H2O’s Sparkling Water allows users to utilize H2O machine learning algorithms on Qubole Spark. With Sparkling Water, users can drive computation from Scala/R/Python and utilize H2O Flow UI, providing an excellent machine learning platform for application developers.
This article describes how to enable distributed machine learning with the H2O framework on Qubole Spark clusters to train H2O models on large datasets from the cloud-based data lake.
The data science ecosystem has been growing rapidly for the last few years. H2O’s AI is a part of that ecosystem and is a modern open-source machine learning framework. H2O’s statistical algorithms include K-means clustering, generalized linear models, distributed random forests, gradient boosting machines, naive bayes, principal component analysis, and generalized low-rank models.
Qubole Spark Cluster
Having access to a Qubole Spark Cluster is a prerequisite for this article. Please refer to the following documentation if you do not have Qubole Spark Cluster yet.
Setting up Qubole Account: https://docs.qubole.com/en/latest/admin-guide/how-to-topics/provision-a-new-account.html
Configuring Spark Cluster: https://docs.qubole.com/en/latest/user-guide/spark/spark-cluster-configurations.html
Installing H2O on Qubole Spark Cluster
In order to install the H2O framework on a Qubole Spark cluster, you need to include a few lines of code into the cluster’s bootstrap. First, navigate to the Clusters page, hover the mouse over …, and click Edit Node Bootstrap as in the following image. You can find more information on the Node Bootstrap in this documentation.
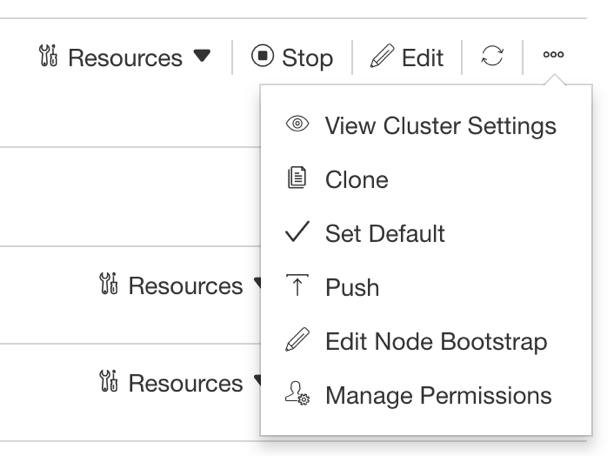
Enter the following script into the bootstrap window and save:
pip install 'colorama>=0.3.8' cd /media/ephemeral0 mkdir h2o cd h2o wget https://h2o-release.s3.amazonaws.com/sparkling-water/rel-2.1/23/sparkling-water-2.1.23.zip unzip -o sparkling-water-2.1.23.zip 1> /dev/null cp /media/ephemeral0/ h2o/sparkling-water-2.1.23/assembly/build/libs/*.jar /usr/lib/spark/lib/ pip install /media/ephemeral0/h2o/sparkling-water-2.1.23/py/build/dist/h2o_pysparkling_2.1-2.1.23.zip
This bootstrap script installs H2O framework support for both PySpark and Scala.
Using H2O with PySpark
Once the H2O framework is installed, it can be utilized with PySpark using Qubole Notebook. A sample PySpark notebook H2O-ChicagoCrime.json can be downloaded from this link. Please follow this documentation for more information on importing notebooks into your Qubole Environment. After the import finishes, the notebook will look similar to the screenshot below.
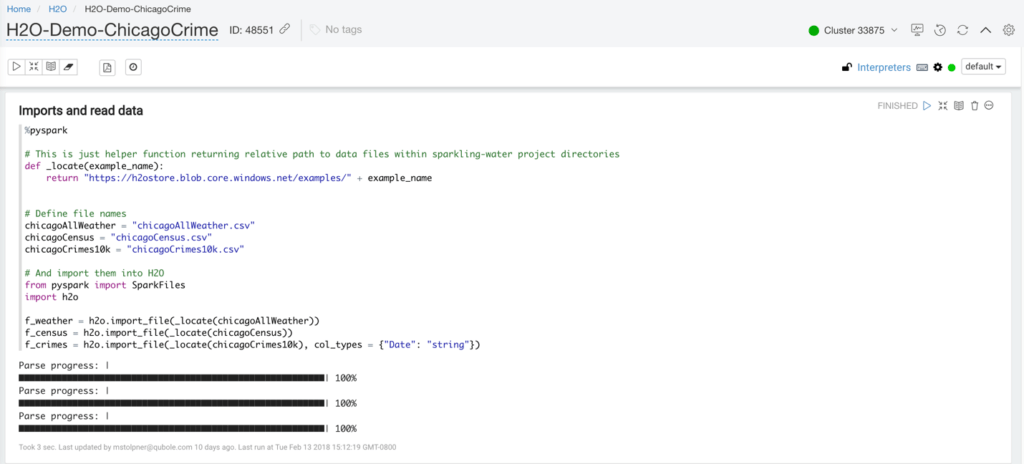
Configuring Interpreter
It’s important that the following configuration is applied to the interpreter. This configuration is the same for PySpark and Scala notebooks.
- executor.cores are set to 1
- spark.dynamicAllocation.enabled is set to the false
- executor.instances is set to the number of executors you need to execute your job. This value depends on the dataset size and the number of splits. Keep in mind that the auto-scaling has been turned off with the previous parameter.
Please refer to this document for more information on the Interpreter configuration.
Using H2O with Scala
Once the H2O framework is installed, it can be utilized with Scala using Qubole Notebook. A sample Scala notebook H2O-ChicagoCrime-Scala.json can be downloaded from this link. Please follow this documentation for more information on importing notebooks into your Qubole Environment. After the import finishes, the notebook will look similar to the screenshot below.
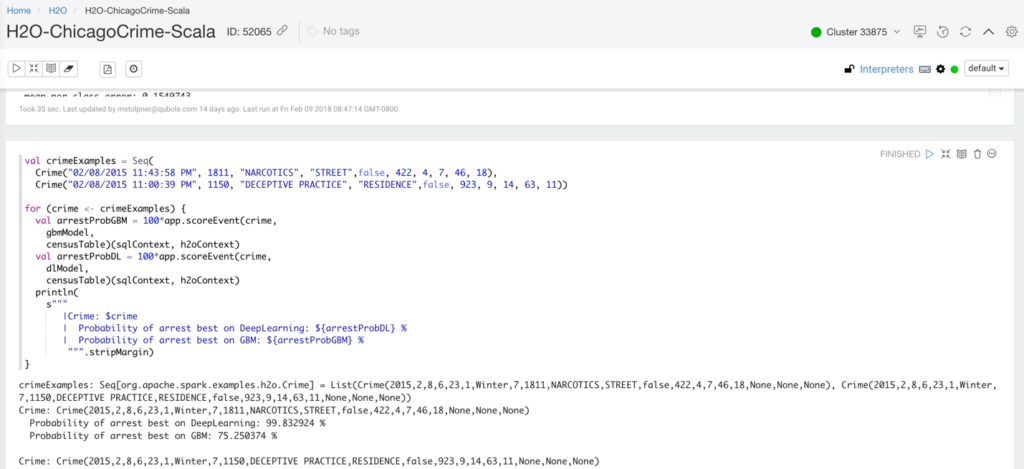
Configuring Interpreter
It’s important that the following configuration is applied to the interpreter. This configuration is the same for PySpark and Scala notebooks.
- executor.cores are set to 1
- spark.dynamicAllocation.enabled is set to the false
- executor.instances is set to the number of executors you need to execute your job. This value depends on the dataset size and the number of splits. Keep in mind that the auto-scaling has been turned off with the previous parameter.
Please refer to this document for more information on the Interpreter configuration.
Using H2O with H2O Flow
H2O Flow is a web-based open source user interface for H2O. Please follow these steps to enable H2O Flow:
- As a pre-requisite, make sure that ports 54321 and 54322 are open on the Spark Cluster’s master node for access from your computer. If you do not have access to your AWS account, you may need to ask your IT people for help.
- Download and import H2O-Demo-Flow.json Please follow this documentation for more information on importing notebooks into your Qubole Environment.
- Configuring Interpreter. It’s important that the following configuration is applied to the interpreter. Please refer to this document for more information on the Interpreter configuration.
- executor.cores are set to 1
- spark.dynamicAllocation.enabled is set to the false
- executor.instances is set to the number of executors you need to execute your job. This value depends on the dataset size and the number of splits. Keep in mind that the auto-scaling has been turned off with the previous parameter.
- Execute the first paragraph in the notebook. It will start the H2O framework. The output of the execution of the first paragraph will look similar to the following screenshot:
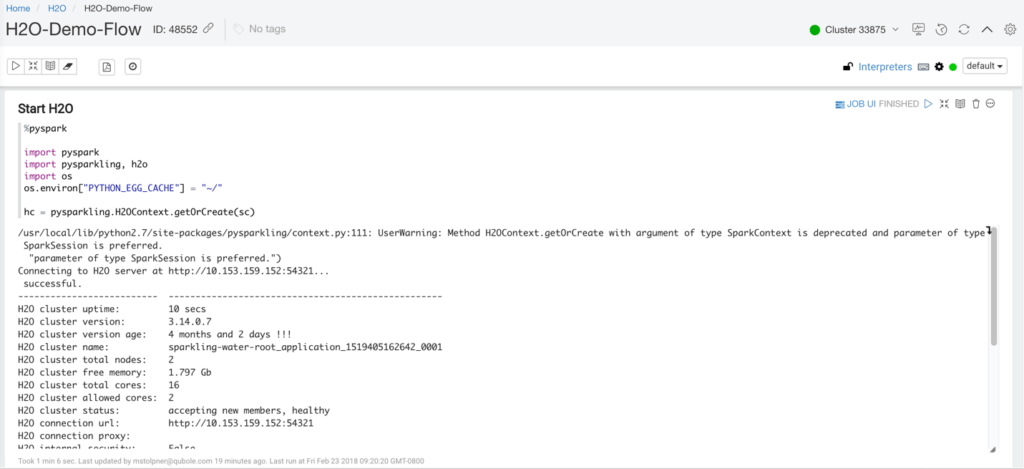
- Navigate to the Clusters page, hover over Master DNS and click the Copy link to copy the master DNS link to the clipboard:

- Navigate your Chrome browser to the Master Node DNS on port 54321. For example, for the master node DNS from the previous paragraph, the URL is https://ec2-54-161-225-151.compute-1.amazonaws.com:54321. It will open the H2O Flow UI.
That concludes the article. The discussion of the H2O algorithms, the notebook source code, the Spark Cluster configurations, etc. is outside of the scope of this article.
We encourage you to try the H2O Machine Learning framework on the Qubole Spark cluster for your big data machine learning needs. Please, feel free to reach out if you have any questions.
References
H2O Home Page: https://www.h2o.ai/
H2O GitHub: https://github.com/h2oai
H2O Flow Documentation: https://docs.h2o.ai/h2o/latest-stable/h2o-docs/flow.html
Qubole Documentation on Setting up Qubole Account:
https://docs.qubole.com/en/latest/admin-guide/how-to-topics/provision-a-new-account.html
Qubole Documentation on Spark Cluster Configuration:
https://docs.qubole.com/en/latest/user-guide/spark/spark-cluster-configurations.html
Qubole Documentation on Node Bootstrap:
https://docs.qubole.com/en/latest/user-guide/clusters/node-bootstrap.html
Qubole Documentation on Importing Notebooks:
https://docs.qubole.com/en/latest/user-guide/notebook/manage-notebook.html#importing-a-notebook
Qubole Documentation on Interpreter Configuration:
https://docs.qubole.com/en/latest/user-guide/spark/use-spark-notebook.html
Sample H2O PySpark Notebook: https://s3.amazonaws.com/public.qubole.com/datasets/h2o/H2O-ChicagoCrime-PySpark.json
Sample SH2O Scala Notebook: https://s3.amazonaws.com/public.qubole.com/datasets/h2o/H2O-ChicagoCrime-Scala.json
Sample H2O Flow Notebook: https://s3.amazonaws.com/public.qubole.com/datasets/h2o/H2O-Demo-Flow.json
The data files are available for download:
https://h2ostore.blob.core.windows.net/examples/chicagoAllWeather.csv
https://h2ostore.blob.core.windows.net/examples/chicagoCensus.csv
https://h2ostore.blob.core.windows.net/examples/chicagoCrimes10k.csv



