Introduction
ETL workloads form a major component of big data processing at any data-driven organization – from SMBs to enterprises, and ETL data pipelines at these organizations utilize engines like Hive to extract, transform and load high volumes of data to derive timely insights.
Qubole provides a managed and cloud-optimized implementation of Hive on AWS, Azure, and GCP. This blog highlights the benefits of Hive optimizations on Qubole and their direct impact on cost reduction when compared to alternatives. We have used the TPC-DS (Scale 3000) [1] benchmark to compare the speed and cost of Hive on Qubole using unpartitioned ORC data stored on AWS S3.
The Results
To run these benchmarks, we chose two cluster configurations with different node types and number of nodes, to avoid observation discrepancies arising from node type or count bias. The two cluster-configurations we chose were m5.4xlarge with 4 worker nodes and r5.4xlarge with 8 worker nodes, and we present the results below, where the red bars represent Qubole’s results and the blue bars a competing alternative platform in the market:
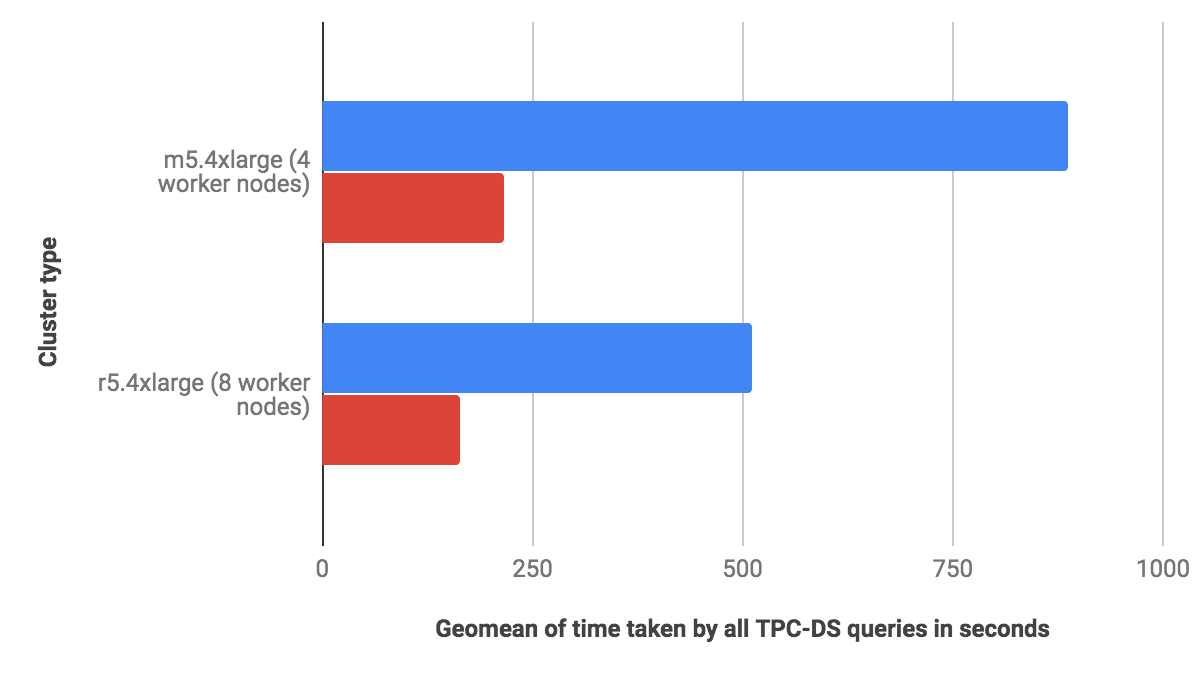
As shown above, Hive on Qubole outperformed Hive on the alternative in all queries and was 4 times faster with the first configuration and 3 times faster with the second.
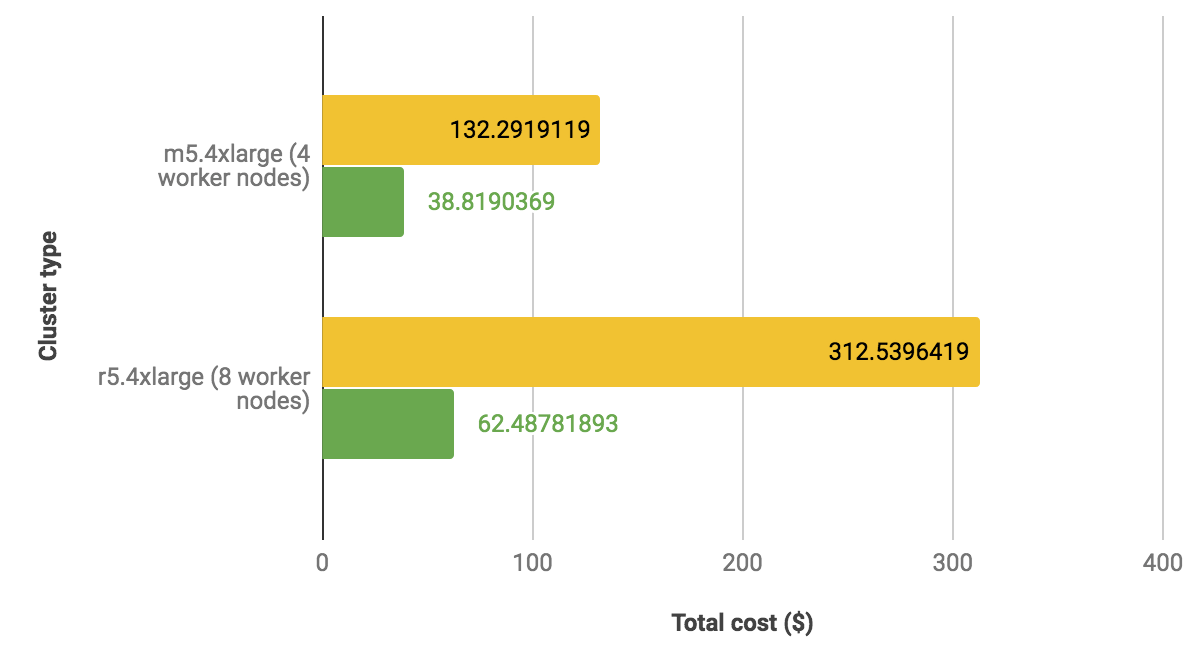
With respect to cost, we observed that the total cost [2] of running TPC-DS queries on Qubole (green bars) was 3.4 times and 5 times less compared to the alternative platform (yellow bars) on the two different configurations, as shown below:
Details:
1. Setup
Benchmark suite: TPC-DS
Scale: 3000
Format: ORC
Type: Unpartitioned
Storage: AWS S3
Statistics: Pre-computed column-level stats
Instance type: m5.4xlarge
No. of worker nodes: four
Software & Components

We ran our experiments on the default Hive configuration available on both the alternative platform and Qubole’s setups, except the alternative platform did not have a hive.strict.checks.cartesian.product disabled which caused a few queries to fail. To get the results for those failing queries as well, we have disabled this config on that platform. Furthermore, we based this comparison on only the queries that succeeded on both platforms.
2. Results
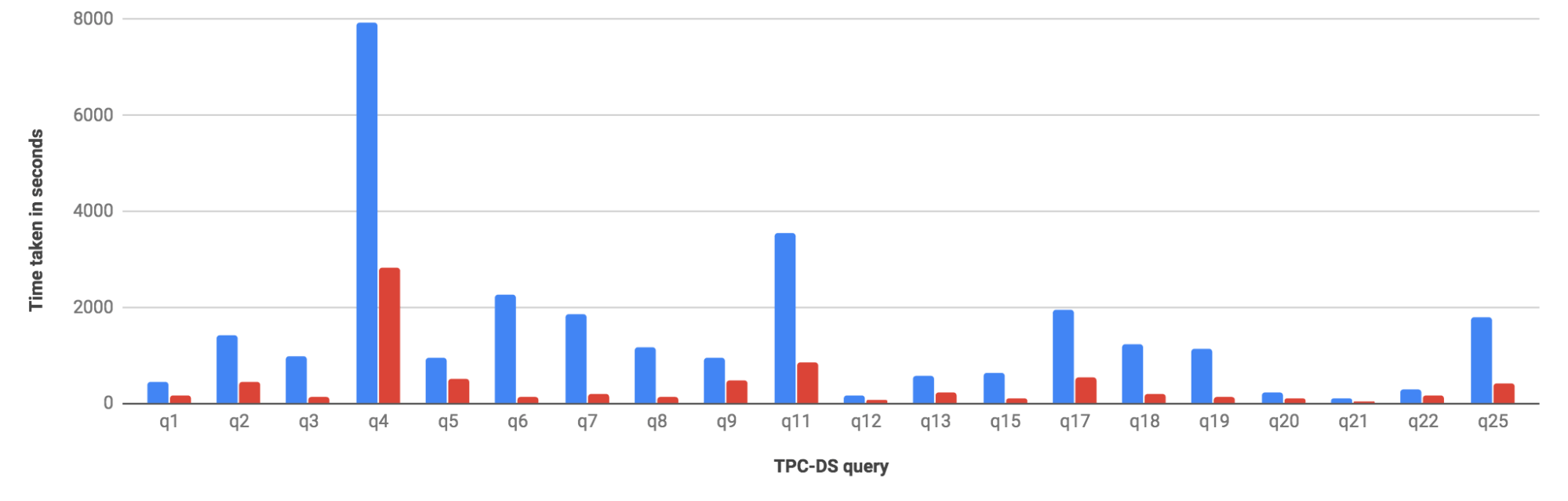
The above chart shows the results for the first 20 queries (click for a larger image), where the red bars represent Qubole and the blue bars represent the alternative platform.
Key observations:
- Hive on Qubole outperforms Hive on the alternative platform for all TPC-DS queries
- Hive on Qubole is 4 times faster than Hive on the competing platform hive [3]
- The cost of running Hive queries on Qubole is 3 to 5 times lower
The difference in the performance of Hive on Qubole can be attributed to the numerous and continuous optimizations to the Hive engine that the Qubole team makes. These range from faster writes, object store-specific optimizations, ORC improvements, optimized resource allocation, utilization, and efficient use of statistics.
At Qubole, our dedicated performance teams are working nonstop to identify new and innovative ways to improve performance.
This test was run using on-demand nodes and compute cost can be further brought down significantly by using Qubole’s cluster lifecycle management and intelligent low cost1 nodes management capabilities – more information on these features is available here.
Qubole recently announced support for Hive 3.1.1 which has new improvements and features and is 1.8 times faster than Qubole 2.3.4 Hive. We encourage you to take advantage of the Hive performance improvements. If you don’t yet have a Qubole environment, you can sign up for a free 14-day Qubole Test Drive.



