Over the course of the next month, we will be going deeper into some of the trends uncovered in our 2018 Big Data Activation Report. In this post, we look at the trend of companies who have migrated their Hadoop resource manager from MapReduce (Hadoop 1) to YARN (Hadoop 2) in the past two years and the resulting benefits.
It’s been over a decade since Hadoop first entered this world. Spawned from Google’s MapReduce white paper and the founding of Nutch, Hadoop has come a long way in the enterprise from being just another Silicon Valley tool. Hadoop’s first recorded massive scale production was by Yahoo! in 2007 on a 1,000 node cluster. Today, Apache Hadoop has evolved into a technology that touches almost every aspect of the big data and analytics ecosystem and can be tuned for a multitude of use cases, from massive-scale ETL to advanced analytics. It is often installed with, or alongside, open-source software such as Apache Hive, Apache Spark, Apache Zookeeper, Apache Flink, Apache Sqoop, and Apache Storm.
Following the release of Hadoop 2, and now Hadoop 3.0 (which also runs on YARN), much of the big data community has upgraded their systems to this newer software primarily because of the improved security capabilities and performance gains from YARN (an acronym for “Yet Another Resource Negotiator”) to manage compute resources and capabilities to handle different libraries. The performance difference between YARN and MapReduce as resource managers might be the greatest benefit of Hadoop 2, as workloads aren’t limited to working on the Hadoop MapReduce framework, which frequently becomes very I/O (Input/Output) intensive and causes major latencies.
History of Hadoop at Qubole
At Qubole, Apache Hadoop has been deeply rooted in the core of our founder’s technology backgrounds. Qubole’s co-founders, JoyDeep Sen Sarma (CTO) and Ashish Thusoo (CEO) came from some of these early-Hadoop companies in the Silicon Valley and built their careers at Yahoo! and Netapp. It was during their tenure at Facebook where they realized Hadoop would be a perfect match for handling data and enabling self-service access in the company’s rapid growth phase.
At this time there was no such thing as public cloud, and Hadoop was still only a few years out of its infancy. At the same time, the team needed a way to make information accessible and hyper-scalable across Facebook. This resulted in Apache Hive, a framework for managing Hadoop that provides a query language and structure to allow users to query using more commonly used language such as SQL. The engine became a huge success for driving Facebook’s data-driven culture, which enabled self-service access to data across every department and partner.
State of Hadoop Today: From MapReduce to YARN
In Qubole’s 2018 Data Activation Report, we did a deep-dive analysis of how companies are adopting and using different big data engines. As part of this research, we found some fascinating details about Hadoop that we will detail in the rest of this blog.
A common misconception in the market is that Hadoop is dying. However, when you hear people refer to this, they often mean “MapReduce” as a standalone resource manager and “HDFS” as being the primary storage component that is dying. Beyond this, Hadoop as a framework is a core base for the entire big data ecosystem (Apache Airflow, Apache Oozie, Apache Hbase, Apache Spark, Apache Storm, Apache Flink, Apache Pig, Apache Hive, Apache NiFi, Apache Kafka, Apache Sqoop…the list goes on).
At Qubole, we’ve seen a massive change in the usage of Hadoop having the cloud paradigm of being able to decouple storage from compute, in which cheap object stores are taking the place of HDFS. Having this data in a centralized place also enables companies to quickly upgrade their systems, such as moving their clusters to run on advanced resource managers such as YARN, by having ephemeral compute where they can easily test their same code on new engines and then scale as they see the value.
Traditionally, workloads on Hadoop 1 could only run with MapReduce framework to process the data, which would then be stored in HDFS servers or a data lake with object storage that could properly organize the files (such as Amazon S3 or Azure DL). This meant that no applications other than Hadoop MapReduce would be able to run in the cluster. Hadoop 2 emerged with a new operating system and framework called YARN (see diagram below from Hortonworks), which is able to run non-MapReduce jobs such as Spark, Hive on Tez, Giraph, and HBase co-processors.
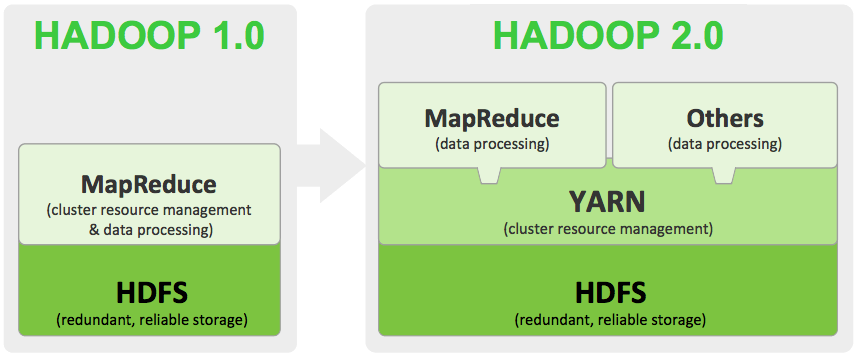
Mass Migration to Hadoop 2
We have seen a mass migration to Hadoop 2 happen at Qubole in a huge way, with almost the entirety of our customers have moved their workloads to Hadoop 2 between 2016 and the present day. Looking at Hadoop 1 and Hadoop 2 combined, Hadoop has grown by 102% overall when we compare 2017 to 2016 total usage, even with Hadoop 1’s deprecation and the community moving to support Hadoop 2 going forward. As workloads have moved to Hadoop 2, usage has increased by 364% since December 2016, while Hadoop 1 (Hive on MR) has declined by 308% in usage.
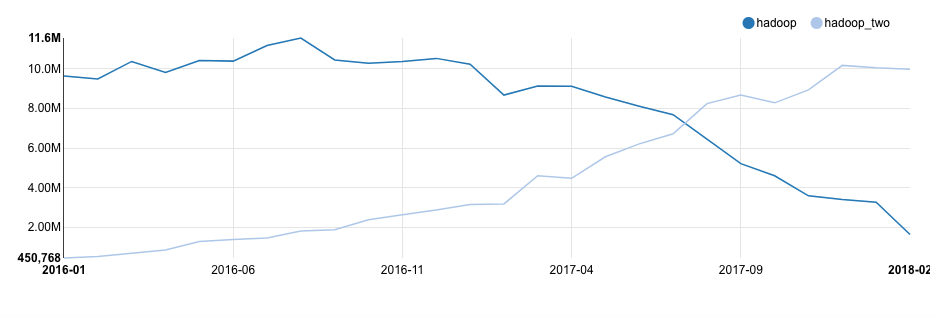
One of the main reasons Qubole users were able to migrate massive Hadoop 1 workloads over so quickly is because of the cloud computing capabilities that offer zero-downtime upgrades with ephemeral clusters. This is because their infrastructure foundation is built on data lakes, where object storage works in place of HDFS storage. This allows companies to test different engines against their same data and only scale up once they see the value. Qubole makes this extremely easy for users to do with autoscaling for big data clusters and having workbenches to develop and move code to different engines.
As the graph above shows, in under six months, companies were able to rapidly migrate massive production workloads on tens of thousands of servers running each month. This shift to Hadoop 2 not only shows how quickly data teams can seamlessly migrate workloads but also how they can more efficiently scale and try new technologies with their existing code.
Reliability and Cost Effectiveness of Hadoop 2 in the Cloud
A huge trend we’ve noticed in the last year is that Hadoop 2 used an average of 1.71x more Amazon EC2 Spot Instances per cluster than Hadoop 1. As you can see in the graph below, on the percentage of 2017 Spot Instances usage, an average of 62% of all Hadoop 2 instances and only 36% of Hadoop 1 instances leverage Spot compared with on-demand nodes. Spot Instances are essentially a bidding market (often referred to as “the Spot market”) where AWS releases un-utilized EC2 compute nodes for ~1/10 the ‘on-demand cost — the caveat is that another user could outbid you and take the compute nodes, so inherently this could cause instability for massive workloads. Beyond performance improvements, it is safe to say that Hadoop 1 was costing our users almost twice as much as Hadoop 2!
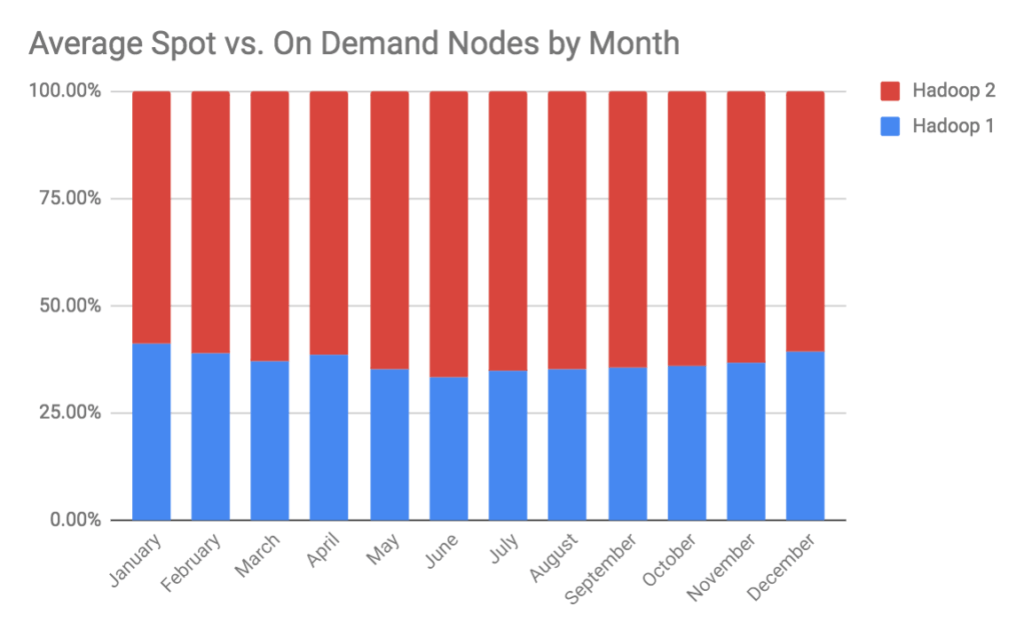
By comparing the graph above with the comparative Spot usage trend line below, we can see a huge swing in Spot usage going to Hadoop 2 from January to December 2017; and moreover, conclude that this engine is significantly more reliable at scale when it comes to handling things like Spot. We can associate this trend with the dynamic resource management capabilities provided by YARN combined optimizations built at Qubole such as our Heterogeneous Spot Instance capability, which can dynamically re-provision to other Spot nodes in the same instance type (e.g. one m1.2xlarge node = two m1.xlarge nodes). The webinar highlighted in the link above explains how to run Hadoop and Spark clusters with hundreds of nodes at 80-100% Spot Instances reliably.
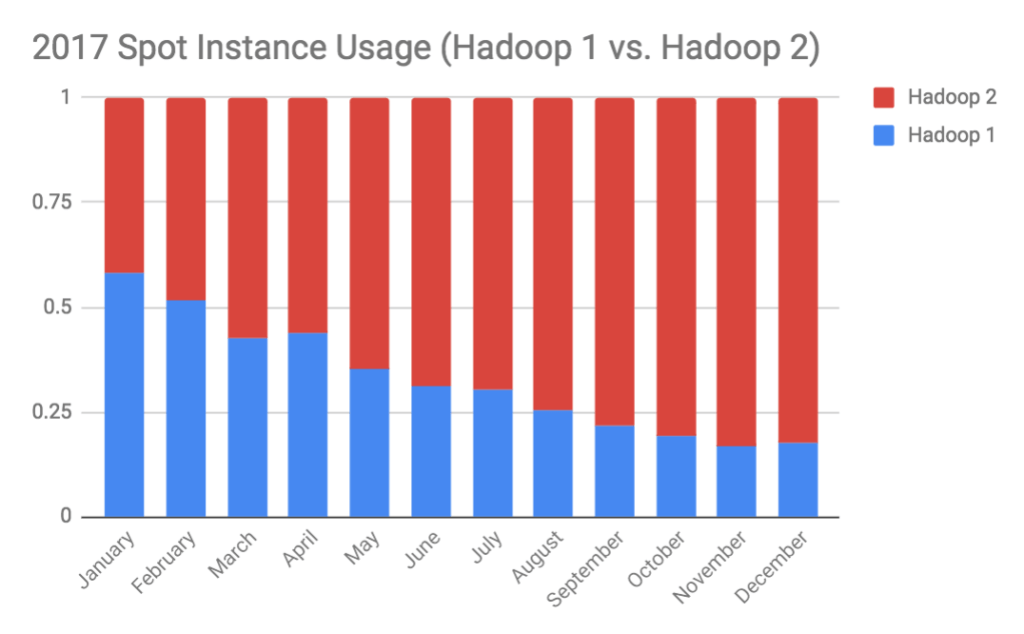
As a quick recap of the article, with the help of YARN’s framework, we have seen that companies are able to run larger clusters on Hadoop 2 than Hadoop 1 without encountering scalability bottlenecks or reliability issues with Spot Instances. The value underlying Hadoop 2 on Qubole boils down to several aspects:
- Rather than the MapReduce job tracker, which traditionally managed both jobs and tasks together, YARN overcomes these limitations by splitting resource manager and application master architecture.
- Having cloud infrastructure that enables storage and compute to be separated (rather than fixed to HDFS) with ephemeral clusters allows teams to quickly test, develop, and productionize new workloads.
- Qubole autoscaling for Hadoop brings together the capabilities of YARN and cloud infrastructure.
Right Tool, Right Job
Having a framework that can support a multitude of engines is the reason why Hadoop has been so resilient in the market today and evolved into a true enterprise-grade technology. Hadoop’s capabilities to integrate across the big data ecosystem have made it an invaluable asset to a majority of data platforms today, touching everything from massive-scale ETL pipelines (with Apache Hive) to data security to business intelligence (leveraging Presto’s engine) or advanced analytics and machine learning (using Apache Spark). At Qubole, our mission is to enable self-service access to these engines so that each team can collaborate with big data using the interfaces that best suit their workflows, whether they focus on analytics or data engineering.




