Introduction
Qubole provides powerful automation that optimizes underlying cloud compute management for data lakes. Qubole cluster management continuously optimizes both performance and cost by lowering unnecessary consumption of compute nodes as well as provisioning low-cost compute nodes. Following is Qubole’s extensive feature portfolio which works both for performance and cost

In the portfolio above, we are introducing “Optimized Upscaling.” Optimized Upscaling reclaims unused resources from the running containers in the cluster and allocates them to the pending containers. This improves the cluster throughput and reduces the delays due to provisioning machines while lowering the TCO and cost avoidance.
Problem Statement:
More Resources = More Throughput
But Higher TCO
Increased adoption of analytics and AI/ML platforms in organizations has created more workloads from the end-users that require a higher throughput from the underlying clusters. But higher throughput achieved by provisioning more VMs results in higher TCO. If the organization wants to lower TCO, they allocate fewer machines, which results in lower throughput.
Less Resources = Lower TCO
But Lower Throughput
When an organization’s data transformation goes through an expansion phase, it controls cost by reducing the number of resources (machines) being provisioned to process workloads or monitoring it very closely. However, the workloads submitted to a cluster are diverse and heterogeneous. It is an inefficient way to lower TCO as it lowers the throughput significantly and results in the following:
- Missed SLAs: Resource starvation leads to longer execution times and missed SLAs, resulting in a negative revenue impact.
- Loss of Productivity: An increased backlog of jobs waiting to be scheduled for execution results in a longer wait time for the end-users submitting those queries.
Optimized Upscaling: Resolving the Paradox
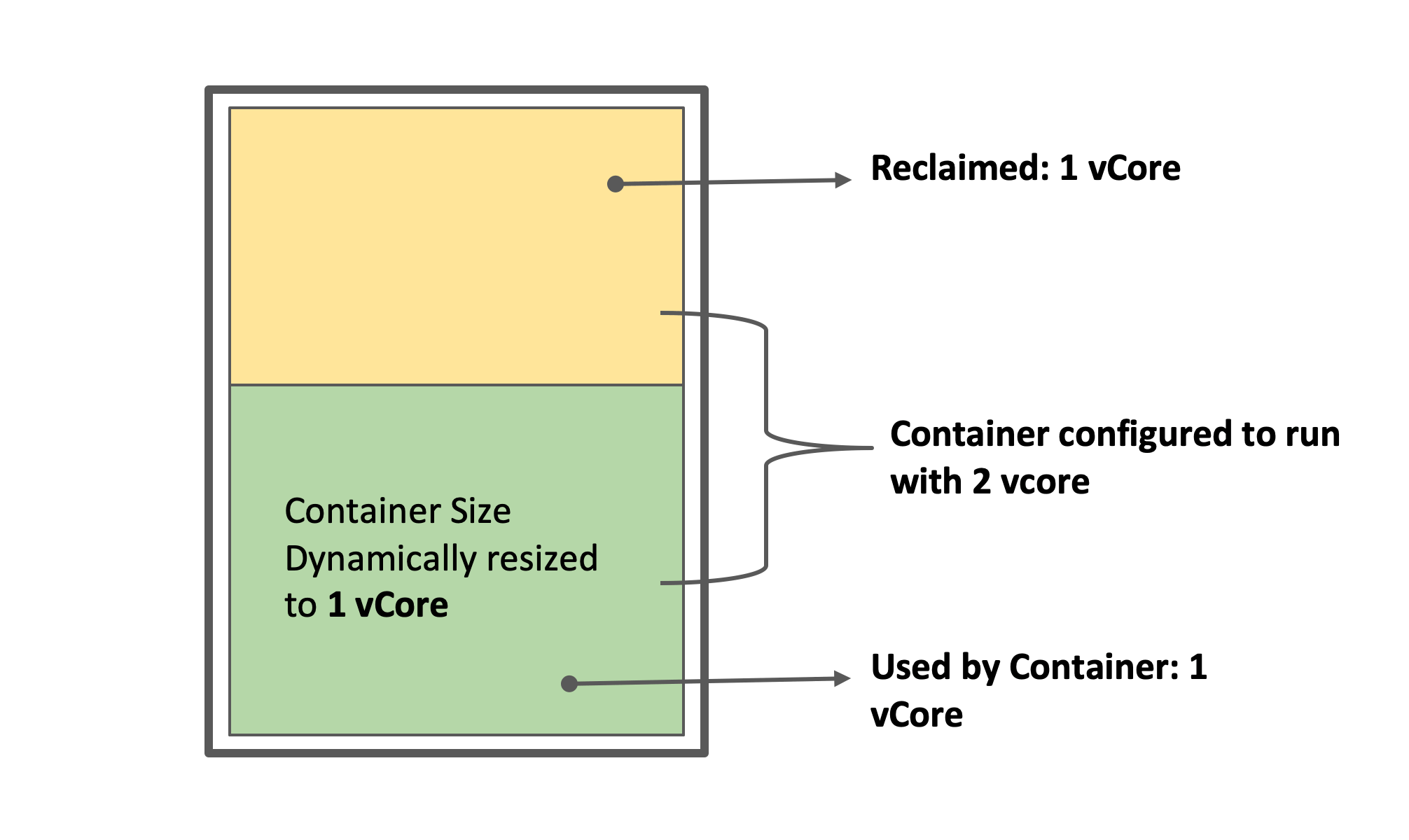
The resources offered by a Virtual Machine (VM) are broken into several logical units called containers. Container size (vcore, memory) can be configured both at the
- Cluster level (a static and homogeneous configuration applicable to all jobs submitted to the cluster) or
- Application level (a static value, which overrides the value configured at the cluster level).
These statically configured container sizes, in most cases, result in over-commitment and under-utilization of the resources at the machine level.
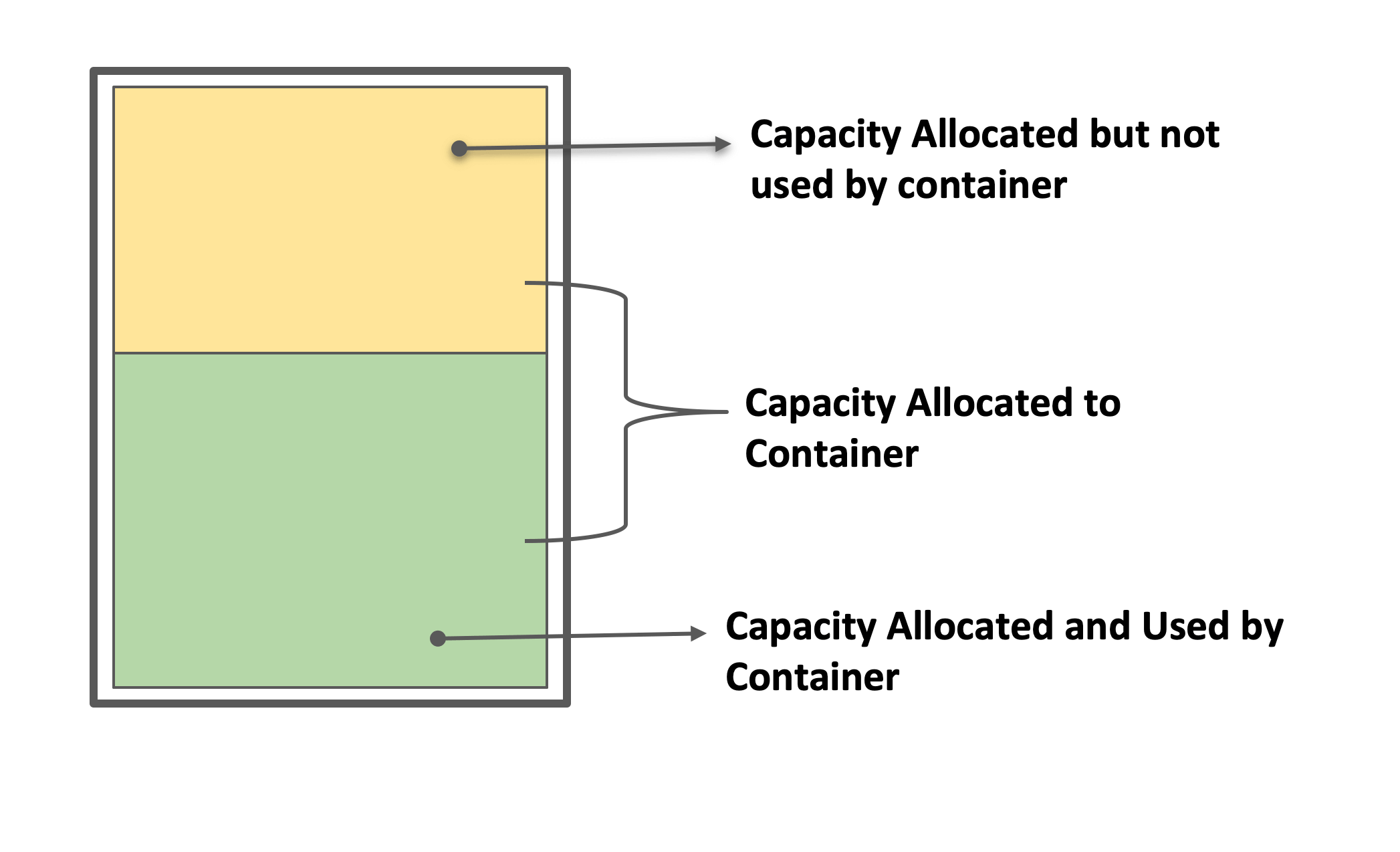
By automatically monitoring the real-time resource usage, Optimized Upscaling identifies containers that are over-committed and underutilizing resources. These resources are then reclaimed from those running containers, and made available for containers that are in the pending state. This results in several benefits such as higher throughput while keeping faster execution of workloads, a shorter wait time to get results, cost avoidance, and administrative productivity gains.
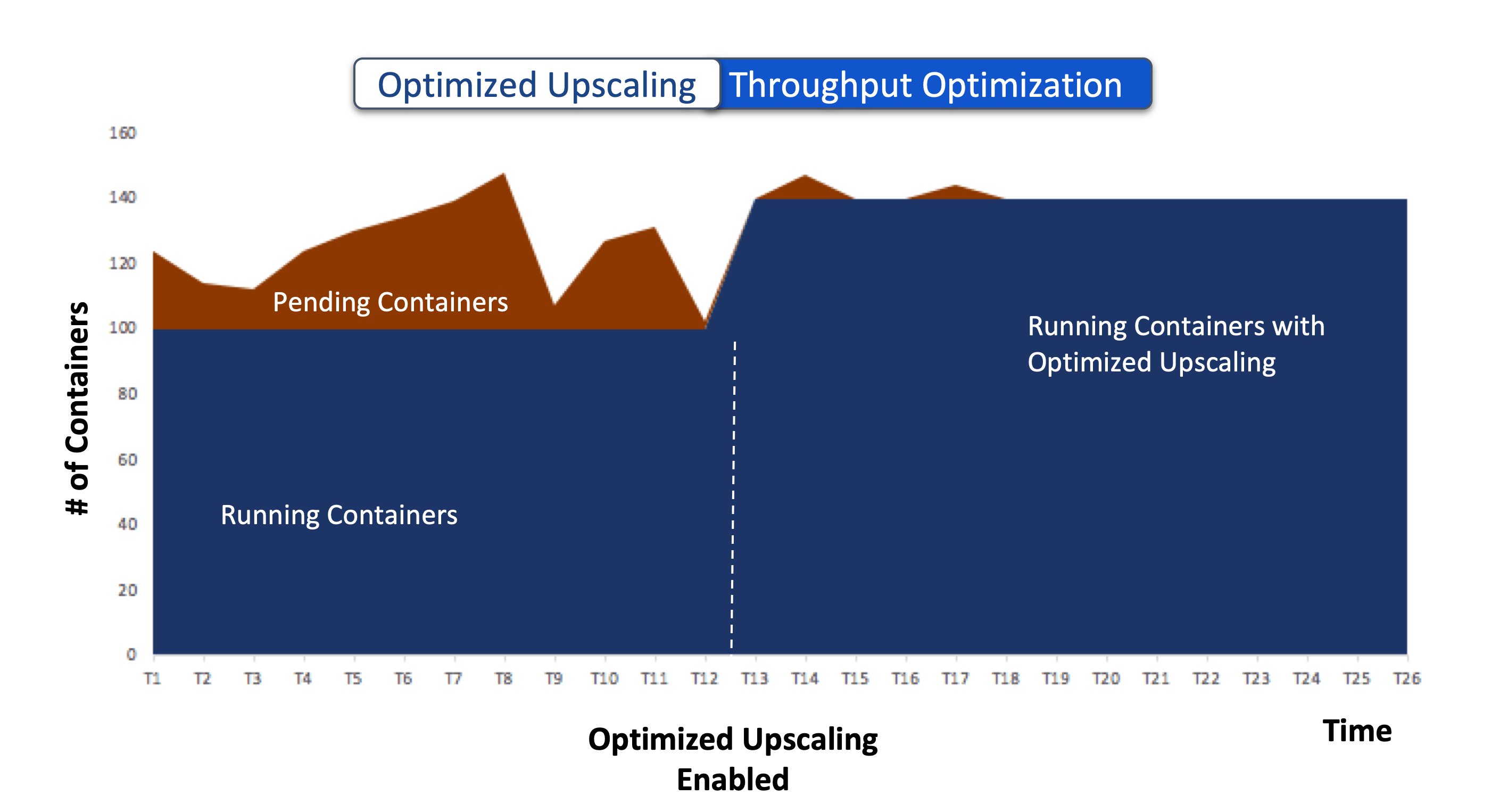
Higher Throughput:
Reclaiming the resources from existing containers results in the instantaneous availability of additional resources. When these resources are allocated to containers in the pending state, these containers are moved into the running state. Subsequently, the request for additional machines is also automatically adjusted (to account for the reclaimed resources) resulting in lower nodes being upscaled. With this more containers are concurrently executed with the same number of nodes in the cluster, resulting in a higher cluster throughput.
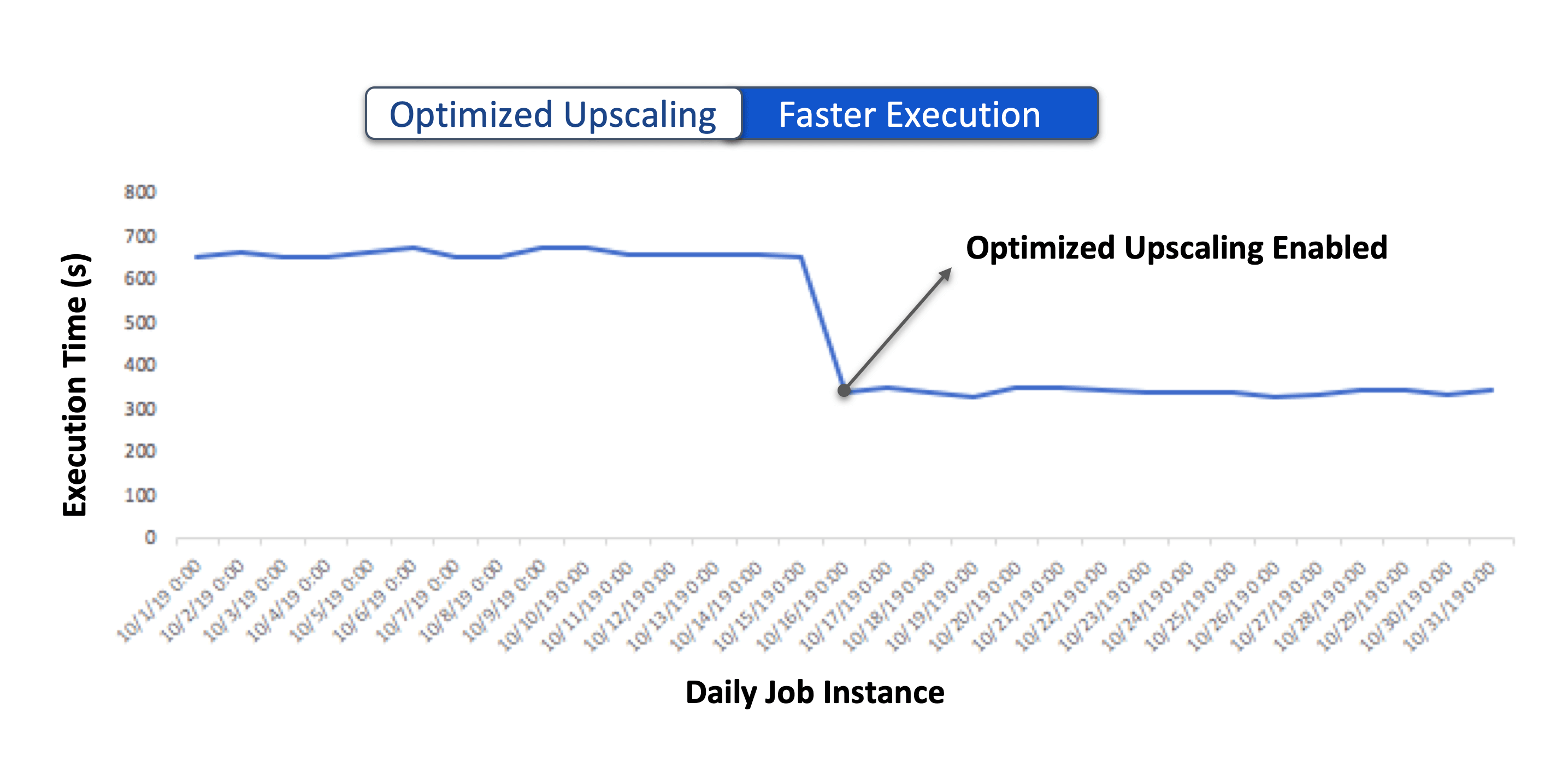
Faster Execution
A backlog of pending containers, bottlenecked by the throughput of the cluster, might lead to unwanted consequences such as:
- Missed SLAs
- Longer execution duration exposes the jobs to potential failures due to impending spot loss.
- Higher Cost since the cluster nodes are in running state for a longer duration due to longer execution time.
With higher throughput, pending containers from existing applications can be allocated sooner, resulting in lower job execution time. While the minimum job duration is still determined by various other factors (SparkLens for Spark applications), Optimized Upscaling ensures that the execution is not delayed due to pending containers.
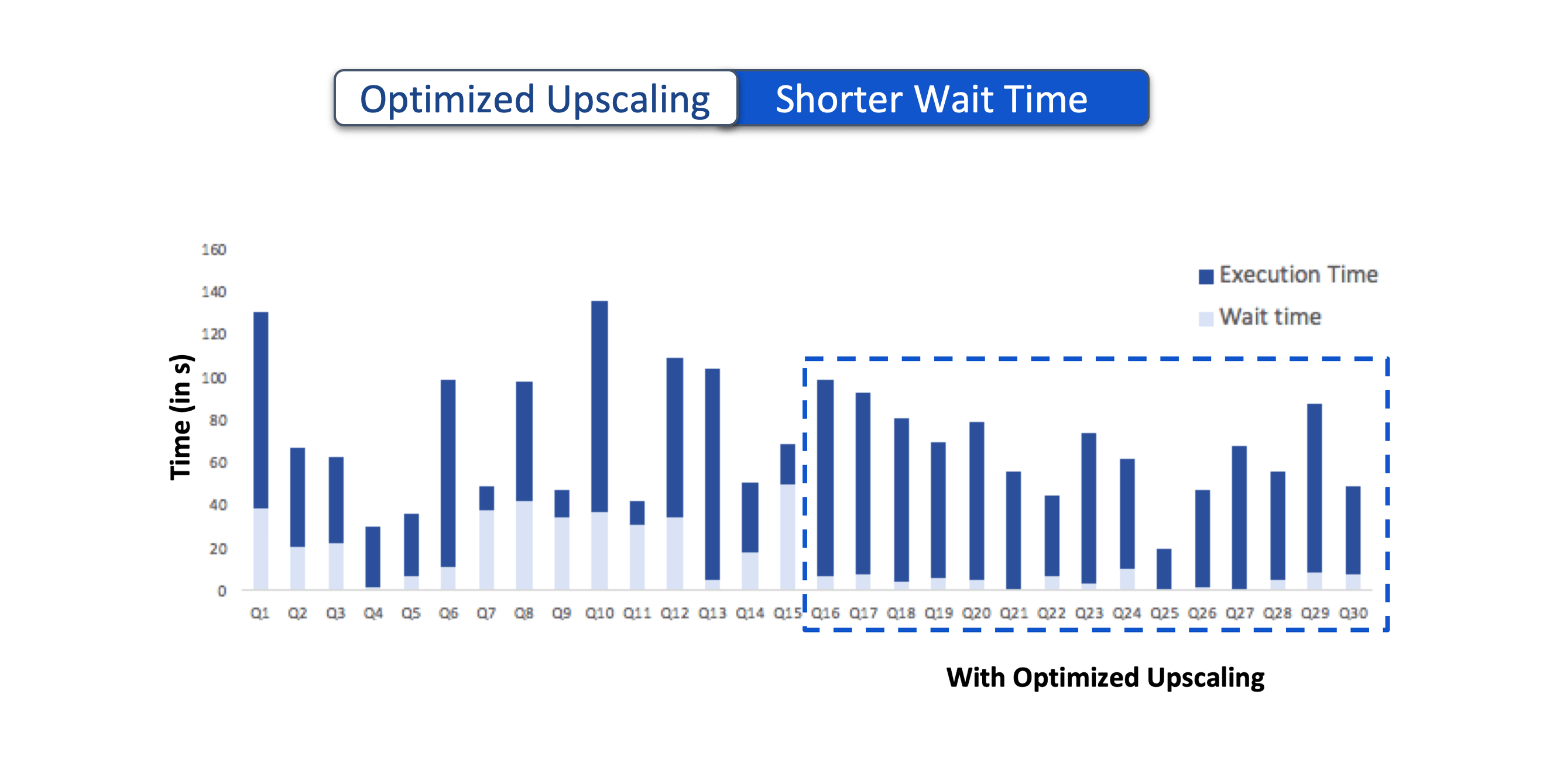
Shorter Wait Time
Newly submitted applications are bound by the available capacity to allocate:
- Application Master Containers
- Task Containers.
If Capacity Reservation for AM on On-Demand nodes is enabled, the AM containers are immediately scheduled in these nodes. However, the job execution will not begin until there are available resources to schedule the task containers. With Optimized Upscaling, unused resources from other containers are reclaimed and allocated to the task containers from these newly submitted applications thereby moving them to the execution stage. This helps in reducing the overall wait time for new applications.
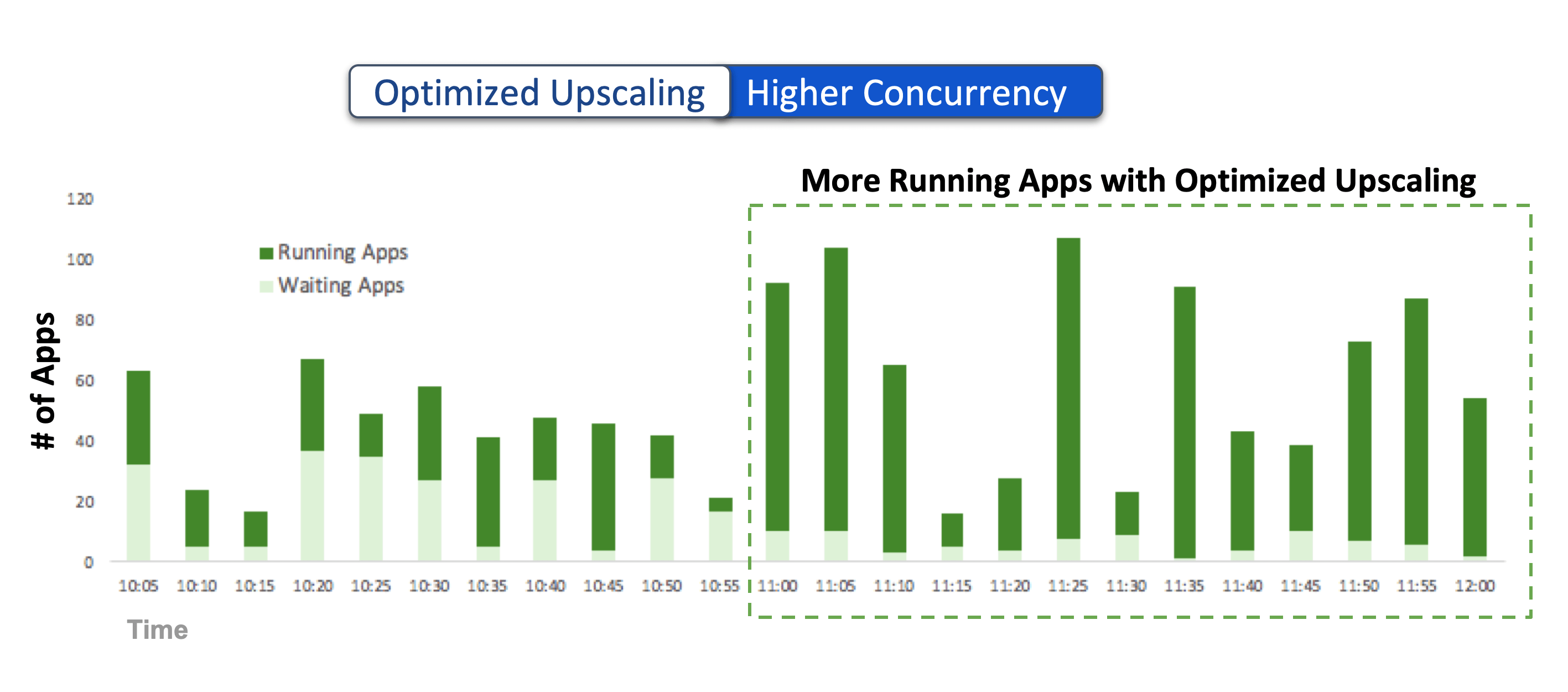
Support Concurrent Workloads at Scale
With increased throughput, the cluster’s ability to allocate task containers from new applications also increases. When existing applications complete sooner, the resources allocated to their containers are also released sooner (including the AM containers), resulting in the cluster’s ability to execute more concurrent applications.
Cost Avoidance
Unlike plain-vanilla autoscaling, Qubole takes workload demands into context while scaling up and down. Without requiring complex rules and policies, when workload requires more resources, Qubole can dynamically increase and shrink the size of the cluster between the configured min and max number of nodes. This automatically results in cost avoidance, known as Workload Aware Auto Scaling (WaaS) savings.
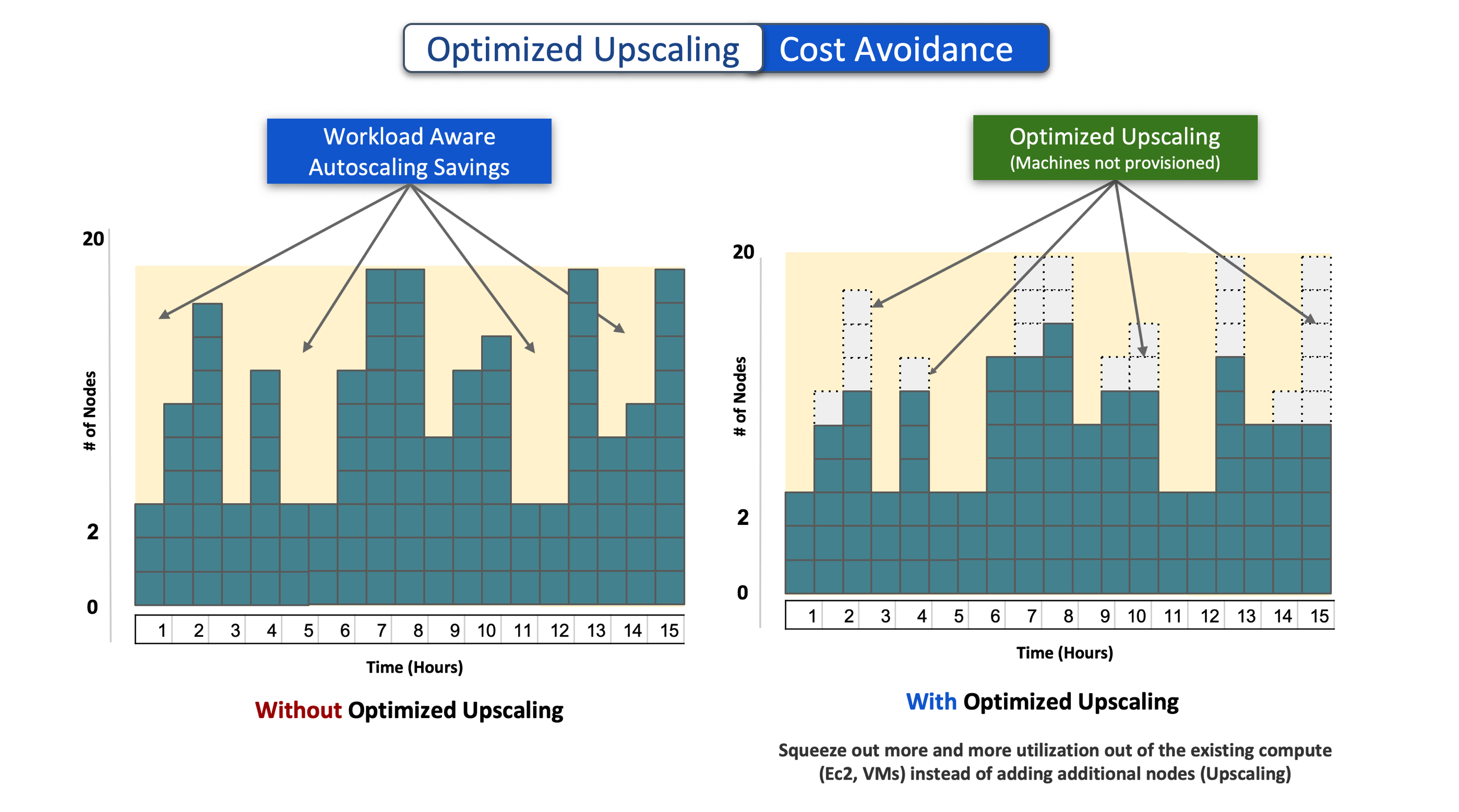
With Optimized Upscaling, Qubole provisions the required resources by reclaiming them from containers that are underutilizing the allocated resources. Subsequently, the number of nodes requested by Qubole auto-scaling is lowered to adjust for the resources reclaimed by Optimized Upscaling. This results in additional cost avoidance.
Increased User Productivity
End-user such as Data scientists or analysts waiting for the interactive job completion get faster response time. By lowering the job wait time and overall execution time, Optimized Upscaling helps reduce the end-user wait time, resulting in improved efficiency.
The administrator can maximize the ROI of their machines by ensuring that the cluster utilization is high.
Optimized Upscaling provides both end-user and administrative productivity with dynamic container sizing. Qubole dynamically resizes the running containers by observing the real-time resource usage of the containers. The unused resources from running containers are reallocated to pending containers without changing the configurations and reallocating resources to the container.
With Optimized Upscaling, data scientists, data engineers, and analysts can now get faster workload response time, and eliminate job backlogs while not worrying about TCO.
To learn more about Optimized Upscaling, contact us through your Qubole account team or request in the Weekly Demo. As Optimized Upscaling is in preview mode we would like to get your feedback via the “Send Feedback” button on the top right of the Qubole user interface.



