As a part of my summer internship project at Qubole, I worked on an open-source Hive JDBC storage handler (GitHub). This project helped me improve my knowledge of distributed systems and gave me exposure to working on a team on large projects.
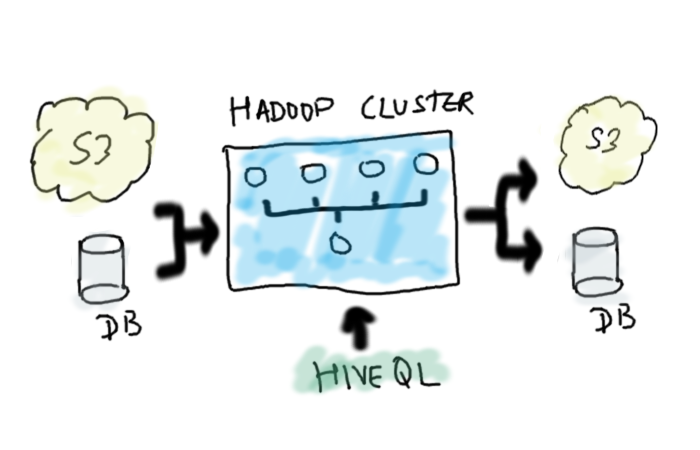
In many big data projects, integrating data from multiple sources is a common and challenging problem. Frequently, dimensional data, like user information, live in a relational DB like MySQL or PostgreSQL. Large semi-structured data like clickstream data often lives in cloud storage like Amazon S3. For certain advanced analytics, we may need to join data across these sources and push results into a reporting database for visualization. For example, when finding out which region has the maximum number of active users.
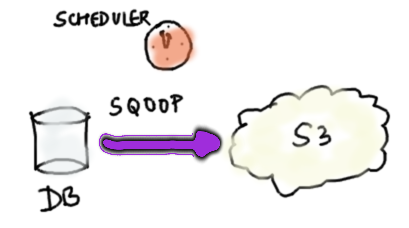
One way to solve this problem is to use a tool like Sqoop to import data from the DB into HDFS / S3 and create a Hive table against it. This imported table can be now joined with other large Hive tables. Similarly, Sqoop can be used to export a result table back into a reporting DB. Many of our customers use our Scheduler to periodically re-import the DB to capture new data. This solution works well when the data in DB doesn’t change very frequently. However, some of our customers had use-cases where the DB does change frequently and we needed an alternate solution.
Hive has a mechanism called storage handlers that can be used to plug in other live data sources. A storage handler for DBs based on JDBC would suit our purposes perfectly. We could create external Hive tables and map them to a DB table. A query to the Hive table would get re-routed to the underlying DB table.
We first did a little research and found references to two projects from the Apache JIRA HIVE-1555. The first one is linked here and didn’t seem to be actively maintained. The other project by Qubit, linked here, was more recent. We preferred the first project since it reuses DBInputFormat class from Hadoop which implements connectivity code to DB via JDBC. However, we found that the code-base was lacking the predicate push-down functionality.
To understand predicate push-down, let’s take a simple query against a table db_table (backed by a DB) that contains a million rows where id is a primary key.
| select * from db_table where id < 50000 |
The naive approach to executing the query is to retrieve all the million rows from the DB and let Hive filter rows where id < 50000. However, it would be much more efficient to push this predicate to the DB and fetch only the records that match this condition via JDBC. The DB, in this case, could use the primary key index to fetch the 50000 records efficiently. This is called predicate push-down.
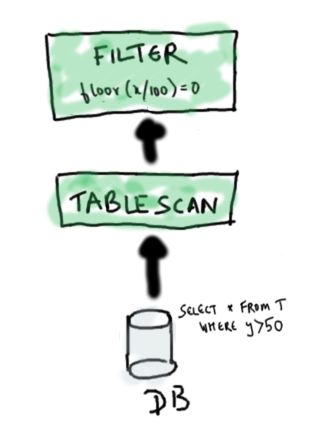
The predicate push-down functionality required implementing a special function that can take a predicate in the WHERE clause and split it into two parts: one part is sent to the data source, while the rest is evaluated in Hive. In the example above, the predicate y > 50 is sent to the DB via JDBC, and the predicate floor(x/100)=0 is evaluated in Hive.
The storage handler also does split computation by computing a total number of rows in the table and splitting them into as many chunks as desired. Each mapper will send a SQL query with an OFFSET and LIMIT clause corresponding to its share of input data. This functionality is inherited from DBInputFormat.
As mentioned earlier, this code is available on GitHub with an Apache License and is compatible with Apache Hive and Hadoop 1.x, and Hadoop 2.x. Instructions to build the storage handler from a source are available in the README file. Once the jar has been built, you can connect to a DB by adding the jar and creating an external Hive table with specific table properties. The table properties will contain information about the JDBC driver class to use, hostname, username, password, table name, etc. You may also need to add the JDBC driver jar if it isn’t packaged already. If you are a Qubole user, the storage handler jar is readily available in our public bucket.
| ADD JAR s3://paid-qubole/jars/jdbchandler/qubole-hive-jdbc-handler.jar ; DROP TABLE HiveTable; CREATE EXTERNAL TABLE HiveTable( id INT, id_double DOUBLE, names STRING, test INT ) STORED BY ‘org.apache.hadoop.hive.jdbc.storagehandler.JdbcStorageHandler’ TBLPROPERTIES ( “mapred.jdbc.driver.class”=”com.mysql.jdbc.Driver”, “mapred.jdbc.url”=”jdbc:mysql://localhost:3306/rstore”, “mapred.jdbc.username”=”—-“, “mapred.jdbc.input.table.name”=”JDBCTable”, “mapred.jdbc.output.table.name”=”JDBCTable”, “mapred.jdbc.password”=”—-” ); |
Voila! Now, you can run queries against the Hive table. You can also push data into this table using INSERT statements. A word of caution: one must be careful to not overwhelm an operational DB with analytic queries – it is advisable to set up read replicas and create Hive tables against them. We look forward to your feedback on this project and welcome pull requests!
Qubole has a bunch of highly talented people that helped me out completing this project; my mentors Pavan Srinivas and Shubham Tagra were always of great guidance and help.
If you’d like to work on Big Data systems like Hadoop, Hive, Presto, and Spark, please send us a note at [email protected].



