HiveServer2 (HS2) is an integral component of any Hive deployment that provides a multi-tenant service end-point for executing Hive queries concurrently. In Qubole Data Platform (henceforth abbreviated as QDP), the HiveServer2 Java Virtual Machine (JVM) runs on the Hadoop cluster’s master node, whereas the Beeline client runs on a multi-tenant tier on the QDP control plane. Because the Hadoop cluster runs on the customer plane (which is not directly accessible by the QDP control plane), Beeline talks to HiveServer2(HS2) JVM through a proprietary proxy service. While HiveServer2 is responsible for the parsing, planning, and compilation of queries, the actual data processing is performed by tasks running on the Hadoop2 cluster’s worker nodes (as shown in the diagram below).
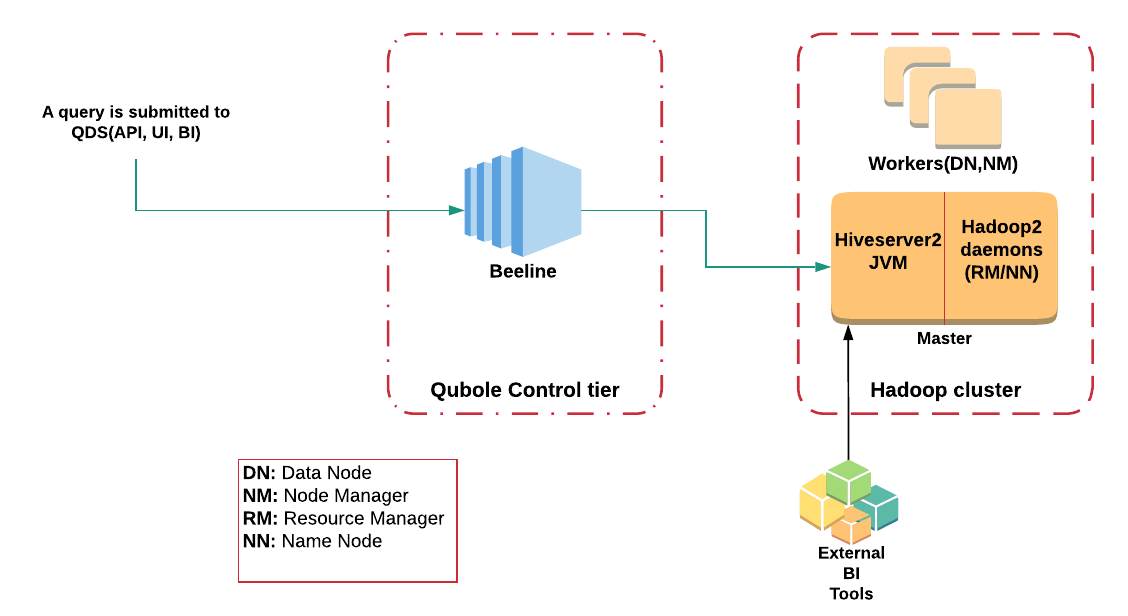
As a centralized service running on the master node, HiveServer2 deployments often face availability, performance, and reliability issues due for the following reasons:
- Single point of failure: If the HiveServer2 JVM is not responding or is down, no queries can be executed.
- Struggle with the appropriate memory setting: Hive has to deal with a “big metadata” problem, where the amount of metadata required to run a query is often much larger than expected because it is proportional to the number of partitions, column stats, permissions, etc. As the memory requirement of the query is proportional to the metadata, configuring a static HiveServer2 JVM memory setting is too rigid. Needless to say, we haven’t considered other components running on the master with their own memory allocation requirements.
- Potential memory leak for long-running queries: Heap/Native Memory leaks add to the complexity of maintaining the long-running HS2 process and lead to degraded HS2 performance over time.
- Potential bottleneck when a computation is autoscaled in the cloud: Qubole Data Platform allows users to configure logical Hadoop clusters that are instantiated when required, autoscale according to the current/pending YARN applications, and shut down automatically when there is a period of inactivity — resulting in substantial cost savings. As the Hadoop2 cluster auto-scales, the HiveServer2 JVM becomes a bottleneck leading to decreased throughput, increased latency, and a higher query failure rate.
- Lack of query / user-level isolation: Unlike the traditional Hive CLI model, HS2 lacks isolation wherein one rogue query can affect all others and lead to the entire cluster performance degradation and user dissatisfaction.
A New Solution: Scalable HiveServer2 Cluster
At Qubole, we tackled this issue by moving HiveServer2 JVM to a dedicated HiveServer2 cluster. The worker nodes in this cluster run the HiveServer2 daemons, while the master node acts as a load balancer. You can see how this works in the diagram below.
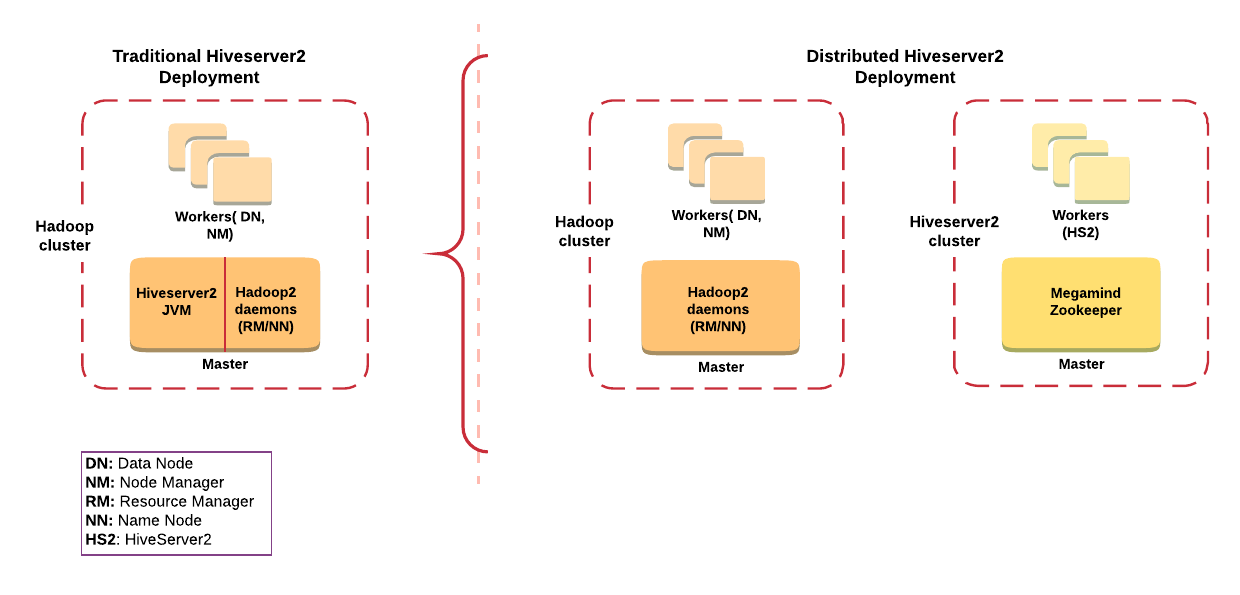
Every Hadoop cluster has a HiveServer2 cluster associated with it and exhibits a parent-child relationship, with the HS2 cluster being the child. The HS2 cluster takes care of running HS2 JVMs, whereas the Tez/MR jobs are submitted to the Hadoop cluster. Owing to this, all of the heavy lifting and memory-intensive processes like parsing, compilation, and planning are distributed among HS2 JVM(s) running on worker node(s) that are horizontally scalable. This avoids memory tension on the master node and theoretically allows for the infinite scalability of HiveServer2 instances.
In the following sections, we discuss the Service Discovery mechanism for distributed Hiveserver2 JVMs, load balancing among JVMs, and finally, the interaction of various components during query execution.
Service Discovery
Open source Hive supports Dynamic Service Discovery through ZooKeeper. HiveServer2 instances running on worker nodes register themselves under a namespace with ZooKeeper to make themselves discoverable and available.
Load Balancer
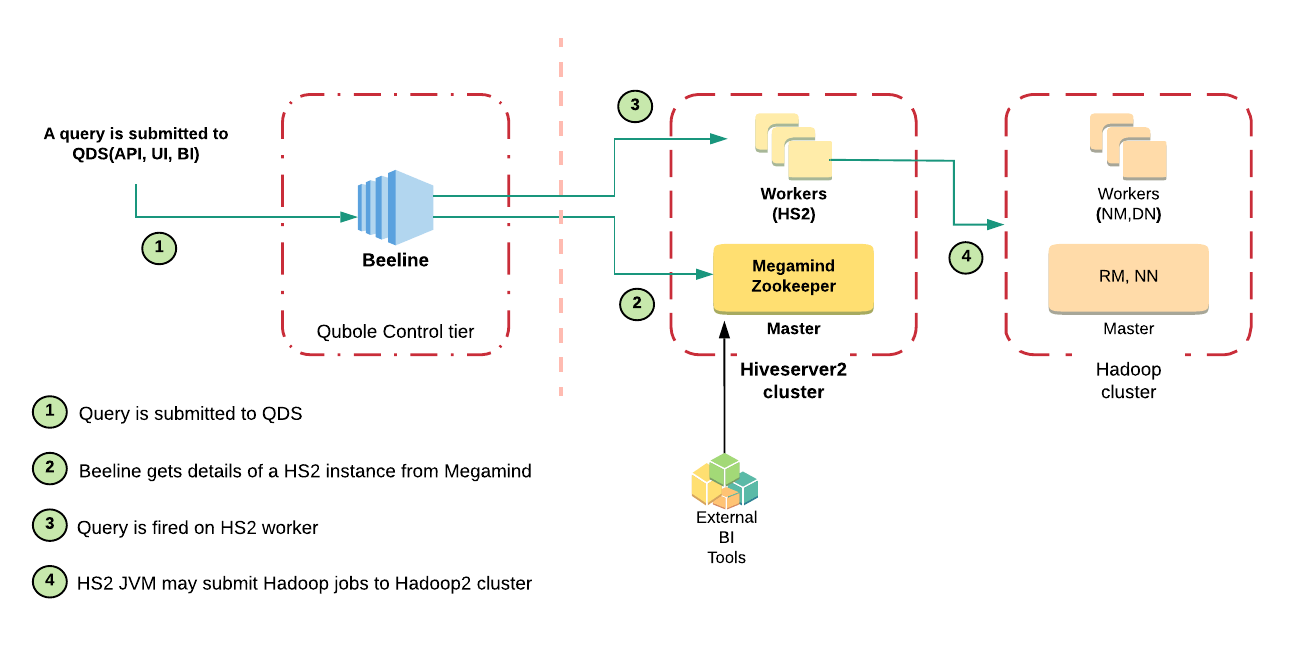
Megamind is a stateless service that keeps track of running HS2 JVMs and distributes queries across them. It runs on the master node and acts as a load balancer and proxy service over ZooKeeper. Megamind opens up an HTTP endpoint through which the Beeline gets the details of the HiveServer2 instance.
Query Flow
When a query is submitted to QDP, Beeline gets the details of the HiveServer2 instance through Megamind (load balancer) and submits the query to the aforementioned HS2 instance. HS2 JVM compiles the query and submits any required MapReduce/Tez jobs to the parent Hadoop2 cluster.
Creating a separate HiveServer2 cluster provides the following advantages:
- Horizontal Scalability
In the single-node HS2 architecture, users often have to configure HiveServer2 overrides to increase the heap size of HS2 JVM or change the master node type so that the single HS2 instance can cater to more queries. This approach of vertical-scaling the HiveServer2 JVM size is not feasible beyond a point and leads to GC issues, and the JVM’s footprint becomes large. With this new design, it is possible to horizontally scale the HiveServer2 cluster by adding worker nodes. - High Availability
As there are multiple HiveServer2 instances running, HiveServer2 JVM isn’t a single point of failure anymore. Even if a few of the nodes/instances go down for some time, other instances take charge. In such a case, the QDP control plane retries the query on a different node, which may lead to a longer time of execution but ensures success. - Limited Isolation
In the traditional model, a HiveServer2 JVM crash causes all running queries to fail. In this case, however, the impact is limited to queries on the particular worker node and is automatically handled via retries on the QDP control plane. This approach also decouples HiveServer2 and the YARN daemon, making the system more robust and reliable. - Ease of Configuration
Traditional HiveServer2 deployment requires a cluster administrator to plan for concurrency ahead of time, and any change in requirement needs a cluster restart and thus downtime. With a HiveServer2 cluster, the administrator need not plan for concurrency because the number of worker nodes can be easily configured at runtime.
What’s Next?
Since HiveServer2 is a long-running JVM, small memory leaks and sometimes even native memory leaks can bring the process to a standstill. In the coming blog(s), we will discuss how the system is made more robust to address these problems. We will also cover workload-aware autoscaling of the HiveServer2 cluster, which removes the pain of configuring the cluster and improves the overall HiveServer2 experience.
Please refer to the documentation to set up and start using HiveServer2 clusters in your Qubole account.



