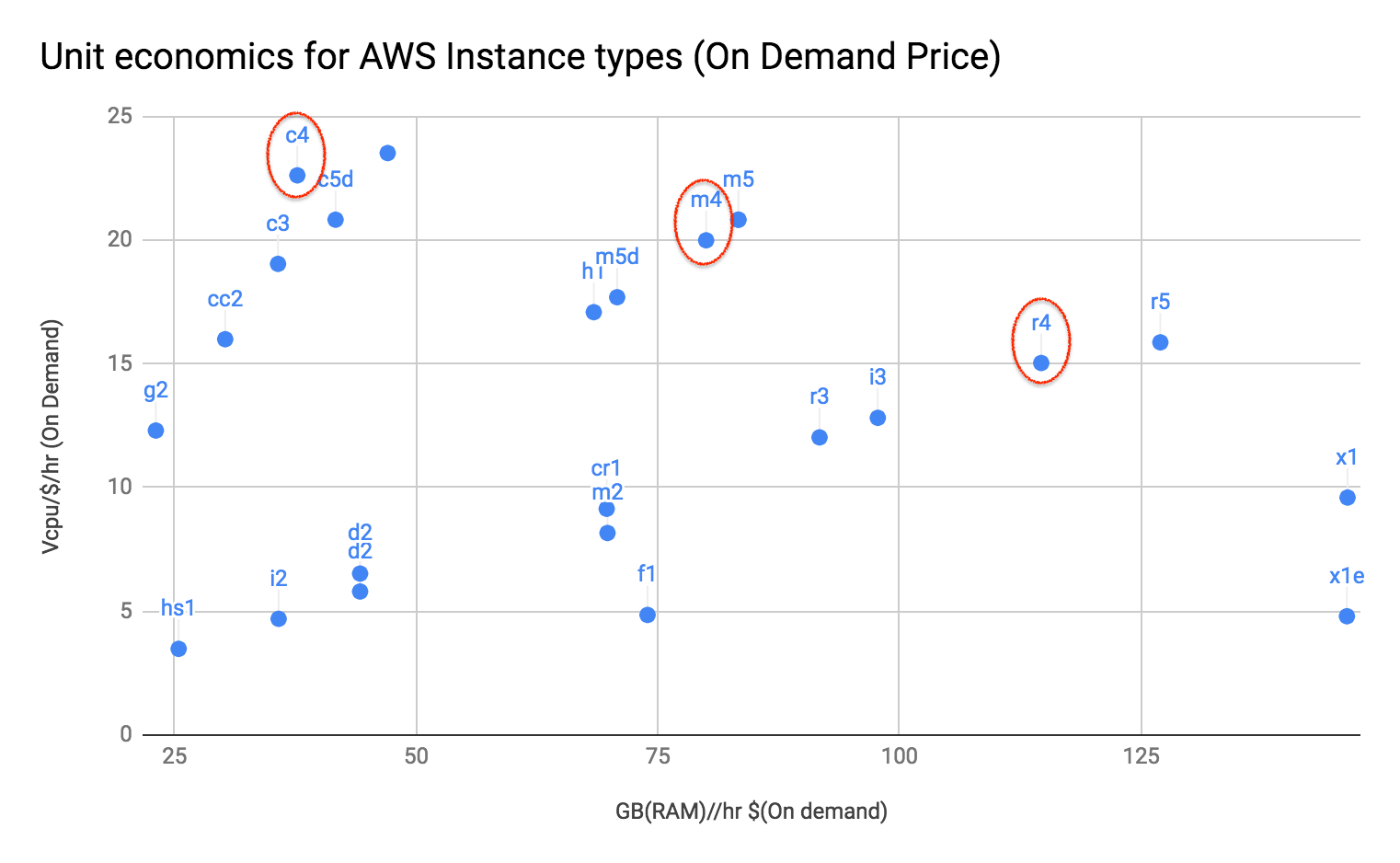
We chose to start the comparison using the following families, as they are representative of different parts of the graph and are popular as well.
- R4
- C4
- M4
Memory Requirements for TPC-DS Queries
A common refrain to use memory-optimized instance types is that queries in Presto require a large amount of memory. We studied the memory requirements of TPC-DS queries with and without Join Ordering. The histogram below shows the memory requirements for the full set of TPC-DS Scale 1000 queries in Presto 0.193.
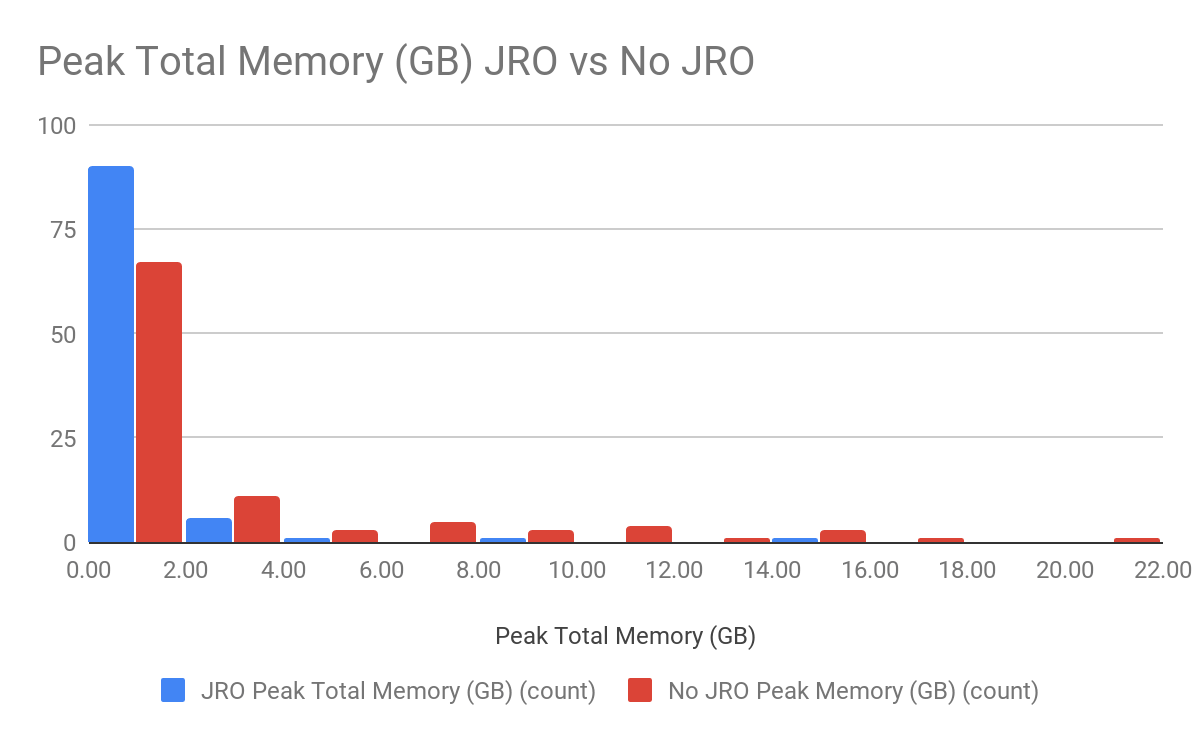
A small set of queries requires large amounts of memory without Join Reordering. With Join Reordering, this is all the more true, with 86 of 99 queries requiring less than 2GB of memory.
The histogram shows that it is possible to choose an instance type from any of the families to run most of the queries.
We also studied two million user queries from production workloads on Qubole Presto in the Qubole Platform. Peak distributed memory usage (GB) is plotted below.
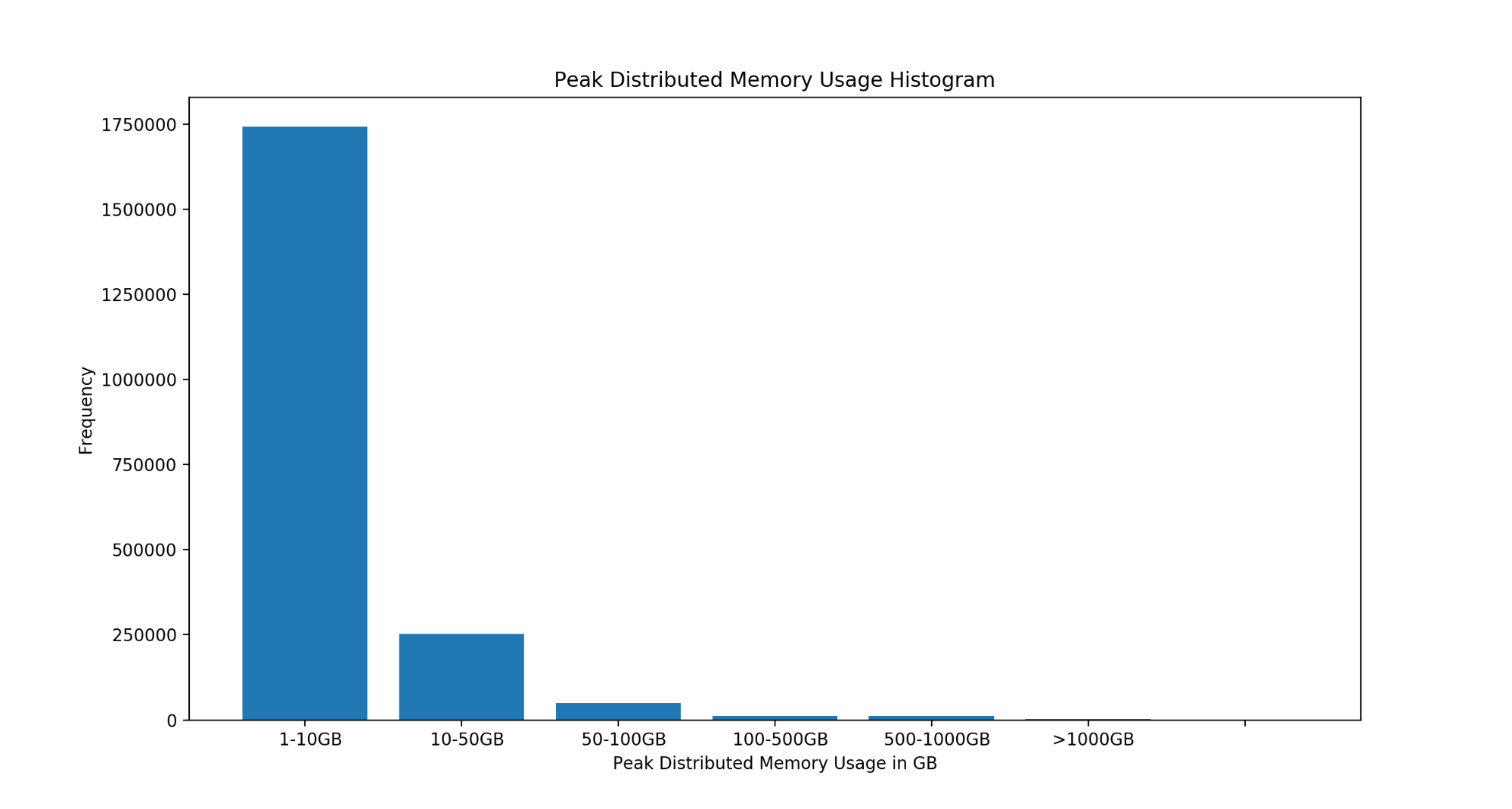
The percentile table is shown below:
| Percentile | Peak Memory Distribution (MB) |
| 50 | 45.0 |
| 75 | 445.0 |
| 90 | 1689.0 |
| 95 | 6103.0 |
| 99 | 75093.62 |
| 99.9 | 877073.45 |
The above table shows that peak memory utilization of user queries aggregated over all nodes of a cluster has a 90th percentile value of only 1.6GB and a 95th percentile value of the only 6GB. Therefore large memory instances are not required for the majority of user queries.
Main Memory also influences the concurrency that can be supported in a cluster. We will study the effect on concurrency in a future benchmark and blog.
Cluster Configurations
In this section, we will describe the methodology to choose an equivalent cluster configuration across different families. Clusters should be standardized in one of the following factors:
- Cumulative Memory of the cluster
- Cumulative number of cores of the cluster
- Cumulative cost per hour of the cluster
We chose to use the cumulative cost per hour of the cluster to choose cluster configurations across different instance types.
On AWS, we used r4.2xlarge * 16 as the base cluster configuration. We chose r4.2xlarge as it is the smallest instance type in the R4 family. Performance scales linearly with larger instance types in the R4 family. We chose 16 machines in the cluster as that is the size required to run all TPC-DS queries with Join Reordering disabled.
Based on the cost of the configuration, we derived the following configuration for M4 and C4 families:
- M4.4xlarge * 11
- C4.8xlarge * 6
Performance Benchmark
Our setup for running the TPC-DS benchmark was as follows:
TPC-DS Scale: 1000
Format: ORC (Non-Partitioned)
Scheme: S3
We ran the benchmark queries on Qubole Presto 0.193, using TPC-DS queries published in this benchmark:
- Default Presto configuration was used along with Join Reordering and Dynamic Filters.
- No proprietary Qubole features like Qubole Rubix, autoscaling, or spot node support were used.
- Timings published use best of 3 runs.
Performance Evaluation of C4, M4 & R4
| C4 | M4 | R4 | |
| GeoMean (s) | 24.40568961 | 39.6073530 | 39.6402773 |
| Cost ($) | 21.87342166 | 37.58067775 | 28.8004084 |
| # of failures | 5 | 3 | 3 |
| # of failures w.r.t to r4 | 2 | 0 | 0 |
| # of queries slower w.r.t to r4 | 1 | 33 | 0 |
Cost is calculated as the sum of the cost of the best run for every query.
The table shows that C4.8xlarge has the lowest Geomean and the lowest cost to run all TPC-DS queries by a fair margin. Moreover, there were only two failures on C4.8xlarge compared to R4.2xlarge due to a lack of memory.
Since C4.8xlarge provides substantially better performance and the number of failures is not high, it is a viable option for the majority of TPC-DS queries.
Conclusion
We studied the performance of TPC-DS queries with various instance types on Presto 0.193. We found that C-family provides the best performance compared to R-family. Cumulative memory also affects the concurrency of the cluster. We will study the relationship between concurrency and main memory in another blog post.
We urge Presto users on the cloud to study their workloads to check if C-family instance types are more appropriate for your workloads. Performance along with an autoscaling policy that fits workloads throughout the day are important factors to choose the right instance type. Qubole can help provide insights into your workloads via AIR and event listeners.
Try Presto in AWS Today
The analysis for this blog was created using Qubole’s cloud-native big data platform and autoscaling Presto clusters. Qubole offers you the choice of cloud, big data engines, tools, and technologies to activate your big data in the cloud. Sign up for a free Qubole account now to get started.



