Extract, Transform, Load (ETL) workloads are an important use case of Apache Spark for Qubole customers. In particular, the performance of INSERT INTO / OVERWRITE SQL queries can significantly affect the overall cost of the workload. In this blog post, we will discuss Direct Writes — a Spark optimization built by Qubole Engineering that delivers performance improvements of up to 40x for write-heavy Spark workloads.
Current State of Writes for Hive Tables in Spark
Writes to Hive tables in Spark happen in a two-phase manner.
- Step 1 – DistributedWrite: Data is written to a Hive staging directory using OutputCommitter. This step happens in a distributed manner in multiple executors.
- Step 2 – FinalCopy: After the new files are written to the Hive staging directory, they are moved to the final location using the FileSystem rename API. This step, unfortunately, happens serially to the driver. As part of this, the metastore is also updated with the new partition information.

Issues with Writing to Object Store–Backed Hive Tables
The approach explained above has been implemented keeping HDFS in mind. Renaming a file or directory in HDFS is a fast atomic operation (a synchronized metadata change in namenode). This means we can keep writing data to a temporary directory in a distributed manner. If all of the tasks finish successfully, then rename the files written in the temporary directory to a final directory. If some failure happens, discard the entire temporary directory. However, a typical write operation in Spark generally has multiple new files, and renaming multiple files/directories is not atomic in HDFS. It is still pretty fast, leaving a very small window for data corruption.
However, for cloud object stores like S3, this doesn’t work as expected. Possible issues include the following:
1. Slow Rename Operation on Object Stores
Renaming a file in an object store like S3 is expensive. A rename internally copies the source file to the destination and then deletes the source file. As part of the FinalCopy step (described above), the renaming of new files happens serially in the driver. This increases the overall run time of the job by a huge margin. To measure this, we did some analysis of our customer workloads as shown in Figure 1 below:
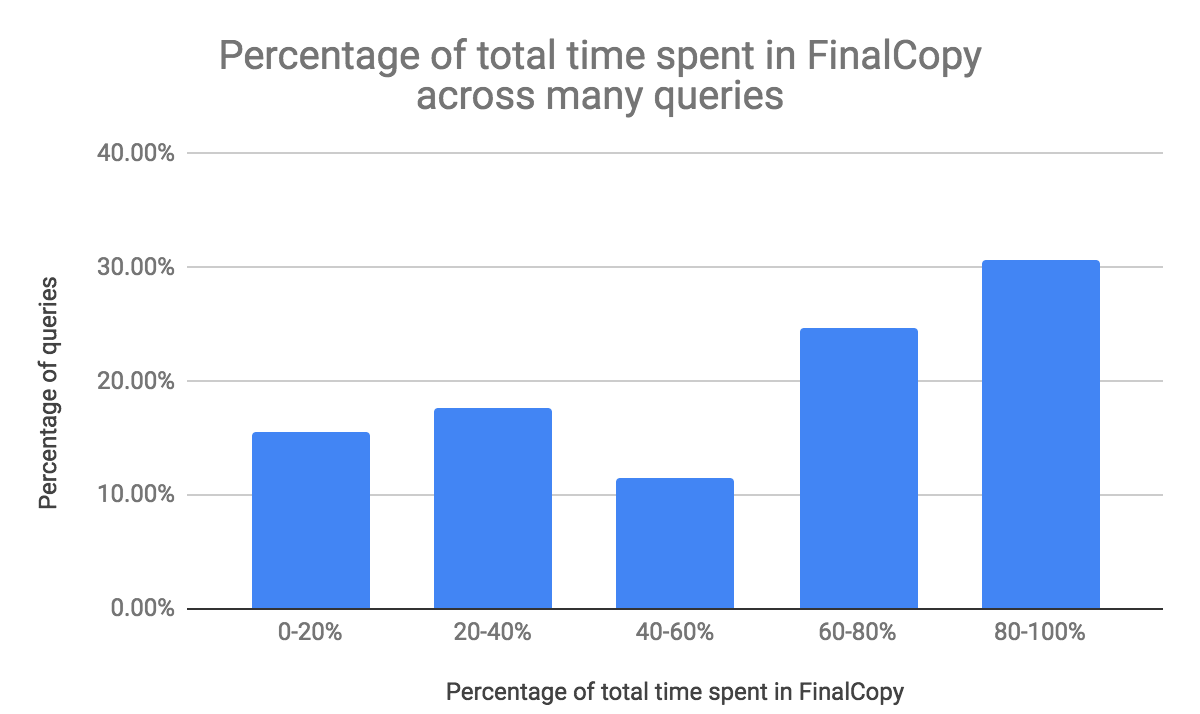 Figure 1
Figure 1
Figure 1 shows that:
- For > 25% of INSERT operations, FinalCopy takes 80 to 100 percent time of overall query runtime.
- For > 50% of INSERT operations, FinalCopy takes more than 60 percent time of overall query runtime.
This shows that for INSERT operation, the majority of time is spent in the FinalCopy step. In addition to causing a performance issue, this also opens up a bigger window for the corruption of the destination directory due to JVM/Node failure (ex: AWS Spot loss).
2. Eventual Consistency Issues
Cloud object stores like S3 provide eventually consistent writes. As explained earlier, while writing to Hive tables, new files are written to the temporary directory and then moved to the final location immediately. Since writing to an object store is eventually consistent, these files may not be visible immediately. Due to this, we have observed a rename operation failing with FileNotFound exception.
Solution: Direct Writes
In the previous section, we explained why the native Hive table write approach in Spark is suited only for HDFS and doesn’t work well for object stores. But for DataSource tables (Spark native tables), the above problems don’t exist. This is because the DataSource write flow skips writing to a temporary directory and writes to the final destination directly. This avoids the FinalCopy operation — which was the most time-consuming operation in the Hive table write flow. This significantly improves overall performance. Also, writing directly to the final location avoids the immediate rename, thus avoiding the object store EC issues.
Inspired by the DataSource flow, We have made similar changes to the native Hive table write flow in Spark. As explained above, this prevents both problems that were discussed in the earlier section. So the new write flow becomes:

Handling Dynamic Partitions with Direct Writes
Insert operations on Hive tables can be of two types — Insert Into (II) or Insert Overwrite (IO). In the case of Insert Into queries, only new data is inserted and old data is not deleted/touched. But in the case of Insert Overwrite queries, Spark has to delete the old data from the object store. There are two different cases for I/O queries:
- Insert Overwrite with Static/No Partition
- Insert Overwrite with Dynamic Partition
You can find more details about Static/Dynamic partitions here. In the case of a query with IO + Static/No partition, we can easily figure out what data to delete before the write begins. We construct the partition path from the static partition information and delete files in it. But the same is not true for IO with Dynamic Partition. Writes to dynamic partitions delete the old files only in partitions that are modified by the query. And the partitions modified by the query are known only after the entire DistributedWrite phase is finished. To handle that, we have implemented UUID-based file deletion in Direct Writes:
- Every write query is assigned a UUID. All new files written as part of this query will have a UUID in the name (ex: part-00225-cfd077ee-55a1-4752-8946-5d8b8816eb22.c000).
- We keep track of a list of files written by different tasks running on executors. This will tell us the partitions that are touched by the query.
- Once the entire write is done, we list all the files in the modified partitions and delete the files that don’t contain the query UUID.
Performance Evaluation
Benchmark setup
- Cluster configuration:
- 1 r3.2xlarge Master node
- 4 r3.2xlarge Worker nodes – each worker running 1 executor with 8 cores and 52 GB memory
- 300 partitions
- Table schema:
- src_table – (year – String, month – String, date – String, dataCol – String)
- dst_table – (year – String, month – String, date – String, dataCol – String)
Query
INSERT OVERWRITE TABLE dst_table SELECT * FROM src_table
| Data Size | Without DirectWrites | With DirectWrites | Improvement |
| 10 GB | 1754 sec | 56 sec | 31x faster |
| 100 GB | 4857 sec | 259 sec | 18.7x faster |
As observed above, a query with different data sizes gives an improvement in the order of multitudes. Note that if the write is distributed among more tasks, we will see more gains in performance so that gains are proportional to the parallelism provided by a cluster.
Conclusion
This post explains the direct write optimizations we have added to Spark on Qubole 2.2.1+. The optimizations provide huge improvements (up to 40x) in the INSERT queries for all file formats on Hive tables.
For more information about Spark workloads, check out our guide to Spark on Qubole.



