A while back we shared the post about Qubole choosing Apache Airflow as its workflow manager. Then last year there was a post about GAing Airflow as a Service. In this post, I’ll talk about the challenges—or rather the fun we had!—creating Airflow as a service in Qubole.
After creating QuboleOperator, which connects Airflow and Qubole, we felt that customers (especially enterprise customers) would want much more. Some of the common pain points for these enterprise customers were:
- Figuring out Airflow’s configuration
- Setting up required services like Celery, Rabbitmq, and Flower
- Ensuring the installation is secure and accessible to its users
- Devising a way to authenticate and authorize users
- Setting up monitoring and alerting
- Setting up crons to backup services logs to S3
- Auto syncing DAGs from S3 or GitHub
- Setting up AWS keys in Airflow so it can upload task logs to S3
We anticipated those pain points and came up with the solution of bundling tools and features in such a way that the intricacies of Airflow are hidden. This bundling makes Airflow a truly as-a-service tool, eliminating the top enterprise pain points with the click of a button. While we did face challenges while building this system, this post is about the fun.
#1: Hosting Airflow behind an Nginx proxy
This is the first step any enterprise user would want to do. The typical user wants a simple URL that can be bookmarked and will remain the same even if the machine gets rebooted. In cloud environments, this link would later lead to a new IP address unless you are using Elastic IPs.
In Qubole the URL would be something like this: https://api.qubole.com/airflow-webserver-19289/admin/, where 19289 is the id of cluster.
To have all pages accessible via a common prefix, we’ve made changes in the code itself. Unlike with Celery Flower there was no option to specify a prefix URL. There were two types of URL being used in the Airflow codebase:
- Flask’s URL for method
- Hardcoded and relative URLs
We’ve found a nice way to add a prefix to each URL by overriding the URL for method. It saved us a lot of time and kept the code clean. For the hard coded and relative URLs, we have to go through each page and convert them to the URL for method.
@app.context_processor
def override_url_for():
return dict(url_for=proxified_url_for)
def proxified_url_for(endpoint, **values):
return "/{0}{1}".format(airflow_webserver_proxy_uri, url_for(endpoint, **values))Here “airflow_webserver_proxy_url” would be something like this:
https://api.qubole.com/airflow-webserver-19289/
We also made a couple of changes to the way the Flask Admin app gets configured and how views get added to it. However, there remained a single link that could not be fixed, and that was the main “DAGs” link. So we did a hack and added following JavaScript code to the master.html file.
//hacky way of replacing broken link with correct link dag_link = $("ul.navbar-nav:first > li:first a")[0]; dag_link.href = "{{ url_for('admin.index') }}";
The end result was beautiful. We have no broken pages and Airflow UI can be accessed via the nginx proxy only, after a successful authentication and authorization via the Qubole tier.
#2: Moving assets to CDN
Soon after we GAed Airflow as a service, we got feedback about the Airflow UI becoming slow in an unusable way. The cause was clear—Airflow’s index page does roughly 20-22 calls to fetch html, JS, CSS and images. All these calls goes through the following stack if the cluster is in VPC:
Browser => Qubole web node => Tunnel => Bastion Node => Airflow cluster
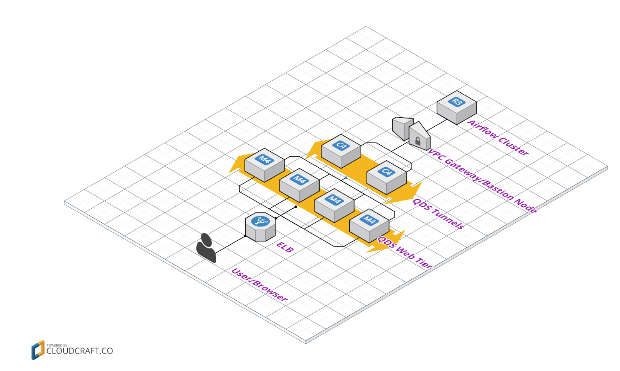
As you can see, each call has to go through three extra hoops, so the index page which loads in roughly 10 seconds on my local laptop was taking anywhere between 30-60 seconds to load for users. I tried to do http caching on static assets, but couldn’t figure out a way to do that in Flask. Then we chose a better way—putting assets onto CDN. Once again, the override URL for method came to our rescue. We filtered out and redirected asset calls to CDN. This small enhancement cut down the total page load time to only 3-4 seconds; much faster than running Airflow on my MacBook—Awesome!
def proxified_url_for(endpoint, **values): if 'filename' in values: return "{0}{1}".format(cdn_url, url_for(endpoint, **values)) return "/{0}{1}".format(airflow_webserver_proxy_uri, url_for(endpoint, **values))
#3: Adding the Goto QDS button
Most of the customers found this feature super helpful, as it saves them a lot of time. To make this work, we had to make some changes to Airflow’s UI code base to pass on the task’s operator class. We also added a new route in the Flask App to support these calls. This makes use of Airflow’s XCom feature to fetch Qubole command IDs and redirect them to the actual command running on the Qubole platform. As it is a Qubole-only feature, it has not been merged into open source. Also, this feature’s associated button becomes visible only for QuboleOperator type tasks.

#4: Authentication and Authorization through Qubole
All authentication and authorization on Airflow now happen via the Qubole control panel. As of now, there are only two types of authorization that happen after successful authentication.
Cluster admin => The person who has update access on the cluster and can access all pages.
![]()
![]()
Cluster user => The admin panel gets hidden and will not be accessible for users who do not have update access on the cluster.
![]()
![]()
#5: Interoperability between Airflow and Qubole
Thanks to Airflow’s on_failure and on_retry hooks we were able to make sure that if an Airflow worker reports a failure we hit the Qubole command API and verify its status. If the command status is “success” then we mark that Task instance as a success, and as “failed” if it failed. If the command is still running we kill the command in Qubole and mark the TI as failed.
The above feature could be useful in the event a worker dies (although that hasn’t happened yet) or a whole node goes down. In such cases, Airflow’s scheduler will assume these tasks to be Zombies and tries to mark them as failed. Using the above callbacks we were able to keep a constant sync between Qubole and Airflow.
Scheduler’s Zombie detection, callback hooks, and the four lines of code below are making this sync happen.
if cmd.status == 'done': logger.info('Command ID: %s has been succeeded, hence marking this TI as Success.', cmd_id) ti.state = State.SUCCESS elif cmd.status == 'running': logger.info('Cancelling the Qubole Command Id: %s', cmd_id) cmd.cancel()
#6: Auto uploading task and service logs to S3
Apache Airflow automatically uploads task logs to S3 after the task run has been finished. However, it relies on the user having setup proper access/secret keys, and so on. As we already have these keys present on the Airflow cluster, we replaced the open source code with our own and made sure that task logs gets uploaded properly. We made a similar change when logs were being fetched from S3. This process is even more effective if users are using IAM roles.
By default we also set a cron to periodically upload service logs (webserver, scheduler, workers, rabbitmq) to S3.
#7: Using Monit to manage services and monitoring
We were able to use Monit successfully for monitoring and restarting services. We also used it to send us alert messages in the event a service could not be started at all. It also gave us some simple commands to manage Airflow services, like Monit start/stop/restart webserver/scheduler/worker
#8: Qubole goodies
As with any other big data engine, a Qubole-Airflow integration automatically entitles users to Qubole goodies. These include:
- Single click cluster start and stop
- Support for IAM roles
- Ability to log in via username-password, gauth, or via a dozen different saml providers (https://docs.qubole.com/en/latest/admin-guide/saml-sso.html#using-saml-sso)
- Ability to launch clusters in VPC (https://docs.qubole.com/en/latest/user-guide/clusters/clusters-in-vpcs.html)
- Customize the environment via node bootstraps (https://docs.qubole.com/en/latest/user-guide/clusters/node-bootstrap.html)
In Summary
I’d like to give a big thanks to the Airbnb team, core committers, and my colleague Yogesh.
Airbnb for open sourcing such beautiful software. Even a person like me who had never coded in Python before was able to contribute to the project and customize it.
Core committers: Max, Bolke, Siddharth, and Chris for reviewing a bunch of open-source PR and helping in the integration of Qubole with Airflow.
Yogesh for being involved since the evaluation of Airflow as the preferred choice to doing the GA as a managed service.




