Introduction
Qubole Data Service (QDS) allows users to configure logical Hadoop and Spark clusters that are instantiated when required. These clusters auto-scale according to the workload and shut down automatically when there is a period of inactivity, resulting in substantial cost savings.
This feature, however, presents an additional challenge for supporting and debugging logs. For example, a scheduled nightly job might fail and the user would then want to investigate it the next morning, therefore needing access to the logs. In an on-premise, always-on setup, the MR Job History Server or the Spark History Server would’ve provided access to the logs and history. With auto-scaling, however, the processing cluster might’ve auto-terminated due to inactivity.
To solve this problem, we set out to build a service that would provide access to logs and history for jobs that ran on scaled-down clusters. We wanted to let users access jobs on running and scaled-down clusters transparently through a common flow. This was fundamental in providing the illusion of an always-on persistent cluster (which in reality is a series of ephemeral ones). Qubole launches hundreds of thousands of cluster nodes in a month – therefore, we needed the service to be secure, reliable, scalable, and multi-tenant. We have built the service for both Hadoop and Spark clusters. In this post, we will talk about how we built this service for Hadoop MRv2 clusters.
Architecture
The main components for building this functionality are the following:
- Persistence: The Job History, Configuration, and Container Log Files need to be persisted somewhere so that they are accessible even after a cluster is terminated.
- Qubole Job History Server: A persistent and multi-tenant Job History server is required to serve requests for logs and history belonging to jobs that ran on terminated clusters (by looking up the persisted files from Step 1).
- Qubole Cluster Proxy: Each running Hadoop cluster itself has a Job History server for GUI access to the jobs that it has run (this comes bundled with Hadoop of course). So a proxy layer is required to redirect requests to the correct server based on the specific job and cluster at hand – either the cluster JHS when it is available – or the Qubole JHS when it is not (for terminated clusters).
The architecture and data flow is depicted below:
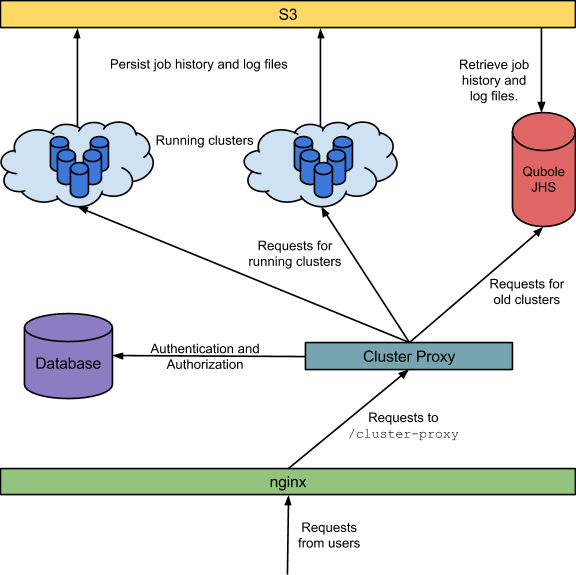
Persistence
By default, the MR Job History Server stores history and configuration files in HDFS. This is controlled by the property mapreduce.jobhistory.done-dir. Similarly, when log aggregation is enabled, YARN stores container logs in HDFS. This is controlled by the property yarn.nodemanager.remote-app-log-dir. Because we wanted these history, configuration, and log files to be available even after the cluster is shut down, we decided to store them in Amazon S3, a highly durable and scalable object-store. Then all we needed to do was set the above properties to users’ S3 location. However, to make this work, we had to implement NativeS3Fs (a NativeS3FileSystem clone) which uses the AbstractFileSystem APIs because YARN uses them instead of the FileSystem APIs used by NativeS3FileSystem.
Qubole Job History Server
This server would serve requests from different users having different S3 locations and credentials. So, we started with the standard Hadoop Job History server – but made it multi-tenant by extending it to accept different values for yarn.nodemanager.remote-app-log-dir, mapreduce.jobhistory.done-dir, and S3 credentials for different requests. The original Job History server daemon does a lot of things other than serving web requests, we turned off all the services and disabled all the web pages which didn’t make sense in a multi-tenant context. This server now runs as an internal service in QDS.
Qubole Cluster Proxy
Hadoop UI would normally generate URLs of the form: https://HOSTNAME:8088/proxy/APP_ID
We rewrite all these URLs to be of the form: https://api.qubole.com/cluster-proxy?encodedUrl=<encoded https://HOSTNAME:8088/proxy/APP_ID>
Nginx running on our web servers redirect requests to the /cluster-proxy endpoint to the Qubole Cluster Proxy service. The proxy does the following:
- Authentication is done based on cookies and verifying that the request is issued by a signed-in user.
- Authorization is done by matching the hostname information which came with the request against the node information stored in our databases (Qubole maintains a complete record of all the machines provisioned by us).
- Routing: our databases also record the state of the machines that we have provisioned as well as that of the cluster they belong to. If the hostname corresponds to a terminated cluster – the request is routed to the Qubole JHS – otherwise the Hadoop JHS on that specific cluster. In case the request is routed to QJHS – the proxy layer appends information about the S3 location and credentials required to retrieve the history and log files to the request.
Finally, a lot of work went in to make sure that all links contained in all these history pages keep on working. The links generated by the job history server are meant to work on a running cluster, so they are of the form https://HOSTNAME:19888/jobhistory/…
If we left them like this, then none of them would work because the server has gone away. They wouldn’t even work for running clusters because the cluster nodes are firewalled and only Qubole can access them. So, before sending the page generated by the job history server, the cluster-proxy parses the HTML and replaces the links to be of the form:
https://api.qubole.com/cluster-proxy?encodedUrl=<encoded
https://HOSTNAME:19888/jobhistory/…>
There are some other interesting problems which arise due to this replacement. We will discuss them in a later blog post.
This feature is available for our customers for both Hadoop and Spark clusters. No action is needed – it’s already enabled and running.
P.S. We are hiring and looking for great developers to help us build stuff like this and more. Drop us a line at [email protected].



