Node Startup Process in Qubole Data Service (QDS)
In QDS, when a cluster is started, a “node startup process” runs on each provisioned node and issues a bunch of setup commands. Specifically, it does the following for Presto:
- Picks the right version of Presto as configured by the user. Different versions are present within the machine image for faster boot-up times.
- Sets up Presto configurations according to the overrides provided by users.
- Starts the Presto Server.
Need for Customizations in Node Startup
The above-mentioned node startup process is a fixed set of procedures that remains the same across different types of clusters, but certain situations require customizations to Presto startup. These include:
- Releasing Cluster-Specific Critical Fixes
Different users have different uses for Presto, and sometimes they face issues applicable to only their use case. These issues need to be fixed as soon as possible to avoid project delays. In such cases, instead of waiting for the full release of QDS, it should be possible to release fixes to the affected users quickly. But since the Presto package is fixed in the machine image, we need a way to bring in the Presto package containing fixes from outside the machine image. - User-Defined Functions (UDF)
Presto does not support the add jar kind of functionality like Hive does to add UDFs during runtime. Rather, UDF jars have to be installed before the Presto server startup. Thus, to allow custom UDFs, we need a way to bring these UDF jars from the user location into the Presto installation location in the nodes. The same applies to other developer customizations in Presto like custom access controls, custom query event listeners, etc. - Advanced Presto Configurations
Some users have an advanced configuration that requires custom handling logic, such as enabling HTTPS only on the master with a custom certificate. This requires finding out whether the node on which we are trying to apply the configuration is a master or a worker. Such cases need to be handled outside the standard node startup procedure.
Node Bootstrap: Deprecated Way of Customizing Presto Start
For scenarios like those mentioned above, the node bootstrap feature has been in use for a long time. Users provide a shell script in the node bootstrap that runs in parallel to the node startup process to execute the desired steps of configuring Presto or downloading and placing jars into the Presto installation.
A typical node bootstrap for providing fixes looks like this:
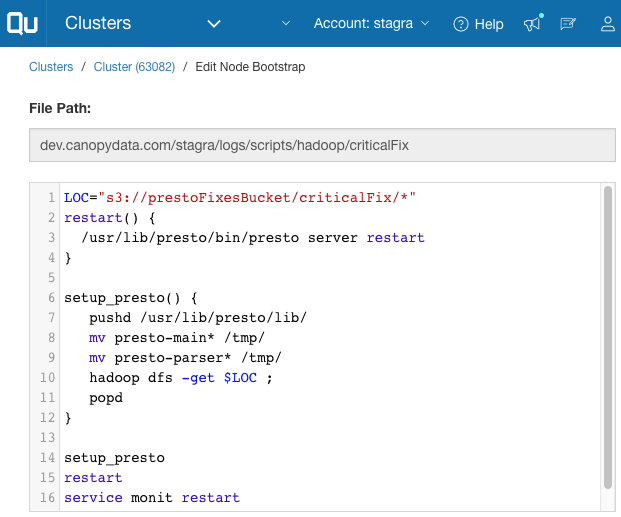
This bootstrap script downloads presto-main and presto-parser jars from s3://prestoFixesBucket/criticalFix/ location, replace the existing presto-main, and presto-parser jars with these jars, and restarts the Presto server.
This works fine in a majority of cases, but once in a while query failures occur because the bootstrap script restarts the Presto server in the node. This causes issues when the Presto server has already been started by the node startup process and has accepted some work for a query from the Presto Master, but the node bootstrap has restarted the Presto server after that. A Presto restart cannot be avoided, as only after a restart can the changes introduced by the bootstrap script be picked up.
Presto Server Bootstrap
To solve these issues while setting up Presto through node bootstrap, Presto on Qubole has introduced a new way to bootstrap Presto called Presto Server Bootstrap. This mechanism is native to the Presto startup process in QDS and is also configured via Presto overrides, providing a single place for users to configure Presto. It can be configured via the “Override Presto Configuration” section on the Edit cluster page.
For example, the above-mentioned node bootstrap can be converted to a Presto Server Bootstrap as follows:
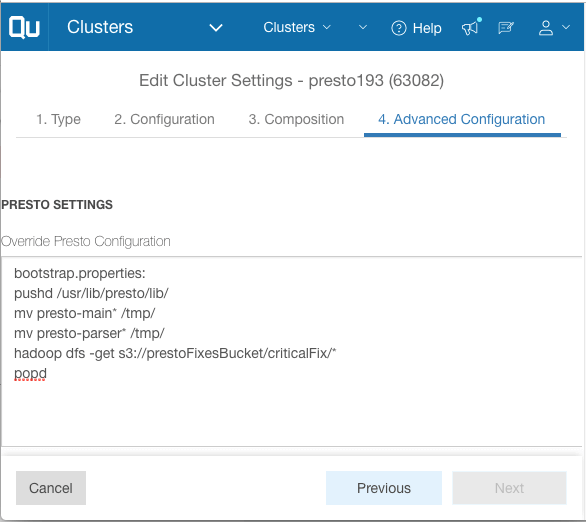
Two new section titles are introduced in Presto settings:
- bootstrap.properties
The contents of this section are executed as a script during the process of Presto bring-up in the node startup process. - Bootstrap-file-path
In this section, a location of the script in the cloud store can be provided instead of providing the contents. This is useful if you want to share the same Presto server bootstrap across multiple clusters or want to reuse an existing node bootstrap script (existing node bootstrap scripts should be slightly modified to remove Presto server start/restart commands).
The Presto server bootstrap guarantees that:
- All bootstrap steps are executed before starting the Presto server to avoid any issues around race conditions that the node bootstrap faced.
- Any failure in the execution of the bootstrap steps stops the node startup process from bringing up the Presto server. A failure triggers a bad-node listener for this node in the Presto master, which in turn removes this node and provisions a new one. This is useful in case the bootstrap faces transient issues, but if the bootstrap script has user errors then this will prevent the cluster from starting up altogether, thereby ensuring that the cluster starts only in the intended state.
Presto Server Bootstrap vs. Node Bootstrap
Any custom action that affects the Presto server needs to be taken before the server starts, and therefore should be performed using the Presto server bootstrap. This covers the above-mentioned cases of:
- Setting up Presto jar for fixes and features
- Adding UDF jars, event listener jars, access control jars, or any other Presto customization
- Any configurations that cannot be done in “Presto Configuration”
Anything that is outside of Presto must go into the “node bootstrap”, such as:
- Adding monitoring steps like additional datadog agent yaml configurations
- Doing administrative operations like adding cron jobs or setting networking rules like port forwarding
We have moved the majority of our customer base to Presto server bootstrap, but if you are still using node bootstrap for Presto and need help converting it, please reach out to [email protected].



